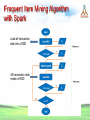
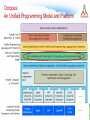
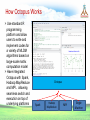
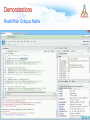
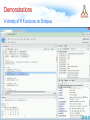
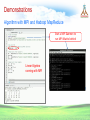
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
A Unified Programming Model and Platform for Big Data Machine Learning & Data Mining Yihua Huang, Ph.D., Professor Email:[email protected] NJU-PASA Lab for Big Data Processing Department of Computer Science and Technology Nanjing University May 29, 2015, India PASA Big Data Lab at Nanjing University Our lab studies on Parallel Algorithms Systems, and Applications for Big Data Processing We are the earliest big data lab in China, entering big data research area since 2009 Now we are contributor of Apache Spark and Tachyon Parallel Computing Models and Frameworks & Hadoop/Spark Performance Optimization Hadoop job and resource scheduling optimization Spark RDD persisting optimization Big Data Storage and Query Tachyon Optimization Performance Benchmarking Tools for Tachyon and DFS HBase Secondary Indexing (HBase+In-memory) and query system Large-Scale Semantic Data Storage and Query Large-scale RDF semantic data storage and query system(HBase+In-memory) RDFS/OWL semantic reasoning engines on Hadoop and Spark Machine Learning Algorithms and Systems for Big Data Analytics Parallel MLDM algorithm design with diversified parallel computing platforms Unified programming model and platform for MLDM algorithm design Contents Part 1. Parallel Algorithm Design for Machine Learning and Data Mining Part2. Unified Programming Model and Platform for Big Data Analytics Part1. Parallel Algorithm Design for Machine Learning and Data Mining A variety of Big Data parallel computing platforms (Hadoop, Spark, MPI, etc.) emerging… Serial machine learning algorithms not able to finish computation upon large-scale dataset in acceptable time Do not fit any of existing parallel computing platforms and thus need to rewrite them in parallel upon different parallel computing platforms Our lab has entered into Big Data area since 2009, starting from writing a variety of parallel Machine Learning algorithms on Hadoop, Spark, etc. • Frequent Itemset Mining is one of the most important and often used algorithm for data mining • Apriori algorithm is the most established algorithm for finding frequent itemset from a transactional dataset Tao Xiao, Shuai Wang, Chunfeng Yuan, Yihua Huang. PSON: A Parallelized SON Algorithm with MapReduce for Mining Frequent Sets. The Fourth International Symposium on Parallel Architectures, Algorithms and Programming, PAAP 2011, p 252-257, 2011 Hongjian Qiu, Rong Gu, Chunfeng Yuan and Yihua Huang. YAFIM: A Parallel Frequent Itemset Mining Algorithm with Spark. The 3rd International Workshop on Parallel and Distributed Computing for Large Scale Machine Learning and Big Data Analytics, conjunction with IPDPS 2014, May 23, 2014. Phoenix, USA Suppose I is an itemset consisting of items from the transaction database D Let N be the number of transactions D Let M be the number of transactions that contain all the items of I M /N is referred to as the support of I in D Example Here, N = 4, let I = {I1, I2}, than M = 2 because I = {I1, I2} is contained in transactions T100 and T400 so the support of I is 0.5 (2/4 = 0.5) If sup(I) is no less that an user-defined threshold, then I is referred to as a frequent itemset Goal of frequent sets mining To find all frequent k-itemsets from a transaction database (k = 1, 2, 3, ....) Apriori algorithm • A classic frequent sets mining algorithm • Needs multiple passes over the database • In the first pass, all frequent 1-itemsets are discovered • In each subsequent pass, frequent (k+1)-itemsets are discovered, with the frequent k- itemsets found in the previous pass as the seed (referred to as candidate itemsets) • Repeat until no more frequent itemsets can be found • Apriori Algorithm [1]: [1] Rakesh Agrawal, Ramakrishnan Srikant: Fast Algorithms for Mining Association Rules in Large Databases. VLDB 1994: 487-499 • The FIM