Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
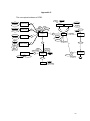
VISUALISATION MECHANISMS Supporting Genotype Analysis Evangelos Pafilis A dissertation submitted in part fulfillment of the requirement of the Degree of M.Res. in Bioinformatics at the University of Glasgow September 2003 Abstract Genome visualisation is an important tool which supports the analysis of genes involved in normal and abnormal activities of living organisms. Responding to the emerging demands for genotype analysis data display and genome variation rendering and retrieval, we propose a prototype web based application that aims to address both of these issues. We experiment with using an existing visualisation tool in a novel context, implement software that performs the visualisation logic and develop the required data storage facilities. The prototype we produced demonstrates how an implementation with a wider data coverage could satisfy some of the bioinformatics requirements arising from genetics research. 2 Acknowledgements I would like to thank the following people for their help with the project: Dr. Ela Hunt, for her support and guidance throughout the project Dr. Fadi Charchar for helping me understand the biological background of the project Dr. Bailey for sharing his thoughts on bioinformatics issues Mr. Andy Jones for sharing his ideas and opinions Dr. David Leader, Dr. Neil Hanlon, Ms. Eilidh Grant and Ms. Suzan Fairley for their assistance Mr. Micha Bayer and Mr. Chris Wu for their help in technical issues Mr. Jim Tourtouras and Ms. Areti Galani for their continuous support 3 Abstract ...................................................................................................... 2 Acknowledgements .................................................................................... 3 Abbreviations .............................................................................................. 6 1. Introduction ............................................................................................. 7 1.1 Need for visualisation ........................................................................ 7 1.2 Project stimulus ................................................................................. 7 1.3 Genotype Analysis Data.................................................................... 8 1.4 Single Nucleotide Polymorphisms (SNPs) ........................................ 9 1.5 Project Approach ............................................................................ 10 2. Design .................................................................................................. 11 2.1 Preparation ..................................................................................... 11 2.1.1 Literature and Web Resource Survey....................................... 11 2.1.2 Requirements Capture ............................................................. 12 2.2 Genotype Analysis Data Visualisation Design ................................ 13 2.3 Y Chromosome SNP Visualisation .................................................. 14 2.4 Y Chromosome SNP Database Data Source Design ..................... 15 2.5 Overall Application Design .............................................................. 16 2.6 Y Chromosome SNP Database design ........................................... 17 3. Implementation ..................................................................................... 19 3.1 YDB Implementation ....................................................................... 19 3.1.2 Implementing the Relational Schema ....................................... 19 3.1.3 Inserting Data ........................................................................... 19 3.2 Presentation Tier ............................................................................. 22 3.3 Application Tier ............................................................................... 23 3.3.1 Genotype Analysis Data Visualisation Middleware ................... 23 3.3.2 Y Chromosome Variation Visualisation Middleware ................. 25 3.4 Implementation Summary ............................................................... 27 4 4. Testing and Evaluation ......................................................................... 28 4.1 Testing ............................................................................................ 28 4.2 Evaluation ....................................................................................... 29 5. Discussion ............................................................................................ 30 5.1 Design Decisions ............................................................................ 30 5.1.1 Only dbSNP as the Data Source for YDB ................................. 30 5.1.2 Not only SNPs .......................................................................... 30 5.2 Implementation Decisions ............................................................... 31 5.2.1 MySQL as the RDBMS ............................................................. 31 5.2.2 Parsers in the Java Language .................................................. 31 5.2.3 Both CGI and Servlets as Middleware Technology .................. 32 5.2.4 DerBrowser as the Visualisation Tool ....................................... 32 5.3 Application Criticism: Achievements and Drawbacks ...................... 33 5.4 Further Improvement....................................................................... 34 6. Conclusion ............................................................................................ 36 References ............................................................................................... 