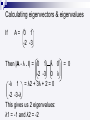Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Clustering Tutorial
Elias Raftopoulos
HY539 29/3/06
Prof. Maria Papadopouli
Roadmap
Math Reminder
Principle Components Analysis
Clustering
ANOVA
Standard Deviation
Statistics – analyzing data sets in terms of the
relationships between the individual points
Standard Deviation is a measure of the spread
of the data
Calculation: average distance from the mean of
the data
Variance
Another measure of the spread of the data in a data set
Calculation:
Var( X ) = E(( x – μ )^2)
Why have both variance and SD to calculate the
spread of data?
Variance is claimed to be the original statistical measure
of spread of data. However it’s unit would be expressed
as a square e.g. cm^2, which is unrealistic to express
heights or other measures. Hence SD as the square root
of variance was born.
Covariance
Variance – measure of the deviation from the mean for
points in one dimension e.g. heights
Covariance as a measure of how much each of the
dimensions vary from the mean with respect to each
other.
Covariance is measured between 2 dimensions to see if
there is a relationship between the 2 dimensions e.g.
number of hours studied & marks obtained
The covariance between one dimension and itself is the
variance
Covariance Matrix
Representing Covariance between dimensions
as a matrix e.g. for 3 dimensions:
cov(x,x) cov(x,y) cov(x,z)
C = cov(y,x) cov(y,y) cov(y,z)
cov(z,x) cov(z,y) cov(z,z)
Diagonal is the variances of x, y and z
cov(x,y) = cov(y,x) hence matrix is symmetrical
about the diagonal
N-dimensional data will result in nxn covariance
matrix
Covariance
Exact value is not as important as it’s sign.
A positive value of covariance indicates both dimensions
increase or decrease together e.g. as the number of
hours studied increases, the marks in that subject
increase.
A negative value indicates while one increases the other
decreases, or vice-versa e.g. active social life at RIT vs
performance in CS dept.
If covariance is zero: the two dimensions are
independent of each other e.g. heights of students vs the
marks obtained in a subject
Transformation matrices
Consider:
2 3
2 1
x
3
2
12
3
=
=4x
8
2
Square transformation matrix transforms (3,2)
from its original location. Now if we were to take
a multiple of (3,2)
6
2 x 3
=
2
4
2 3
6
24
6
x
=
=4x
2 1
4
16
4
Transformation matrices
Scale vector (3,2) by a value 2 to get (6,4)
Multiply by the square transformation matrix
We see the result is still a multiple of 4.
WHY?
A vector consists of both length and direction. Scaling a
vector only changes its length and not its direction. This
is an important observation in the transformation of
matrices leading to formation of eigenvectors and
eigenvalues.
Irrespective of how much we scale (3,2) by, the solution
is always a multiple of 4.
eigenvalue problem
The eigenvalue problem is any problem
having the following form:
A.v=λ.v
A: n x n matrix
v: n x 1 non-zero vector
λ: scalar
Any value of λ for which this equation has
a solution is called the eigenvalue of A and
vector v which corresponds to this value is
called the eigenvector of A.
eigenvalue problem
2 3
3
12
3
x
=
=4x
2 1
2
8
2
A
. v
= λ. v
Therefore, (3,2) is an eigenvector of the square
matrix A and 4 is an eigenvalue of A
Given matrix A, how can we calculate the
eigenvector and eigenvalues for A?
Calculating eigenvectors & eigenvalues
A.v=λ.v
A.v-λ.I.v=0
(A - λ . I ). v = 0
Finding the roots of |A - λ . I| will give the
eigenvalues and for each of these
eigenvalues there will be an eigenvector
Given
Example …
Calculating eigenvectors & eigenvalues
If
A= 0 1
-2 -3
Then |A - λ . I| = 0 1 λ 0
-2 -3 0 λ
-λ 1 = λ2 + 3λ + 2 = 0
-2 -3-λ
This gives us 2 eigenvalues:
λ1 = -1 and λ2 = -2
= 0
Properties of eigenvectors and
eigenvalues
Note that Irrespective of how much we
scale (3,2) by, the solution is always a
multiple of 4.
