Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
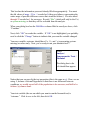
SMARTPsych SPSS Tutorial Binomial Test (Sign Test) in SPSS While studying for his statistics midterm, a UW student notices that his understanding of the concepts increases while he listens to Limp Bizkit. He wonders if other students would also benefit by listening to Limp Bizkit while they study stats. In order to decide if this intervention might work, he takes 25 students from his class who agree to be part of his study, and assigns each student to a “no music” condition and to a “music” condition (a within-subjects design); in the latter condition, Limp Bizkit is playing through a set of headphones that each student wears. In both conditions, students work through 25 difficult statistics problems. The data that are collected are the number of problems that are correct (out of 25) in each condition. These data appear to the left. Now that the study has been conducted, we would of course want to know if Limp Bizkit truly does make a difference in one’s statistics performance. This can be accomplished (among other ways that you will discover later) with the BINOMIAL TEST (also known as the sign test) in SPSS. Below I’ve constructed a boxplot of the data in SPSS so that you can see how scores for the two conditions are distributed. (If you wanted to do this, you would start by selecting GRAPHS / BOXPLOT from the menu in SPSS. You would then do a simple boxplot of the separate variables “music” and “nomusic.”) 30 It appears that the median values are about the same for both conditions, though the Q1 and Q3 scores are higher in the ‘music’ condition. It’s difficult to determine if there’s a difference without using a statistical test… 20 10 0 N= 25 25 MUSIC NOMUSIC Well, you can’t run a binomial test on these data until you create a variable that meets the binomial criteria. That is, you need to have a variable that identifies “successes” and “failures.” Here, let’s use 0 to represent a failure (the student’s performance in the ‘no music’ condition is better than performance in the ‘music’ condition) and a 1 to represent a success (superior performance in the ‘music’ condition). You may ask at this point, what do you do if the performance under the two conditions is equal? Well, the convention is to throw out cases in which this happens. Ideally, your measurement would be so sensitive that you would always have a difference between the scores, but if you don’t, you usually reduce your sample size by the number of “ties” that you find. At this point, you will need to compute a new variable that is the difference between the two conditions. We’ll do this through the menu system, though you can do it through syntax. Start by selecting TRANSFORM / COMPUTE. You now want to compute a new variable (here I used ‘diff’) that is the score in the ‘no music’ condition subtracted from the score in the ‘music’ condition. In this dialog box, you can click the variables over from the list to the left, and perform functions on them using the calculator. Notice that there are many functions from which to choose; here, we’re just doing simple subtraction. When you have your dialog box set up as above, click “OK” to run the command and to create a new variable. You can also click “Paste” to place the command into syntax (the best option if you are going to run the command more than once; e.g., if you had a data entry error earlier). Now, we need to make another variable that denotes successes (1) and failures (0). The best way to do this in SPSS is using the RECODE command. This feature allows you to take the values in one variable and recode them (either to the same or to a different variable). We want all values in the “diff” variable that are positive to be recoded as 1, and all values that are negative to be recoded as 0. We will exclude cases with a difference of 0. Select TRANSFORM / RECODE / INTO DIFFERENT VARIABLES from the menu in SPSS. You will get the dialog box above. Click over the “diff” variable, because you want to recode it. The “output variable,” the new variable, we’ll call “outcome.” You must click the “CHANGE” button for the new variable to be recoded. Now, select the values that you want to recode by clicking “OLD AND NEW VARIABLES.” You will get the dialog box that follows: This box has the information you need already filled in appropriately. You want the old values of range –25 to –1 recoded as 0 (these are failures, representing the entire range of possible difference scores that would be failures). You also want 1 through 25 recoded as 1 for successes. Recode “Else” (which will only be the 0’s) as system-missing, so that they will be excluded from the analysis. When your dialog box has the OldNew column filled in exactly as above, click “Continue.” Next, click “OK” to recode