37 A. Literature .......................................................................................... 37 B. Internet Resources ........................................................................... 39 Appendix A ............................................................................................... 40 Appendix B ............................................................................................... 42 Appendix C ............................................................................................... 43 Appendix D ............................................................................................... 44 Appendix E ............................................................................................... 45 Appendix F ............................................................................................... 46 5 Abbreviations ASN1: Abstract Syntax Notation One BPG: Blood Pressure Group BHF: British Heart Foundation CGI: Common Gateway Interface DIP: Deletion Insertion Polymorphism HTML: Hyper Text Mark up Language HTTP: Hyper Text Transfer Protocol JDBC: Java DataBase Connectivity RDBMS: Relational DataBase Management System STR: Short Tandem Repeat dbSNP: Single Nucleotide Polymorphism Database SNP: Single Nucleotide Polymorphism SQL: Structured Query Language TSC: The SNP Consortium YDB: Y Chromosome Variation DataBase 6 1. Introduction 1.1 Need for visualisation The development of high throughput techniques and large-scale studies in the biological sciences has given rise to an explosive growth in both the volume and types of data available to the researchers. The genome sequence of many organisms is now known and is being annotated constantly. Handling this ever increasing amount of information is no longer a straightforward issue and therefore computational methods have to be applied. Accessing annotated sequence data in textual format can be extremely laborious and time consuming (Bryce, 2003). A graph that utilizes different colours and shapes in order to render every piece of genomic information associated with a particular region, would ease the process of data interpretation and allow the generation of conclusions. Thus, there is a need for a visualisation tool that would display the exact location and range of each genetic element existing in a genomic sequence, provide a user with facilities such as the retrieval of further information and be easy and intuitive to use. 1.2 Project stimulus The driving force of this project was to provide a group of researchers at the British Heart Foundation (BHF) Blood Pressure Group (BPG) of the Division of Cardiovascular & Medical Sciences of the University Of Glasgow [a] with visualisation tools that would support their ongoing experiments. The visualisation of both genotype analysis results and genome variations, focusing on Single Nucleotide Polymorphisms (SNPs) was the bioinformatics problem to be solved. 7 1.3 Genotype Analysis Data Certain congenic rat strains have been genotyped for a series of markers and the results were held in a Microsoft Excel® flat file (Figure 1). Figure 1: Flat file containing genotype analysis data All the markers shown belong to rat chromosome 2. The rectangles correspond to a certain genotype according to the colour code shown on the right. The coloured rectangles give a visual overview of the marker genotypes for each rat strain. However, if the researcher wishes to place the markers on their relative locations on the chromosome, checking for example their distribution, then he/she is forced to traverse though the base pair position of each one. In this form of data presentation the real physical distances on the chromosome of interest are not shown, which makes the interpretation of data incomplete. We postulate that there is a need for an application that would accept this flat file as input and return a visualisation maintaining the same color code and simultaneously rendering the markers on their chromosomal position. 8 1.4 Single Nucleotide Polymorphisms (SNPs) An SNP is a substitution of one base pair at a given location on the genome. At position 11,294,479 on human chromosome 7, for example, some people have an A, while others have a G. On average, SNPs are spaced every 300 bases throughout the human genome and are estimated at nearly 10 million (Orgen, 2003). Each is a genomic landmark, a surveyor's marker that researchers can use to chart the location of disease genes and heritable traits, for instance. Most SNPs reside outside coding regions, exerting potential influence on gene regulation and expression. Many researchers value these SNPs for use in association studies and whole-genome linkage-disequilibrium mapping. In this type of analysis, maps of common, genome-wide polymorphisms are used to unearth variations that are associated with, but not causative of, medical conditions. Some polymorphisms occur in protein-coding regions (cSNPs) and may directly contribute to disease, disease susceptibility, and drug metabolism, by altering gene function. (Orgen, 2003). BPG researchers have already documented that the Y chromosome harbors a locus or loci that contribute to blood pressure variation in hypertensive and normotensive men (Charchar et al., 2003). Their next step is to perform haplotype analysis on a general sample of Polish males and to try to associate high blood pressure with certain combinations of SNP allelic states, constituting a particular haplotype. Additionally, because of its sex determining role, the Y chromosome is male specific and constitutively haploid. It passes from father to son, and, unlike other chromosomes, largely escapes meiotic recombination1, 2. The importance of escaping recombination is that haplotypes usually pass 1 2 Recombination is the formation of new combination of alleles though meiotic crossover. Some authors include intrachromosomal gene conversion under this heading. As this has been shown on Y chromosome (Rozen et al., 2003), they prefer not to refer to it as ‘non-recombining’. Two segments (the pseudoautosomal regions) do recombine with the X, but these amount to less than 3 Mb of its ~60-Mb length. 