process is both data-intensive and computing-intensive. – transactional dataset is become larger and larger – Iteratively trying all combinations from 1-itemset to k-itemset is time-consuming – FIM needs to scan the datasets iteratively for many times. Apriori in MapReduce: Experimental results PSON achieves great speedup compared to SON algorithm • Parallel Aprioir algorithm with MapReduce needs to run the MapReduce job iteratively • It need to scan the dataset iteratively and store all the intermediate data in HDFS • As a result, the parallel Apriori algorithm with MapReduce is not efficient enough • YAFIM, Apriori algorithm implemented in Spark Model, can gain about 18x speedup in our experiments • Our YAFIM contains two phases to find all frequent itemsets – Phase Ⅰ: Load transaction datasets as a Spark RDD object and generate 1-frequent itemsets; – Phase Ⅱ: Iteratively generate (k+1)-frequent itemset from k-frequent itemset. Load all transaction data into a RDD All transaction data reside in RDD Phase Ⅰ Phase ⅠI • Methods to speedup performance – In-memory computing with RDDs. We make full use of RDDs and complete total computing in memory – Share data with Broadcast. We adopt broadcast variables abstraction in the Spark to reduce data transformation in tasks • We ran experiments with both programs on four benchmarks [3] with different characteristics: – – – – MushRoom T10I4D100K Chess Pumsb_star Achieving about 18x speedup with Spark compared to the algorithm with MapReduce We also apply our YAFIM in medical text semantic analysis application and achieve 25x speedup. Medicine text semantic analysis 40000 35000 Execution Time 30000 25000 20000 YAFIM MApriori 15000 10000 5000 0 1 2 3 4 Passes of Iteration 5 6 Basic Algorithm Input: A dataset of N data points that need to be clustered into K clusters Output:K clusters Choose k cluster center Centers[K] as initial cluster centers Loop: for each data point P from dataset: { Calculate the distance between P and each of Centers[i] ; Save p to the nearest cluster center } Recalculate the new Centers[K] Go loop until cluster centers converge Pseudo codes for MapReduce class Mapper setup(…) { read k cluster centers Centers[K]; } map(key, p) // p is a data point { minDis = Double.MAX VALUE; index = -1; for i=0 to Centers.length { dis= ComputeDist(p, Centers[i]); if dis < minDis { minDis = dis; index = i; } } emit(Centers[i].ClusterID, (p,1)); } Pseudo codes for MapReduce To optimize the data I/O and network transfer, we can use Combiner to reduce the number of key-value pairs from a Map node class Combiner reduce(ClusterID, [(p1,1), (p2,1), …]) { pm = 0.0; n = 数据点列表[(p1,1), (p2,1), …]中数据点的总个数; for i=0 to n pm += p[i]; pm = pm / n; // Calculate the average of points in the Cluster emit(ClusterID, (pm, n)); // use it as new Center } Pseudo codes for MapReduce class Reducer reduce(ClusterID, valueList = [(pm1,n1),(pm2,n2) …]) { pm = 0.0; n=0; k = length of valuelist belonging to a ClusterID; for i=0 to k { pm += pm[i]*n[i]; n+= n[i]; } pm = pm / n; // calculate new center of the Cluster emit(ClusterID, (pm,n)); // output new center of the Cluster } In main() function of the MapReduce Job, set a loop to run the MapReduce job until converge Scala codes while(tempDist > convergeDist && tempIter < MaxIter) { var closest = data.map ( p => (closestPoint(p, kPoints), (p, 1))) // determine nearest center for each P // calculate the average of all points in a cluster as new center var pointStats = closest.reduceByKey{case ((x1, y1), (x2, y2)) => (x1 + x2, y1 + y2)} var newPoints = pointStats.map {pair => (pair._1, pair._2._1 / pair._2._2)}.collectAsMap() tempDist = 0.0 for (i <- 0 until K) // calculate tempDist to determine if converges tempDist += kPoints(i).squaredDist(newPoints(i)) // calculate tempDist to determine if converges for (newP <- newPoints) kPoints(newP._1) = newP._2 // update new centers tempIter=tempIter+1 } Execution time(s) Spark speedup about 4-5 times compared to MapReduce Number of Nodes 1st iteration next iteration Peng Liu, Jiayu Teng, Yihua Huang. Study of k-means algorithm parallelization