Eigenvectors can only be found for square
matrices and not every square matrix has
eigenvectors.
Given an n x n matrix, we can find n
eigenvectors
Roadmap
Principle Components Analysis
Clustering
ANOVA
PCA
principal components analysis (PCA) is a
technique that can be used to simplify a dataset
It is a linear transformation that chooses a new
coordinate system for the data set such that
greatest
variance by any projection of the data set
comes to lie on the first axis (then called the first
principal component),
the second greatest variance on the second axis, and
so on.
PCA can be used for reducing dimensionality by
eliminating the later principal components.
PCA
By finding the eigenvalues and eigenvectors of
the covariance matrix, we find that the
eigenvectors with the largest eigenvalues
correspond to the dimensions that have the
strongest correlation in the dataset.
This is the principal component.
PCA is a useful statistical technique that has
found application in:
fields
such as face recognition and image
compression
finding patterns in data of high dimension
PCA process –STEP 1
Subtract the mean
from each of the data dimensions. All the x
values have x subtracted and y values have y
subtracted from them. This produces a data set
whose mean is zero.
Subtracting the mean makes variance and
covariance calculation easier by simplifying their
equations. The variance and co-variance values
are not affected by the mean value.
PCA process –STEP 1
DATA:
x
y
2.5
2.4
0.5
0.7
2.2
2.9
1.9
2.2
3.1
3.0
2.3
2.7
2
1.6
1
1.1
1.5
1.6
1.1
0.9
ZERO MEAN DATA:
x
y
.69
.49
-1.31
-1.21
.39
.99
.09
.29
1.29
1.09
.49
.79
.19
-.31
-.81
-.81
-.31
-.31
-.71
-1.01
PCA process –STEP 1
PCA process –STEP 2
Calculate the covariance matrix
cov = .616555556 .615444444
.615444444 .716555556
since the non-diagonal elements in this
covariance matrix are positive, we should
expect that both the x and y variable
increase together.
PCA process –STEP 3
Calculate the eigenvectors and
eigenvalues of the covariance matrix
eigenvalues = .0490833989
1.28402771
eigenvectors = -.735178656 -.677873399
.677873399 -.735178656
PCA process –STEP 3
•eigenvectors are plotted
as diagonal dotted lines
on the plot.
•Note they are
perpendicular to each
other.
•Note one of the
eigenvectors goes through
the middle of the points,
like drawing a line of best
fit.
•The second eigenvector
gives us the other, less
important, pattern in the
data, that all the points
follow the main line, but
are off to the side of the
main line by some
amount.
PCA process –STEP 4
Reduce dimensionality and form feature vector the
eigenvector with the highest eigenvalue is the principle
component of the data set.
In our example, the eigenvector with the larges
eigenvalue was the one that pointed down the middle of
the data.
Once eigenvectors are found from the covariance matrix,
the next step is to order them by eigenvalue, highest to
lowest. This gives you the components in order of
significance.
PCA process –STEP 4
Now, if you like, you can decide to ignore
the components of lesser significance
You do lose some information, but if the
eigenvalues are small, you don’t lose
much
n dimensions in your data
calculate n eigenvectors and eigenvalues
choose only the first p eigenvectors
final data set has only p dimensions.
PCA process –STEP 4
Feature Vector
FeatureVector = (eig1 eig2 eig3 … eign)
We can either form a feature vector with both of
the eigenvectors:
-.677873399 -.735178656
-.735178656 .677873399
or, we can choose to leave out the smaller, less
significant component and only have a single
column:
- .677873399
- .735178656
PCA process –STEP 5
Deriving the new data
FinalData = RowFeatureVector x RowZeroMeanData
RowFeatureVector is the matrix with the eigenvectors in
the columns transposed so that the eigenvectors are
now in the rows, with the most significant eigenvector at
the top
RowZeroMeanData is the mean-adjusted data
transposed, ie. the data items are in each column, with
each row holding a separate dimension.