9 intact from generation to generation. They change only by mutation, rather than the more complex reshuffling that other chromosomes experience, and so preserve a simpler record of their history. Using binary polymorphisms1 with low mutation rates, such as SNPs, a unique phylogeny can therefore easily be constructed. (Jobling et al., 2003) A storage and visualisation mechanism designed specifically for the Y chromosome SNPs, containing the publicly available knowledge, would allow researchers to obtain information for the each SNP, such as the experimental conditions required, and thus will assist them in performing their haplotype analysis and phylogeny construction experiments. Additionally, the same application could accommodate the storage of their own generated SNP data. 1.5 Project Approach This project demonstrates how a web based application can provide solutions to the bioinformatics issues mentioned in the previous two sections. An existing visualisation tool was linked with data originating from different sources, a flat file that was being read and a database that was being queried. The tasks performed comprised of surveying the relevant literature and web resources, interviewing scientists and capturing the requirements, developing a database schema, processing data from publicly available databases, implementing the middleware software and installing and administrating a web server. 1 For more information on why the SNPs tend to exist in binary forms, i.e. having two alleles, see Brown, 2002) 10 2. Design 2.1 Preparation 2.1.1 Literature and Web Resource Survey Before designing the web application, the literature and the internet were surveyed to gather information regarding the human Y chromosome and SNP web databases. The reason for studying the Y chromosome literature was to obtain a greater depth on the BPG ongoing experiments and to be able to evaluate biologically the findings emerging though the construction of the application, e.g. the number of loci found to be associated with SNPs stored in the database. Milestone in this background reading was the publication of an article that analysed and interpreted from the evolutionary perspective the nearcomplete sequence of Y euchromatin, including thorough gene identification (Skaletsky et al. 2003). Querying web search engines [b], [c] and for ‘SNP database’ the results included among the others the Single Nucleotide Polymorphism Database (dbSNP) (Sherry et al. 2001) [d] established by the National Center for Biotechnology Information [e] and the The SNP Consortium (TSC) website (The International SNP Map Working Group, 2001) [f]. In addition, SNP data were available in the Ensembl database (Hubbard, T. et al., 2002) [g], queried through EnsMart [h]. The previously mentioned web resources were used to prepare screen shots of SNP mapping visualisation and information retrieval facilities (Appendix A) that were used in the requirements capture interviews. 11 2.1.2 Requirements Capture1 The requirements capture procedure involved interviewing molecular biologists from the BPG and other research groups. The interviewees had either molecular genetics experience or an interest in bioinformatics. The former described the specific requirements that the application should meet, while the latter offered a more generic view of how an SNP storage – visualisation mechanism should be implemented, focusing on visualisation topics. The interviewees were shown SNP records extracted from web databases and were asked to point out which parts of information are regarded as essential for their research and should be included in the database to be created. In addition, the interviewees were requested to describe the desired appearance and the functionality of the application based on observations and remarks on the SNP visualisation and information screen dumps mentioned in the previous section. (Appendix A) The conclusion was the need for an application with an interactive interface that would provide user with an overview of the SNPs in respect to their chromosomal positions, and tools for displaying the information available on each of them. This interface should be scrollable and zoomable and should accommodate an SNPs search facility. Finally, it would be of the utmost importance to render SNPs comparatively with other genetic elements of the same sequence such as microsatelites and genes, or even better gene substructures. 1 The interviews handled only the Y chromosome SNP visualisation topic. The need for genotype analysis data visualisation emerged after the interviews were conducted. Since there are certain common elements in the applications that would serve these two issues independently, they were merged into one. 12 2.2 Genotype Analysis Data Visualisation Design In our project we decided to create an application to support genotype analysis data visualisation. This was accommodated by the following three tier web application1 (Figure 2). Figure 2: Client – web server architecture for the genotype analysis data visualisation The applet on the client size will be the visualisation tool. The middleware lying on the application tier will be responsible for converting the genotype analysis data into an applet compatible format and the data tier will cache client data on the web server, using files. 