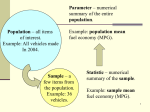
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
G. Carpenter wrote on October 29, 2010: -------------------------------------------------Interpreting Standard Deviation Recently there has been a thread about ascribing an interpretation to s. The recent context has been with respect to the s sub e, the sample standard deviation of the residuals in a regression context. Various statements have been given along the lines of s sub e represents the "typical" or "average" or "rough average" deviation of the actual y variable from data point compared to its predicted value, y hat Other interpretations call s sub e an "expected" deviation, which to my mind connotes an expectation value or mean value for a deviation. A second level of interpretation wants to ascribe a certain % (say majority for example) of data points falling within plus or minus one s sub e of the LSRL. I may be way off base here, but aren’t the residuals like any other set of data? In other words, unless you know the underlying distribution, we will be very limited in what we can say about s sub e. We know any sample standard deviation is SQRT((1/n-1)*Sum (x –xbar)^2) . Let’s apply this to a data set of the residuals. I believe we need to divide by n – 2, instead of n -1 to get an unbiased estimate. I also believe it turns out that the mean of the residuals is zero. [BTW, is that an expected factoid for AP Stat?] So xbar in this case is zero. So s sub e is SQRT((1/n-2)*Sum (residual )^2). If you allow me to be “loose” with n and n – 2 (essentially equating the two for large enough n), then a valid interpretation of s sub e would seem to be that it represents “the square root of the approximate average of the squared distances (y – y hat) from the regression line.” No more, no less. -------------------------------------------------One could think of it like this: Suppose you have some explanatory variable called x and some response variable called y. You fix the explanatory variables in advance: (let's say for example that they are x1, x2, x3, x4, x5, x6, x7, x8, x9, 10), and then you measure the response variables (y1, y2, y3,y4, y5, y6, y7, y8, y9, y10) for each x-value. Then you find the regression line, and there will be some residuals. You could keep on doing this multiple times, and you will get different residuals each time. If we were to do this 100 times we would get 1000 different residuals. And we could make a histogram of the residuals. If the residuals are normally distributed then our histogram should have a bell shape. At any rate, the residuals are the output of a random process, and we can talk about what is the probability that a residual will take on a certain value or a certain range of values. We can talk about the expected value of that random variable and the variance. It turns out that sum( (yi - yhat)^2 ) / (n - 2) is an unbiased estimator for the variance (sigma^2) of that distribution. So that means: E[ S^2 ] = E[ sum( (yi - yhat)^2 ) / (n - 2) ] = sigma^2 This is stated in my book by Jay Devore (Probability and Statistics for Engineering and the Sciences, under the box which describes error sum of squares, section 12.2, page 503 of the 5th edition of the book) Devore writes that the sqrt( sum( yi - yhat)^2 / (n - 2) ) is not an unbiased estimator for sigma in the residual case, and sqrt( sum ( xi - xbar)^2 / (n-1) ) is not an unbiased estimator for sigma in the case of a just estimating the regular standard deviation for a single set of data. (Devore writes that the bias is small unless n is quite small for the regular standard deviation (this is in section 6.1 of the same book)). Both are unbiased estimators for sigma^2. G. Carpenter wrote on October 29, 2010: -------------------------------------------------Mathematically, this is not the mean (nor typical nor average nor expected value of the) deviation in the y from the predicted value given by the LSRL. If the latter interpretation were true, we would simply take absolute values, not the square root of sum of squares, as a measure of spread. The squaring operation makes it a weighted average; points farther away from the LSRL count for more. -------------------------------------------------It is an unbiased estimator for the variance but I don't think it is an unbiased estimator for: E[ abs( X - mu ) ] although one would expect: sqrt( E[ (X - mu)^2 ] ) and E[ abs(X - mu) ] to be generally speaking fairly close. The reason that sum of squares are used instead of absolute value is that with squares you can differentiate, and then optimize while for absolute value you have a discontinuity. They mention that at the beginning of this article: http://mathworld.wolfram.com/LeastSquaresFitting.html