performance based on spark. CCF Big Data 2014 Basic Idea Given m classes from training dataset: { C1,C2, …, Cm } Predict which class a testing sample X will belong to. cmap arg max P Ci |X 1 i m Ci C P Ci |X P X |Ci P Ci P X => Only need to calculate Suppose xk is independent to each other => P X |Ci Thus, we can count from training samples to get both P X |Ci P Ci n k 1 P( xk | Ci ) P X |Ci P Ci Training Map Pseudo Code to calculate P(X|Ci) and P(Ci) class Mapper map(key, tr) // tr is a training sample { tr trid, X, Ci emit(Ci, 1) for j=0 to X.lenghth) { X[j] xnj & xvj // xnj: name if xj, xvj: value of xj emit(<Ci, xnj, xvj>, 1) } } Training Reduce Pseudo Code to calculate P(xj|Ci) and P(Ci) class Reducer reduce(key, value_list) // key: either Ci or <Ci, xnj, xvj> { sum =0; // count for P(xj|Ci) and P(Ci) while(value_list.hasNext()) sum += value_list.next().get(); emit(key, sum) } // Trim and save output as P(xj|Ci) and P(Ci) tables in HDFS Predict Map Pseudo Code to Predict Test Sample class Mapper setup(…) { load P(xj|Ci) and P(Ci) data from training stage FC = { (Ci, P(Ci)) }, FxC = { (<Ci, xnj, xvj>, P(xj|Ci)) } } map(key, ts) // ts is a test sample { ts tsid, X MaxF = MIN_VALUE; idx = -1; for (i=0 to FC.length) { FXCi = 1.0;Ci = FC[i].Ci; FCi = FC[i].P(Ci) for (j=0 to X.length) { xnj = X[j].xnj; xvj = X[j].xvj Use <Ci, xnj, xvj> to scan FxC, get P(xj|Ci) FXCi = FXCYi * P(xj|Ci); } if(FXCi* FCi >MaxF) { MaxF = FXCi*FCi; idx = i; } } emit(tsid, FC[idx].Ci) } Training SparkR Code to calculate P(xj|Ci) and P(Ci) parseVector <- function(line) { # mapping line to list(Ci, list(1, features)) } sc <- sparkR.init(master, “NaiveBayes”) # init Spark file <- textFile(sc, dataFile) # read training text data file => RDD lines <- lapply(file, parseVector) # do map # sum up to count the number of Ci and xj aggre <- reduceByKey(lines, function(p1, p2) { list(p1[[1]] + p2[[1]], p1[[2]] + p2[[2]]) }, 2L) cltaggr <- collect(aggre) C <- length(cltaggr) # localize dataset # Total number of Classes Calculate total number of each Ci from cltaggr lapply(cltaggr, function(p) { # calculate and save P(xj|Ci) and P(Ci) }) Predict SparkR Code predict <- function(d) { dataMatrix <- as.matrix(d) result <- P(Ci) + P(xj|Ci) %*% dataMatrix # return max one which.max(result) – 1 # Ci starts from 0 predictRDD <- function(data) {map(data, predict) } tFile <- textFile(sc, dataFile) testData <- map(tFile, function(p){as.double(strsplit(p, " ")[[1]])}) Classlabel <- collect(predictRDD(testData)) Save predicted Class label to file TrainingDataset (thousand) Hadoop SparkR Speedup 250 35 s 13 s 2.69 500 40 s 14 s 2.85 1000 49 s 16 s 3.06 2000 66 s 18 s 3.67 SVM and Logistic Regression with MapReduce and SparkR Iteration Hadoop SparkR (no cache) SparkR (cache) Speedup 10 374 s 103 s 43 s 8.7 20 720 s 183 s 68 s 10.6 30 1065s 274 s 94 s 11.3 Zhiqiang Liu, Rong Gu, Yihua Huang. The Parallelization of Classification Algorithms Based on SparkR. CCF Big Data 2014, Beijing Large Scale Deep Learning on Intel Xeon Phi Manycore Coprocessor with OpenMP 60 cores 30 cores BaseLine 16024s 15960s OpenMP 892s 2122s OpenMP+MKL 97s 120s Improved OpenMP+MKL 53s 81s Speedup (fullyoptimized compared with baseline) 302 197 Lei Jin, Rong Gu, Chunfeng Yuan and Yihua Huang. Large Scale Deep Learning On Xeon Phi Many-core Coprocessor. The 3rd International Workshop on Parallel and Distributed Computing for Large Scale Machine Learning and Big Data Analytics, conjunction with IPDPS 2014, May 23, 2014. Phoenix, USA Large Scale Learning to Rank based on Gradient Boosting Decision Tree(GBDT) with MPI Research Grant from Baidu Large Scale Learning to Rank based on Gradient Boosting Decision Tree(GBDT) with MPI Implemented parallel algorithm with MPI achieves 1.5 speedup compared with existing GBDT algorithm from Baidu Customized Light-weighted Parallel Computing Platform for Large Scale Neural Network Training Rong Gu, Furao Shen, and Yihua Huang. A Parallel Computing Platform for Training Large Scale Neural Networks. Proceedings of the IEEE International Conference on Big Data (IEEE BigData 2013), pp. 376 