1 The structure of a generic tree tier web application is explained in Appendix B 13 2.3 Y Chromosome SNP Visualisation The other application our project gave rise to was a Y Chromosome SNP visualisation which is accommodated by the following three tier web application (Figure 3). Figure 3: Client – web server architecture for the genotype analysis data visualisation The applet on the client size will be the visualisation tool used in the genotype visualisation. The middleware in the application tier will be responsible for querying the database, transforming the data format, and storing the data returned by the transformation in an applet compatible format. The data tier uses a combination of a database and files. 14 2.4 Y Chromosome SNP Database Data Source Design A relational database will hold SNP information. The database schema will be similar to that of other SNP databases available on the web, but will be modified to suit the specific needs of the application. The Y chromosome SNP data will originate from flat file dumps of existing web databases. A parser will be needed in order to read these flat files. The parser will select the desired pieces of information and prepare scripts to load the database (Figure 4). Database loading should be performed by a database administrator. Web Database Flat File 1 Web Database Flat File 2 Parser Script Database Figure 4: Filling database with data 15 2.5 Overall Application Design Since the web applications for the genotype analysis data and Y Chromosome SNP visualisation share the same presentation tier and the creation of an applet specific flat file in the application and data tier, they can be merged into one application. Taking into consideration the database creation, the whole web application can be summarised as shown on Figure 5. Figure 5: Overall web application design 16 2.6 Y Chromosome SNP Database design The conceptual schema conceived for the SNP database is illustrated in the Appendix C entity relationship diagram, and constitutes a modified version of the dbSNP schema [i]. In dbSNP the term SNP refers to a broad collection of simple genetic polymorphisms that includes, among the others: SNPs, small deletions or insertions (a.k.a. Deletion Insertion Polymorphisms, DIPs), retroposable element insertions and microsatellite repeat variations (a.k.a. Short Tandem Repeats, STRs) (Kitts et al., 2003) In the local database the term ‘variation’ has been used instead. This is the reason for naming the database as Y Chromosome Variation Database (YDB), since it is Y chromosome specific as well. According to the YDB conceptual schema a variation has features such as an internal id that is used as a unique identifier (varID), a unique dbSNP Id (varRefID), allelic states, neighbouring sequence and, not always, a heterozygosity estimate. In addition it belongs to a certain class, e.g. SNP, or DIP, or STR and has a specific type, e.g. not withdrawn or artifact. Each variation might have a mapweight, a code representing how many times the variation occurs in the organisms genome, e.g. 1: once, 2: twice, 3: from 3 to 9 times1. For every variation there is a certain validation status e.g. validated by multiple submissions, or validated by frequency data, or even not validated. Each validation status is associated with a certain colour, a feature that can be exploited by the visualisation tool2. 1 For more information on variation classes and types check Kitts et al., 2003 and the documentation available on dbSNP home page [d]. 2 For more information on possible validation status check Kitts et al., 2003 17 A variation might be associated with one or more loci. Each association has a sequential number and perhaps a type. Each type belongs to a certain functional class, e.g. locus when the variation lies in the locus region, approximately to a gene feature but not in the transcript. For every functional class YDB keeps an appropriate description. For each locus there is an id and a symbol stored. If the variation associated with a certain locus is determined to be in a coding region, then the allelic state, the reading frame, the translated amino acid residue and the position of the amino acid in the peptide sequence may be defined. Finally, a variation may have a set of contig hits reporting each genomic position predicted by in silico sequence analysis. For every hit the strand and type1 are being stored. For each contig the id and the accession number are being stored. The version of the contig that the variation maps at is stored in the contig hit entity. 1Whether it is an exact base pair position, a range of base pairs or between two base pairs 18 3. Implementation1 3.1 YDB Implementation 3.1.2 Implementing the Relational Schema YDB was implemented using MySQL2 [j] Relational DataBase Management System (RDBMS). An overview of the tables created is available in Appendix D. The script file containing the Structured Query Language (SQL) commands to generate these tables is CreateAllTablesAndIndices.sql3. 3.1.3 Inserting Data dbSNP4 has been used as the data source for YDB. Human Y chromosome specific flat files were downloaded through the ftp site [k]. Pieces of the information to be hosted on YDB existed in all the three different flat file types: the chromosome report, the Abstract Syntax Notation One (ASN1) flat file, and the FastA flat file5. NCBIParser6 is a Java [l] command line application that parses the aforementioned flat files, and creates the InsertNonFixedData.sql3, an SQL script containing the appropriate commands to load variation data in YDB. ‘NonFixedData’ refers to the fact that the data just parsed and loaded are those being updated on every build of dbSNP, e.g. variations that have been added or removed. InsertFixedData.sql3 contains SQL commands to load data that remain constant in YDB such as the different variation classes and mapweights together with their description. This file has been created 1 Arguments for or against the implementation choices are presented in the Discussion section of this report. 