PCA process –STEP 5
R
=
S
U
factors
variables
factors
samples
noise
significant
sig.
samples
VT
variables
significant
noise
factors
noise
factors
PCA process –STEP 5
FinalData is the final data set, with data items in
columns, and dimensions along rows.
What will this give us?
It
will give us the original data solely in terms of the
vectors we chose.
We have changed our data from being in terms
of the axes x and y , and now they are in terms
of our 2 eigenvectors.
PCA process –STEP 5
FinalData transpose:
dimensions along columns
x
y
-.827970186
-.175115307
1.77758033
.142857227
-.992197494
.384374989
-.274210416
.130417207
-1.67580142
-.209498461
-.912949103
.175282444
.0991094375
-.349824698
1.14457216
.0464172582
.438046137
.0177646297
1.22382056
-.162675287
PCA process –STEP 5
Reconstruction of original Data
If we reduced the dimensionality, obviously,
when reconstructing the data we would lose
those dimensions we chose to discard. In our
example let us assume that we considered only
the x dimension…
Reconstruction of original Data
x
-.827970186
1.77758033
-.992197494
-.274210416
-1.67580142
-.912949103
.0991094375
1.14457216
.438046137
1.22382056
Roadmap
Principle Components Analysis
Clustering
ANOVA
What is Cluster Analysis?
Cluster: a collection of data objects
Similar to the objects in the same cluster (Intraclass similarity)
Dissimilar to the objects in other clusters (Interclass dissimilarity)
Cluster analysis
Statistical method for grouping a set of data objects into clusters
A good clustering method produces high quality clusters with high
intraclass similarity and low interclass similarity
Clustering is unsupervised classification
Can be a stand-alone tool or as a preprocessing step for
other algorithms
Group objects according to their similarity
Cluster:
a set of objects
that are similar
to each other
and separated
from the other
objects.
Example: green/
red data points
were generated
from two different
normal distributions
Clustering data
object expression data matrix
Experiments/samples
are given as the row and
column vectors of an
expression data matrix
Clustering may be
applied either to objects
experiments (regarded
as vectors in Ro or Rn).
n experiments
o objects
Pattern matrix Proximity matrix
Pattern
matrix (nxp)
p=attributes
n=#
of objects
Proximity
matrix (nxn)
d(i,j)=difference/
x11
...
x
i1
...
x
n1
...
x1f
...
...
...
...
xif
...
...
...
...
... xnf
...
...
0
d(2,1)
0
d(3,1) d ( 3,2) 0
:
:
:
d ( n,1) d ( n,2) ...
dissimilarity between i and j
x1p
...
xip
...
xnp
... 0
Proximity matrix
Clustering methods require that a index of
proximity, or alikeness, or affinity or association
be established between pairs of patterns
A proximity index is either a similarity or a
dissimilarity
The crucial problem in identifying clusters in
data is to specify what proximity is and how to
measure it
Proximity indices
A proximity index between the ith and kth
patterns is denoted d(i,k) and must satisfy
the following three properties:
1. (a) for a dissimilarity: d(i,i) = 0, all i
(b) for a similarity: d(i,i) ≥ max d(i,k), all I
2. d(i,k) = d(k,i), all (i,k)
3. d(i,k) ≥ 0, all (i,k)
Different proximity measures
r = 2(Euclidean distance)
[42 + 22]1/2 = 4.472
r = 1(Manhattan distance)
4+2=6
r → ∞ (“sup” distance)
max{4,2} = 4
K-Means Clustering
The meaning of ‘K-means’
Why
it is called ‘K-means’ clustering: K points
are used to represent the clustering result;
each point corresponds to the centre (mean)
of a cluster
Each point is assigned to the cluster with
the closest center point
The number K, must be specified
Basic algorithm
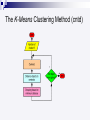
The K-Means Clustering Method
Given k, the k-means algorithm is implemented
in 4 steps:
Partition
objects into k non-empty subsets
Arbitrarily choose k points as initial centers
Assign each object to the cluster with the nearest