384, Santa Clara, CA, USA, Oct. 6-9, 2013 Existing parallel computing platforms provide useful means for Big Data machine learning and data analytics. However, they are not easy to learn and use for data analysts When choosing to use different parallel computing platform, we need to rewrite all machine learning algorithms. This is a lot of burden even for professional parallel programmers As a result, we need to find out an easy-to-use and unified programming model and platform for Big Data machine learning and data analytics Part 2 Unified Programming Model and Platform for Big Data Analytics Motivation Big Data Processing Platforms From NA to Available From Slow to Fast From Not Easy to Use To Easy to Use Motivation Modeling with Matrix Data Analysts Analytic Tools a11 a12 ... a21 a22 ... ... [ a1, a2, a3, a4, ...] A Big Gap! Big Data Processing Platforms and Programming Models MPI、Fortran/C++ ScaLAPACK; GPU CUDA、BIDMach; Scala、Spark RDD; Hadoop MR; Motivation Problem for data analysts: A big gap between data analysts and parallel computing platforms …… MPI Spark MapReduce Motivation What we do for this? We provide a unified programming model and platform to bridge the gap between data analysts and parallel computing platforms Unified & easy-to-use Programming …… MPI Spark MapReduce Motivation Problem for professional parallel programmers: A number of parallel computing platforms multiplies several dozens of machine learning algorithms generate a lot of duplicated work and burden to rewrite all algorithms across different platforms …… MPI Spark MapReduce Hundred of ML Algorithms Lots of duplicated work & burden to rewrite all ML algorithms Motivation What we do for this? We provide a unified programming model and platform for parallel programmers to write their MLDM algorithms once but run anywhere! …… MPI Spark MapReduce Hundred of ML Algorithms Lots of duplicated work & burden to rewrite all ML algorithms Octopus: An Unified Programming Model and Platform Basic Idea • Most of machine learning & data mining(MLDM) algorithm can be represented as the Matrix computation, thus we adopt matrix as an unified abstraction to represent a variety of MLDM algorithms • Provide a high-level MLDA programming model based on Matrix • Provide an unified programming language and software framework for MLDM programming • Implement plug-ins for each of underlying parallel computing platforms, mapping the high-level MLDM programs with matrix computation to underlying platforms • Implement and provide optimized computation for large-scale matrix operations for each of underlying platforms to speedup the computation and improve performance Octopus: An Unified Programming Model and Platform • We initiate a research project, Octopus, to develop a crossplatform and unified MLDM programming model, framework and platform • A high-level and unified programming model and platform for big data analytics and mining • Allowing data analysts and big data application programmers to easily design and implement machine learning and data mining algorithms for big data analytics • Transparently work on top of various distributed computing frameworks Octopus: An Unified Programming Model and Platform • Design and implement distributed matrix computation packages with Spark, MapReduce and MPI • Adopt R as the unified programming language for data analysts and parallel programmers to use • Design and implement whole framework to transparently run matrixbased MLDM algorithms on top of Spark, MapReduce and MPI, without need to modify codes • Design and provide parallel MLDM algorithm library … … Octopus: An Unified Programming Model and Platform Architectural Overview Demo Applications LR, SVM, Deep Learning, Other ML Algorithms OctMatrix (An R package and APIs for distributed matrix operations) Matrix Execution Connection Model for Optimization Module Underlying Matrix Lib SparkMatrix MR-Matrix MPI-Matrix R-Matrix (Marlin) Spark MapReduce MPI Single Node-R Matrix Data Representation and Storage Tachyon HDFS Developed by us Open Source OctMatrix: Distributed Matrix Computation Lib > OctMatrix is an R package to provide APIs for high-level and platform-independent distributed matrix operations, allowing Matrix Lib to be called from R language > OctMatrix APIs ranging from * Loading and managing large-scale matrix data * Calling Matrix Lib for large scale matrix computation with automated partitioning into sub-matrix and scheduling for distributed execution * Calling R-Matrix lib for small size matrix that can be executed on a single machine. OctMatrix: Distributed Matrix Computation Lib Code Structure and API of OctMatrix Methods: Exposed Methods: initialization(); //支持从(local,HDFS,Tachyon)文件、二维数组 初始化;支持特殊矩阵初始化(zeros,ones) // initializations of matrix from local, HDFS, Tachyon, two-dim Array, and also special matrix matrixOperations(); implement // 支持各种矩阵函数,如分解、转置、求和等; // provide matrix operations including decompression, transformation, sum, etc. enableNativeTachyon(); getSubMatrix(); getRow(); getElement(); … MR_MatRef MPI_MatRef //支持矩阵运算的操作符,如各种类型的加、 减、乘、除; // provide matrix operators including Add, Sub, Mul, Div of matrices Methods: //支持从(local,HDFS,Tachyon)文 件、R矩阵、R向量初始化;支持 特殊矩阵初始化(zeros,ones) // initializations of matrix from local, HDFS, Tachyon, two-dim Array, and also special matrix matrixOperations(); matrixOperator(); apply(); saveToTachyon(); toArray (); sample(); delete(); … initialization(); Spark_MatRef OctMatrix R_MatRef implement NativeTachyon _Ref Support_ NativeTachyon Mat_Type Storage_ Location //支持各种矩阵函数,如分解、转 置、求和等; // provide matrix operations including decompression, transformation, sum, etc. matrixOperator(); //支持矩阵运算的操作符,如各种 类型的加、减、乘、除; // provide matrix operators including Add, Sub, Mul, Div of matrices apply(); toLocalRMatrix(); sample(); dim(); getRow(); getElement(); getSubMatrix(); delete(); … OctMatrix: Distributed Matrix Computation Lib OctMatrix APIs provided to Users • Matrix Initialization/Exportation – – – – – • Matrix Operators – – – – • initialize OctMatrix from Local File System/HDFS/Tachyon save OctMatrix from/to Local File System/HDFS/Tachyon convert OctMatrix from/to native R matrix; construct special matrix,API: ones,zeros … elemwise/numeric matrix multiply,add,minus,division (API: *,+,-,/) matrix multiply (API: %*%) bind x and y via columns (API: cbind2) … Matrix Operations – – – – – – – get the rows and cols of matrix, API: dim ; the inv of a OctMatrix, API: inv ; statistical functions, API: max, min, mean, sum ; matrix transposition, API: t ; matrix decomposition, API: lu, svd, etc. apply a function to matrix, API: apply(OctMatrix, MARGIN, FUN) ; functions contained in R matrix, such as rep,split. – – get sub-matrix; … OctMatrix: Distributed Matrix Computation Lib Partitioning and Parallel Execution of Distributed Matrix Automated Large Scale Matrix Partition and Optimized Execution Schedule and Dispatch Spark Cluster Server Nodes OctMatrix: Distributed Matrix Computation Lib Optimized Distributed Matrix Multiplication Three types of Matrix Representations Local Matrix: a proper-sized matrix that can be stored and computed at local machine Broadcast Matrix: a small-sized matrix that can be broadcasted to each machine node Distributed Matrix: a large-sized matrix that needs to be partitioned and stored in distributed machine nodes Distributed Matrix is further divided Into two types: Row Matrix Block Matrix . OctMatrix: Distributed Matrix Computation Lib Optimized Distributed Matrix Multiplication Execution Strategies Define the following optimized execution strategies for matrix multiplication: OctMatrix: Distributed Matrix Computation Lib Marlin: Optimized Distributed Matrix Multiplication with Spark OctMatrix: Distributed Matrix Computation Lib Optimized Distributed Matrix Multiplication > For large-scale matrix multiplication, how to partition matrix is very critical for the computation performance > We developed an automatic matrix partitioning and optimized execution algorithm in terms of the shapes and sizes of matrices and then schedule them for execution in parallel HAMA Blocking CARMA Blocking Broadcasting OctMatrix: Distributed Matrix Computation Lib Marlin: Optimized