2 Version 3.23.54 3 Contained in the ‘YDB’ folder of the CD 4 Build 115 5 Contained in the ‘YDB\dbSNPChrYData’ folder of the CD 6 Contained in the ‘NCBIParser’ folder of the CD 19 manually and complies to the relational schema of YDB and the context of dbSNP. The YDB data loading procedure is summarised in Figure 6. Figure 7 is the NCBIParser class diagram. A characteristic of the NCBIParser is that it implements pattern matching using regular expressions, a central feature of Perl programming language (Leader, 2003) that become available in the Java 2 Standard Edition Software Development Kit Version 1.4. (Hitchens, 2002) Figure 6: YDB implementation summary 20 Figure 7: NCBIParser Class Diagram. NCBIParser class holds the methods for parsing the dbSNP flat files and creating the SQL script file. The rest of the classes are used in creating objects that would store the information of all the variations. 21 3.2 Presentation Tier The front end of the application is an Hyper Text Mark up Language (HTML) web page available at: http://balabio.dcs.gla.ac.uk/pafilisv/, accessible by any web browser (Figure 8). An experimental version of DerBrowser (Grigoriev, 1998), a Java applet, is the visualisation tool for both marker genotypes and Y chromosome variations. If the user selects to visualise a genotype analysis data file, then he/she is prompted to upload the Excel file containing the genotyping experiment results (Figure 9). If the user selects to view Y chromosome variations then YDB is being accessed and the visualisation tool invoked. Figure 8: Visualisation Mechanisms Supporting Genotype Analysis, entry page. 22 Figure 9: Data file upload interface 3.3 Application Tier 3.3.1 Genotype Analysis Data Visualisation Middleware After the Excel file has been submitted, a Hyper Text Transfer Protocol (HTTP) POST request invokes a Common Gateway Interface (CGI) [m] script written in Perl language [n]1. Figure 10 summarises the series of actions performed by this script. 1 Contained in the ‘WebPage\MarkerMapVisualisation\CGI’ folder of the CD 23 Figure 10: Implementing marker genotype visualisation business logic Initially the Excel file is saved in the server side. Then a Perl script, written by Ashley Pond [o]1, reads the Excel file and converts it into a tab delimited text file. Subsequently, the tab delimited text file is being parsed by JMarkerMapParser2, a Java command line tool and a DerBrowser compatible flat file is being created. Finally, the Perl – CGI script returns an HTML page (Figure 11) where the marker genotypes are being rendered by DerBrowser. 1 2 Contained in the ‘WebPage\MarkerMapVisualisation\XLS2TXT’ folder of the CD Contained in the ‘JMarkerMapParser’ folder of the CD 24 Figure 11: Genotype Analysis Data Visualisation. The colour of each box corresponds to a different genotype according to the colour code shown on top. The scale on the left hand side corresponds to the physical chromosome length. Individual rat strains are shown as columns. 3.3.2 Y Chromosome Variation Visualisation Middleware The visualisation of Y chromosome variations logic is implemented by a servlet [p], a Java server-side program that contains methods to respond to HTTP requests, to connect to databases and to return a new HTML page. 25 CreateDBrFlatFileServlet.java1 implements the functionality displayed in Figure 3. It connects to YDB using Java DataBase Connectivity (JDBC)2 [q], queries the name and position and validation status colour of every Y chromosome variation (Appendix E), writes these data in a DerBrowser compatible file and returns an HTML page (Figure 12) with the visualisation. In order for the servlets to be functional, they must be contained inside a servlet engine running on a web server. Jigsaw 2.2 [r], both a web server and a servlet engine, was used. Figure 12: Y Chromosome Variation Visualisation, with the physical chromosome scale on the left, and SNPs shown as black boxes in the first column. 1 2 Contained in the ‘WebPage\YDBServlets’ folder of the CD JDBC, the application programming interface for connecting Java programs with database systems 26 3.4 Implementation Summary The implementation procedure mentioned in the previous sections is summarised in Figure 13. Figure 13: Overall Implementation Summary 27 4. Testing and Evaluation 4.1 Testing Throughout the whole project comprised of a series of incremental steps. At each stage the correctness of newly added code was tested, using manual comparison of input and output data. The dbSNP flat files have been checked for either missing or invalid data, e.g. a missing value or a word instead of a number. This check was performed partially during the parsing and partially during the YDB data loading. Another possible source of errors is the format of the uploaded Excel file containing marker genotype data. On the relevant web page (Figure 9) there are clear directions regarding the specifications that the Excel file should comply with. A file that can be used as template is available for downloading as well. For both NCBIParser and JMarkerMapParser there were no synthetic control data samples available. As an alternative, flat files were generated containing every different combination of data that should be dealt with. The parsers were fine tuned using these synthetic data files and then applied to the real data. The servlet associated with the Y chromosome variation visualisation was initially constructed using a stand-alone Tomcat 4.0 [s] servlet engine and was transferred to Jigsaw after it has been debugged. Prompts have been added to server command line output in order to provide web server administrator with proper feedback (Figure 14). Finally, when the application was released, it was tested at the BPG location in the Western Infirmary in order to identify any possible access or configuration issues. 