the variable. If “OK” is not highlighted, you probably need to click the “Change” button to indicate that you want the variable changed. Your new variable, outcome, should have 0’s, 1’s, and .’s (representing systemmissing) as values only. Now, you’re ready to run your binomial test!!! Select Analyze / Nonparametric Tests / Binomial. The dialog box to the left should then appear. Notice that you can specify the test proportion (this is the same as p). Here, we are using .5, because if our null hypothesis is that there is no difference between conditions, we would expect half of the population to be successes, and half to be failures, by chance alone. Your test variable (the one on which you want to run the binomial test) is “outcome.” Click it over to the left, then click OK. Binomial Test succes s or failure Group 1 Group 2 Total Category 1.00 .00 N 18 5 23 Observed Prop. .78 .22 1.00 Test Prop. .50 Exact Sig. (2-tailed) .011 Your output is relatively simple. First, notice that your N is 23; this is because you had two cases in which there was no difference between conditions, which were removed from the analysis. There are 18 successes (78%) and 5 failures (22%). The significance (exact sig.) is the most interesting part here: it is .011. What does this mean? If there really were no difference between the conditions, you would obtain results as extreme as those you obtained (18 out of 23 successes, or failures) or more extreme 1.1% of the time. So, it’s unlikely that there is no difference between these two conditions. Let’s check out the binomial probability calculator on the web to see if we get the same result: http://faculty.vassar.edu/~lowry/binom_stats.html Your N here is 23; your k is 18, and p is .5. When you calculate the results, you find that the probability of 18 or more successes is 0.00531. If you multiply this by 2, you will get .011, the same result as in SPSS. Why is the value that the web calculator finds half of the SPSS value? The answer lies in the fact that SPSS gives a 2-tailed probability value. That is, SPSS gives you the probability of finding 18 or more successes or 18 or more failures (5 or fewer successes). Because the binomial distribution is symmetrical when p is .5, these two scenarios are equally likely. Normal Approximation to the Binomial As you know, you can use the normal approximation to the binomial distribution to find the probability that you would find a certain number of successes (or a more extreme number). To do this, you need to obtain a z score for the number of successes obtained (18 out of 23 trials). In order to do this, you need to know both the mean (expected value) and the standard deviation of the population. Mean = np = 23 * .5 = 11.5 Standard Deviation = sqrt (npq) = sqrt (23 * .5 * .5) = 2.40 Your z score is: 18 – 11.5 = 2.71 2.4 Looking at the probabilities under the normal curve in the back of your textbook, you will find that the probability of having this number of successes, or more, is .0034. This is relatively close to the .0053 value we found through the calculator. What if you were to use the correction for continuity? If you used the correction for continuity (which is typically used for samples of size N=20 or less), you would use the score of 17.5 (the lower real limit of the interval containing 18) in the calculation of your z-value. Here is what you would get: z score is: 17.5 – 11.5 = 2.50 2.4 The area under the normal curve beyond a z value beyond 2.5 is .0062. This is even closer to the value that we would expect. You can see that the normal approximation to the binomial distribution is a fairly accurate way of determining the probability of obtaining a certain number of successes. Now, it’s your turn to do a binomial test. The assignment begins on the following page. Assignment You have conducted a cognitive psychology experiment in which you are interested in how subjects react to being “primed” with a word that is relevant to the target word to which they respond. You measure their reaction time to the target word and obtain the following data: Subject 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Primed 430 440 520 500 400 480 420 520 600 500 540 480 520 420 Not Primed 450 440 580 420 500 500 440 680 650 480 590 580 560 480 Now, you should determine if there is an effect of priming. Analyze and interpret the data. For extra credit, use the normal approximation to the binomial distribution in addition to your test. You should indicate: 1) Whether or not there is an effect of priming (if so, the reaction time should be less for priming, indicating that they responded quicker in the primed condition). 2) How you made your decision (what test you used, what was the likelihood of obtaining these results or those more extreme, etc.) 3) Include your SPSS printout or hand calculations for the data.