Distributed Matrix Multiplication with Spark Multiply big and small matrices Multiply two big matrices OctMatrix: Distributed Matrix Computation Lib Marlin: Optimized Distributed Matrix Multiplication with Spark OctMatrix: Distributed Matrix Computation Lib Marlin: Optimized Distributed Matrix Multiplication with Spark 4~5x Speedup Compared to SparkR OctMatrix: Distributed Matrix Computation Lib Marlin: Optimized Distributed Matrix Multiplication with Spark Matrix Multiply , 96 partitions, executor memory 10GB, except that case 3_5 is 20GB OctMatrix Data Representation and Storage > Matrix data can be stored in local file, \Octopus_HOME HDFS, and Tachyon, allowing to \user-sesscion-id1\ \matrix-a read from and write to these file info systems from R programs row_index > Matrix data is organized and stored \row-data in terms of certain structure par1.data … parN.data col_index \col-data par1.data … parN.data \matrix-b \matrix-c \user-sesscion-id2\ … \user-sesscion-id3\ … Machine Learning Lib built with OctMatrix • Classification and regression – Linear Regression – Logistic Regression – Softmax – Linear Support Vector Machine (SVM) • Clustering – K-Means • Feature extraction – Deep Neural Network(Auto Encoder) • More MLDM algorithms to come How Octopus Works > Use standard R programming platform and allow users to write and implement codes for a variety of MLDM algorithms based on large-scale matrix computation model > Have integrated Octopus with Spark, Hadoop MapReduce and MPI,allowing seamless switch and execution on top of underlying platforms Octopus Spark Hadoop MapReduce MPI Single Machine Octopus Features Summary • Ease-to-use/High-level User APIs – high-level matrix operators and operations APIs. – similar to that of the Matrix/Vector operation APIs in the standard R language. – does not require the low-level knowledge for the distributed system knowledge or programming skills. • Write Once, Run Anywhere – programs written with Octopus can transparently run on top of different computing engines such as Spark, Hadoop MapReduce, or MPI. – using OctMatrix APIs with small data running on a single-machine R engine for test and run the program on large scale data without modifying the codes. – support a number of I/O sources including Tachyon, HDFS, and local file systems. Octopus Features Summary • Distributed R apply Functions – offers the apply() function on OctMatrix. The parameter function will be executed on each element/row/column of the OctMatrix on the cluster in parallel. – parameter functions passed to apply() can be any R functions including the UDFs. • Machine Learning Algorithm Library – Implemented a bunch of scalable machine learning algorithms and demo applications built on top of OctMatrix. • Seamless Integration with R Ecosystem – offers its features in a R package called OctMatrix. – naturally takes advantage of the rich resources of the R ecosystem Demonstrations Read/Write Octopus Matrix Demonstrations A Variety of R Functions on Octopus Demonstrations Logistic Regression Training Testing Predicting Change “enginetype” will be able to quickly switch to and run on top of one of underlying platforms without need to modify any other codes Demonstrations K-Means Algorithm Testing Demonstrations Linear Regression Algorithm Testing Demonstrations Code Style Comparison between R and Octopus LR Codes with Standard R LR Codes with Octopus Demonstrations Code Style Comparison between R and Octopus K-Means Codes with Standard R K-Means Codes with Octopus Demonstrations Algorithm with MPI and Hadoop MapReduce Start a MPI Daemon to run MPI-Matrix behind Linear Algebra running with MPI Demonstrations Algorithm with MPI and Hadoop MapReduce Linear Algebra running with Hadoop MapReduce Octopus Project Website and Documents http://pasa-bigdata.nju.edu.cn/octopus/ Project Team Yihua Huang, Rong Gu, Zhaokang Wang, Yun Tang, Haipeng Zhan Contact Information Dr.Yihua Huang, Professor NJU-PASA Big Data Lab http://pasa-bigdata.nju.edu.cn Department of Computer Science and Technology Nanjing University, Nanjing, P.R.China Email:[email protected]