28 Figure 14: Providing administrator with feedback on the servlet execution 4.2 Evaluation A molecular biologist and a bioinformatician of the BPG evaluated the web application. They were given some time to test both the marker genotype and the Y chromosome variation visualisation and they were asked a number of specific questions (Appendix F) focusing on user friendliness, visualisation issues, problems and deficiencies, and suggestions for further improvement. 29 5. Discussion 5.1 Design Decisions 5.1.1 Only dbSNP as the Data Source for YDB The initial concept was that the YDB data would originate from more than one web database. Considering the time limit for the completion of the project, we decided on building a prototype with equally developed components and propose data integration from several web databases as a future extension1. The selection of dbSNP as the data source is supported by the fact that dbSNP is integrated with other large public databases, via the LocusLink database (Sherry et al., 2001). The existence of such links can assist the identification of entries in different databases that refer to the same variation and, thus, support data integration. The plethora of documentation and guidance available on the dbSNP web site is another reason for selecting dbSNP. The topics ranged from the biological significance of genome variation to technical details of the database, easing this way the gathering of background information and database design. The fact that dbSNP flat files are divided by chromosome, suited the purpose of the application to focus only on Y chromosome. 5.1.2 Not only SNPs The information on types of genomic variation other than SNPs could have been disregarded, since BPG researchers are mainly interested in SNPs. However we decided on retaining it because, as will be demonstrated in the ‘Further Improvement’ section that DerBrowser can display these extra pieces of information in a biologically significant way. 1 Data integration as a further improvement is being presented in the next chapter of the report 30 5.2 Implementation Decisions 5.2.1 MySQL as the RDBMS MySQL has been selected as the RDBMS because it offers stability, support, and low cost (Suehring, 2002). This means that if e.g. BPG want to install MySQL locally that will require neither significant funds, nor administrative personnel. MySQL advantages and disadvantages compared to other RDBMSs are being displayed in Table 1. Table 1: Comparison of SQL Implementations1 5.2.2 Parsers in the Java Language The parsers needed for the application have been written in Java. This is due to our familiarity with this language which exploits the advantages of object oriented programming, and allowed us to create easily the required data structures and algorithms. 1 From Suehring, 2002, TCO is the abbreviation of Total Cost of Ownership 31 5.2.3 Both CGI and Servlets as Middleware Technology1 Both marker genotype and Y chromosome variation visualisation middleware technology could have been implemented with either CGI or Servlets. The older and slower2 CGI, written in Perl, (Speegle, 2002) was selected to implement marker genotype visualisation. The fact that no complicated tasks, e.g. database connectivity, were required in this part of our work, combined with the ease offered by Perl in invoking command line applications and scripts, were the reasons for this choice. For the more demanding Y chromosome variation visualisation Java Servlet technology has been used. Since servlets are Java programs, they have access to the entire family of Java Application Programming Interfaces and receive all the benefits of the Java language including portability and crash protection. In addition, because one of the application requirements is the interaction between the applet (DerBrowser) and the database (YDB), servlets can be used in order to guarantee safety and to overcome security issues (Speegle, 2002). 5.2.4 DerBrowser as the Visualisation Tool DerBrowser is a visualisation tool that is conforms to the requirements we identified during our project. It is an applet designed to display objects on a genomic map, it can query a data source about a selected object, find an object by name, and provides the user with zooming and scrolling capabilities. In addition, DerBrowser is written is an older version of Java and thus is supported by most of the web browsers. 1 2 A comparison of middleware technologies is available at Speegle, 2002 Preface pages x, xi Slower, since it greatly increases the number of processes running on a server. 32 5.3 Application Criticism: Achievements and Drawbacks The data processing and visualisation mechanisms developed within the scope of this project performed well only in providing BPG researches with visualisation tools for viewing their genotype analysis results. As shown by Figure 11, the desired result of viewing marker colour-coded genotypes, in respect to the marker physical location has been achieved. However, it has to be mentioned that extensive use of zooming and scrolling, together with an ‘artificial increase’ in the length of the markers1 were necessary. Figure 15: Y Chromosome Variation Visualisation in the highest zoom possible 1 Markers by definition indicate a certain point in the genome. In order to improve visualisation they have assigned range whose centre is the genomic position that they indicate. 