seed point (center)
Calculate the mean of the cluster and update the
seed point
Go back to Step 3, stop when no more new
assignment
The K-Means Clustering Method (cntd)
The basic step of k-means clustering is
simple:
Iterate
until stable (= no object move group):
Determine the centroid coordinate
Determine the distance of each object to the
centroids
Group the object based on minimum distance
The K-Means Clustering Method (cntd)
The K-Means Clustering Results
Example
10
10
9
9
8
8
7
7
6
6
5
5
10
9
8
7
6
5
4
4
3
2
1
0
0
1
2
3
4
5
6
7
8
K=2
Arbitrarily choose K
object as initial
cluster center
9
10
Assign
each
objects
to most
similar
center
3
2
1
0
0
1
2
3
4
5
6
7
8
9
10
Update
the
cluster
means
4
3
2
1
0
0
1
2
3
4
5
6
reassign
10
9
9
8
8
7
7
6
6
5
5
4
3
2
1
0
1
2
3
4
5
6
7
8
8
9
10
reassign
10
0
7
9
10
Update
the
cluster
means
4
3
2
1
0
0
1
2
3
4
5
6
7
8
9
10
Weaknesses of the K-Means Method
Unable to handle noisy data and outliers
Very large or very small values could skew
the mean
Not suitable to discover clusters with nonconvex shapes
Hierarchical Clustering
Start with every data point in a separate
cluster
Keep merging the most similar pairs of
data points/clusters until we have one
big cluster left
This is called a bottom-up or
agglomerative method
Hierarchical Clustering (cont.)
This produces a
binary tree or
dendrogram
The final cluster is the
root and each data
item is a leaf
The height of the bars
indicate how close
the items are
Hierarchical Clustering Demo
Levels of Clustering
Linkage in Hierarchical Clustering
We already know about distance measures
between data items, but what about between
a data item and a cluster or between two
clusters?
We just treat a data point as a cluster with a
single item, so our only problem is to define a
linkage method between clusters
As usual, there are lots of choices…
Average Linkage
Definition
Each cluster ci is associated with a mean vector i
which is the mean of all the data items in the
cluster
The distance between two clusters ci and cj is
then just d(i , j )
This is somewhat non-standard – this method is
usually referred to as centroid linkage and average
linkage is defined as the average of all pairwise
distances between points in the two clusters
Single Linkage
The minimum of all pairwise distances
between points in the two clusters
Tends to produce long, “loose” clusters
Complete Linkage
The maximum of all pairwise distances
between points in the two clusters
Tends to produce very tight clusters
Distances between clusters (summary)
Calculation of the distance
between two clusters is based on
the pairwise distances between
members of the clusters.
Complete linkage: largest distance
between points
Average linkage: average distance
between points
Single linkage: smallest distance
between points
Centroid: distance between
centroids
Complete linkage gives preference to compact/spherical
clusters. Single linkage can produce long stretched clusters.
EXAMPLE
A B C D E
A 0 1 2 2 3
B 1 0 2 4 3
C 2 2 0 1 5
D 2 4 1 0 3
E 3 3 5 3 0
More on Hierarchical Clustering Methods
Major advantage
Conceptually
very simple
Easy to implement most commonly used technique
Major weakness of agglomerative clustering
methods
do
not scale well: time complexity of at least O(n2),
where n is the number of total objects
can never undo what was done previously high
likelihood of getting stuck in local minima
Roadmap
Principle Components Analysis
Clustering
ANOVA
(M)ANOVA
The analysis of variance technique in One-Way
Analysis of Variance (ANOVA) takes a set of
grouped data and determine whether the mean
of a variable differs significantly between groups
Often there are multiple variables and you are
interested in determining whether the entire set
of means is different from one group to the next
There
is a multivariate version of analysis of variance
that can address that problem (MANOVA)