G. Carpenter wrote on October 29, 2010: -------------------------------------------------Second, let me address trying to ascribe a % to within plus or minus s. My point is that without knowing the underlying distribution of the residuals, we can’t say much about % within plus or minus s. Indeed, the only way I would know to do this would be to count them up one-by-one and compute what % were within plus or minus s. I am not aware of any theorem that says a majority of the residuals are within plus or minus one s for a LSRL context. Someone show me the error of my ways. What seems applicable, however, is Chebyshev’s Inequality, which says the percent of observations falling within k standard deviations of the mean is at least 100*(1-1/k^2), regardless of the underlying distribution. With k = 1, we have the essentially meaningless statement that at least 0% of the y values of the data fall within plus or minus one s of the predicted values. But, we have a somewhat more meaningful statement when k = 2, namely that at least 75% of the y values of the data set fall within plus or minus one s of the predicted values under the LSRL. -------------------------------------------------Yes, I think that is a valid application of Chebyshev's inequality (although it seems that "two s of the predicted values under the LSRL" must have been meant). G. Carpenter wrote on October 29, 2010: -------------------------------------------------So, it seems that unless you know the underlying distribution of the residuals, we can’t get a more precise lower bound than what Chebyshev gives. How can one go from 0% (Chebyshev )to 50% (a majority)? Sure, if we assume that the residuals are approximately normally distributed, then maybe you could claim 68% within plus or minus one s, or 95% within plus or minus two s’s. -------------------------------------------------In Devore's book he states that the underlying model is the following: Y = B0 + B1x + epsilon (this is in section 12.1) where the only random variables in that equation are epsilon and Y. We say that epsilon is randomly distributed with E[epsilon] = 0 and Var[epsilon] = sigma^2. so the normality of the residuals comes from the underlying model. That model may or may not accurately describe the actual phenomenon. (Y is also normally distributed random variable because it is the sum of a constant and a normally distributed random variable. http://en.wikipedia.org/wiki/Normal_distribution#Miscellaneous -- Devore gives this as an exercise at the end of section 4.4) Daren Starnes spoke indicating that one does not necessarily need to talk about an underlying model in order to find the correlation coefficient or to use the regression line to make predictions about other values of the explanatory variable. In terms of teaching this may also be a good approach in that one does not want to try to present material at too theoretical a level for the students.. At the end of section 12.1 Devore talks about how one can compute probabilities under the model of normally distributed residuals. G. Carpenter wrote on October 29, 2010: -------------------------------------------------Ok, tell me what I am missing, I am ready to be humbled. -------------------------------------------------I remember reading in Philip Stark's online text SticiGui: http://statistics.berkeley.edu/~stark/SticiGui/Text/index.htm that he did not cover inference in regression analysis for the following reason: "Above all else, I strive to be correct and not silly. I generally avoid presenting techniques I would not use as a consultant or expert witness. There are exceptions, but I have tried to mark them clearly. For example, I find little use for the t-test or Student t confidence intervals for the mean, but as a concession to their popularity, I have included them isolated in a single chapter that I usually do not cover. (But I present conservative confidence intervals for population percentages based on Chebychev's inequality, confidence intervals for percentiles, and Fisher's exact test.) ANOVA is missing for that reason. So is any use of regression as an inferential tool rather than a descriptive tool. Such uses are generally shaky, if not misleading or simply wrong." I don't know how prevalent some of those views are among statisticians. I haven't read a lot of SticiGui but I think it has an interesting approach: "The text starts with reasoning and fallacies, which is perhaps a bit unusual for a Statistics textbook but logical reasoning is key to both theoretical and empirical work." I found the comments from Yogi Bera amusing when he talks about fallacies of evidence: http://statistics.berkeley.edu/~stark/SticiGui/Text/reasoning.htm#evidence Example 2-20. David