33 On the contrary the Y chromosome variation visualisation (Figures 12 and 15), did not have the expected outcome. Most of the variation names did not appear at all and many variations due to their proximity appeared as smear. In addition the requirement of querying YDB and retrieving variation specific information has never been met. However, from a broader point of view, the achievement was the implementation of an application that can serve more than one purpose and provides a fundamental storage and visualisation facility that can be extended in many directions. 5.4 Further Improvement This application demonstrated clearly that DerBrowser, proves to be more useful in displaying large objects rather than small genomic variations. There is a need towards increasing the zooming capacity, something that should be accompanied by a smooth scrolling behaviour. The name display perhaps should be reconsidered, along with the suggestion of colouring not only the genetic objects but their labels as well. Before viewing Y chromosome variations, the user should be prompted to specify what exactly he/she wishes to view and in which way, through drop down menus, radio- and check-buttons. For example he/she might select only the validated variations, or the variations that exist in a certain region, or have a certain degree of heterozygosity. Even further he/she may choose to view a certain kind of variation (e.g. SNPs) in one of DerBrowser stripes and another kind of variation (e.g. microsatelites) in the adjacent stripe. 34 The latter could be of utmost importance. If the user could select to view concurrently certain genomic variations, such as SNPs, in one stripe and other genetic elements, such as genes, in the next one, a better understanding of the positions and significance of the SNPs could be gained. However, this implies that the database should contain all those pieces of information, and thus would constitute an integrated biological database rather than a database of genomic variation. The data integration issue, though, despite of the efforts to solve it, will remain a difficult problem for the conceivable future (Stein, 2003). 35 6. Conclusion This project demonstrated how the features of multi-tier web applications can be exploited in order to serve the purposes of bioinformatics. The separation between the presentation layer, application logic and the data storage layer, supported the segmentation of the problem into smaller parts and assisted the implementation of components which deal with each one of the layers specifically. Existing visualisation tools and web interfaces were used in order to present biological data in a more explicit manner than would be possible within a spreadsheet program. However, the existing software had to be modified and adjusted so that it could serve the exact needs of the user, as defined during the software requirements analysis. A variety of middleware technologies were used to implement the application logic. Those included CGI scripts and Java Servlets. We used a MySQL database management system to manipulate biological data. We identified further issues in data integration that would provide the biologists with valuable complementary and comparative information on genotypes and genetic variation. Implementing a web application in order to satisfy the needs of the BPG research group was not only a software engineering task but required a significant amount of problem solving and intellectual scrutiny of the data and the research practice. 36 References A. Literature Brown,T.A. (2002) Genomes Second Edition. BIOS, pp: 131, Box 5.1. Charchar F. et al. (2002) The Y Chromosome Effect on Blood Pressure in Two European Populations. Hypertension, 39: 353 356. [HTML] Grigoriev, A. et al. (1998) Distributed environment for physical map construction. Bioinformatics, 14, 242-258 Hitchens, R. (2002) Java™ NIO. O’Reilly, ISBN: 0-596-00288-2. Hubbard, T. et al. (2002) The Ensembl genome database project. Nucleic Acids Research 30, 1, 38–41. Hunter, B. (2003) Gene Visualisation And Comparison Tool. Final Year Project Report, Dept. Of Comp. Science, Uni. Of Glasgow, pp: 3, 4. Jobling, M., Tyler-Smith,C. (2003) The Human Y Chromosome: An Evolutionary Marker Comes Of Age. Nature 424, 598–612 Kitts, A., Sherry, S. (2003) The Single Nucleotide Polymorphism Database (dbSNP) of Nucleotide Sequence Variation. NCBI Handbook, Chapter 5. [HTML] Leader, D. (2003) David’s Perl. Perl Module Notes MRes Bioinformatics Glasgow University. Ogren,M. (2003) Whole-Genome SNP Genotyping. The Scientist, 17,11, 42. [HTML] Rozen, S. et al. (2003) Abundant gene conversion between arms of massive palindromes in human and ape Y chromosomes. Sherry, S.T et al. (2001) dbSNP: the NCBI database of genetic variation. Nucleic Acids Research. 29:308-311. 37 Skaletsky, H. et al. (2003) The male-specific region of the human Y chromosome: a mosaic of discrete sequence classes. Nature 423, 825–837. Speegle, G. (2002) JDBC: Practical Guide For Java Programmers. Morgan Kaufman Publishers, ISBN: 1-55860-736-6 Stein, L. (2003) Integrating Biological Databases. Nature Reviews Genetics 4, 337-345. Suehring S. (2002) MySQL Bible. Wiley, pp: 7-14, ISBN: 0-7645-4932-4 The International SNP Map Working Group. (2001) A map of human genome sequence variation containing 1.4 million SNPs. Nature 409, 928–933. 38 B. Internet Resources [a] British Heart Foundation Blood Pressure Group: http://www.medther.gla.ac.uk/bhf/index.htm [b] Google Search Engine: http://www.google.com [c] Scirus Scientific Information Search Engine: http://www.scirus.com [d] Single Nucleotide Polymorphism Database (dbSNP) Home Page: http://www.ncbi.nlm.nih.gov/SNP/ [e] National Center for Biotechnology Information Home Page: http://www.ncbi.nlm.nih.gov/ [f] The SNP Consortium (TSC) Home page: http://snp.cshl.org/ [g] Ensembl Genome Browser: http://www.ensembl.org [h] Ensmart Data Retrieval Tools Set: http://www.ensembl.org/EnsMart/ [i] dbSNP Schema: ftp://ftp.ncbi.nih.gov/snp/mssql/schema/erd_dbSNP.pdf and changes:http://www.ncbi.nlm.nih.gov/SNP/snp_schemaChange.htm [j] MySQL Home Page: http://www.mysql.com [k] dbSNP FTP site: ftp://ftp.ncbi.nih.gov/snp/ [l] The source for Java Technology http://java.sun.com/ [m] CGI Information Page: http://hoohoo.ncsa.uiuc.edu/cgi/ [n] Perl Home Page: http://www.perl.com/ [o] Excel to Tab delimited Text File Converter http://sedition.com/perl/excel_to_delim.html [p] Java Servlet Technology: http://java.sun.com/products/servlet/ [q] JDBC Technology: http://java.sun.com/products/jdbc/ [r] Jigsaw Home Page: http://www.w3.org/Jigsaw/ [s] Tomcat Home page: http://jakarta.apache.org/tomcat/ 39 Appendix A Screen shots of SNP mapping visualisation and information retrieval facilities. Ensembl (Ensmart) 40 SNP ‘rs3848982’ following the link to UCSC Genome Browser from the dbSNP record 41 Appendix B Structure of a generic tree tier web application. Abstract structure of a three tier web architecture. There is a clear distinction among the presentation layer that displays data to the user, the application layer that implements business logic and a data layer where data are being stored. 42 Appendix C The conceptual schema of YDB. strSymbol strDescr varClassName locatTypeID 1 VariationClass is N Strand varClassDesc hetero alleles varTypeName VariationType 1 N has N 1 Variation mapWeightID MapWeight N 1 N CtgHit has contigAcc contigID N Contig regarding N 1 ctgHitID has mapWeight Description contigVersion 1 N startPosCtg valStatus ID valStatus Abbr has sequence varID varTypeDesc locatType Name 1 1 hetSError varRefID has LocationType N endPosCtg 1 ValidationStatus has belongsTo has N N valStatus Desc valStatus Colour 1 varResidue varAllele readFramePos aaPosition 1 FunctionClass has 1 fxnClassName fxnClassDesc N Associated Locus Chromosome maps assocSeq No startPosChr N endPosChr regarding 1 locusID Locus locusSymbol 43 chrID Appendix D Overview of YDB Relational Schema 1. VariationClass (varClassName, varClassDescription) 2. VariationType (varTypeName, varTypeDescription) 3. MapWeight (mapWeigthID, mapWeightDescription) 4. ValidationStatus (validStatusID, validStatusAbbr, validStatusDescription, validStatusColour) 5. FunctionClass (fxnClassName, fxnClassDescription) 6. Variation (varID, varRefID, varClass, alleles, hetero, hetSError, validStatus, varitype, varMapWeight, sequence) 7. Locus (locusID, locusSymbol) 8. Strand (strSymbol, strDescription) 9. Contig (contigID, contigAcc) 10. AssociatedLocus (assocSeqNo, asVarID, asLocusID, fxnClass, readFramePos, varAllele, varResidue, aaPosition) 11. CtgHit (ctgHitID, variationID, ctgID, ctgVersion, startPosCtg, endPosCtg, ctgStrand, ctgLocationType, chrom, startPosChr, endPosChr) 12. LocationType (locatTypeID, locatTypeName) 44 Appendix E SQL Query SELECT startPosChr, endPosChr, varRefID, varID, validStatusColour FROM Variation, CtgHit, ValidationStatus WHERE startPosChr <> 0 AND varID = variationID AND validStatus = validStatusID; 45 Appendix F Questionnaire Marker Map Visualisation How easy was it for you to use the module? (Please tick as appropriate) Very easy Relatively easy Intermediate Hard Very hard Were the titles used the appropriate ones? (Yes/No) If No please suggest some alternative ones: ……….…………………………...……………………………………………… ……………………………………………………………………………………… How informative was the visualisation? Very much Did you Adequately identify Intermediate any Inadequately problems or Not at all malfunctions? ……………………………………………………………………………………… ….………………………………………………………………………………….. ……………………………………………………………………………………… What would you like to suggest as an amendment or a further improvement? ……………………………………………………………………………………… ……………………………………………………………………………………… ……………………………………………………………………………………… 46 Y Chromosome Variation How easy was it for you to use the module? (Please tick as appropriate) Very easy Relatively easy Intermediate Hard Very hard Were the titles used the appropriate ones? (Yes/No) If No please suggest some alternative ones: ……….…………………………...………………………...……………………… ……………………………………………………………………………………… How informative was the visualisation? Very much Did you Adequately identify Intermediate any Inadequately problems or Not at all malfunctions? ……………………………………………………………………………………… ….………………………………………………………………………………… What would you like to suggest as an amendment or a further improvement? ……………………………………………………………………………………… ……………………………………………………………………………………… ……………………………………………………………………………………… Would you support the creation of a Y Chromosome Integrated Database? Please support your answer with a few points or examples. ……………………………………………………………………………………… ……………………………………………………………………………………… 47 Both Applications DerBrowser was not originally built in order to render genetic markers. Are satisfied with its performance? Please support your answer with a few points or examples. ……………………………………………………………………………………… ……………………………………………………………………………………… ……………………………………………………………………………………… ……………………………………………………………………………………… Do you think that the visualisation software should be extended further? Please support your answer with a few points or examples. ……………………………………………………………………………………… ……………………………………………………………………………………… ……………………………………………………………………………………… ……………………………………………………………………………………… 48