

Document
... Modified – The cache line has been modified and is different from main memory – This is the only cached copy. (cf. ‘dirty’) Exclusive – The cache line is the same as main memory and is the only cached copy Shared - Same value as main memory but copies may exist in other caches. Invalid - Lin ...
... Modified – The cache line has been modified and is different from main memory – This is the only cached copy. (cf. ‘dirty’) Exclusive – The cache line is the same as main memory and is the only cached copy Shared - Same value as main memory but copies may exist in other caches. Invalid - Lin ...

Tests e supporto per l’ENEA GRID
... HPL TEST • HPL measures the floating point execution rate for solving a sistem of linear equations AX = B • HPL requires the availibility of MPI and libraries for linear algebra (BLAS, VSIPL, ATLAS) • HPL is scalable: parallel efficiency constant with respect to the processor memory usage ...
... HPL TEST • HPL measures the floating point execution rate for solving a sistem of linear equations AX = B • HPL requires the availibility of MPI and libraries for linear algebra (BLAS, VSIPL, ATLAS) • HPL is scalable: parallel efficiency constant with respect to the processor memory usage ...

SiCortex Technical Summary
... Engine, the fabric switch, and the fabric links. The DMA Engine connects the memory system to the fabric switch, and implements the processors’ software interface to the fabric. The fabric switch forwards traffic between incoming and outgoing links, and to and from the DMA Engine. The fabric links, ...
... Engine, the fabric switch, and the fabric links. The DMA Engine connects the memory system to the fabric switch, and implements the processors’ software interface to the fabric. The fabric switch forwards traffic between incoming and outgoing links, and to and from the DMA Engine. The fabric links, ...

Massively Parallel Processor (MPP) Architectures
... (C) 2001 Mark D. Hill from Adve, Falsafi, Lebek, Reinhardt & Singh ...
... (C) 2001 Mark D. Hill from Adve, Falsafi, Lebek, Reinhardt & Singh ...

XC858
... application by integrating a MultiCAN controller which support CAN (V2.0B). The on chip CAN module reduces the CPU load by performing most of the functions required by the networking protocol (masking, filtering and buffering of CAN frames). ...
... application by integrating a MultiCAN controller which support CAN (V2.0B). The on chip CAN module reduces the CPU load by performing most of the functions required by the networking protocol (masking, filtering and buffering of CAN frames). ...

PPT
... ° Divergence between memory capacity and speed even more pronounced • Capacity increased by 1000x from 1980-95, speed only 2x • Gigabit DRAM by c. 2000, but gap with processor speed much greater ...
... ° Divergence between memory capacity and speed even more pronounced • Capacity increased by 1000x from 1980-95, speed only 2x • Gigabit DRAM by c. 2000, but gap with processor speed much greater ...

CHAPTER 2. Hardware Spec of DSN-5750
... - Intelligent request reordering for maximum AGP bus utilization - Supports Flush/Fence commands - Graphics Address Relocation Table (GART) - Independent GART lookup control for host / AGP / PCI master accesses - Windows 95 OSR-2 VXD and integrated Windows 98 / NT5 miniport driver support Concurrent ...
... - Intelligent request reordering for maximum AGP bus utilization - Supports Flush/Fence commands - Graphics Address Relocation Table (GART) - Independent GART lookup control for host / AGP / PCI master accesses - Windows 95 OSR-2 VXD and integrated Windows 98 / NT5 miniport driver support Concurrent ...

Performance best practices
... The percentage of time that a vCPU is ready to execute, but waiting for physical CPU time ...
... The percentage of time that a vCPU is ready to execute, but waiting for physical CPU time ...

HPCC - Chapter1
... low start up times but inefficient as message size grows network device itself initiate the transfer need a bit more: can swap anytime ? Is it running? DMA1 : data copy DMA2 : insert queue DMA3 : NI sets up a DMA transfer to read the msg data from memory ...
... low start up times but inefficient as message size grows network device itself initiate the transfer need a bit more: can swap anytime ? Is it running? DMA1 : data copy DMA2 : insert queue DMA3 : NI sets up a DMA transfer to read the msg data from memory ...

ppt
... • Memory operations from a proc become visible (to itself and others) in program order • There exists a total order, consistent with this partial order - i.e., an interleaving – the position at which a write occurs in the hypothetical total order should be the same with respect to all processors ...
... • Memory operations from a proc become visible (to itself and others) in program order • There exists a total order, consistent with this partial order - i.e., an interleaving – the position at which a write occurs in the hypothetical total order should be the same with respect to all processors ...

word
... In questions 19-22, let there be 2 sectors in a track and 4 tracks and a single surface in a disk. Assume the following blocks are accessed by the file system; the notation is 1-digit for block number, and 1 digit for operation (Read, Write, or Append): 1A, 2A, 3A, 4A, 5A, 1R, 1W, 1R. Assume that al ...
... In questions 19-22, let there be 2 sectors in a track and 4 tracks and a single surface in a disk. Assume the following blocks are accessed by the file system; the notation is 1-digit for block number, and 1 digit for operation (Read, Write, or Append): 1A, 2A, 3A, 4A, 5A, 1R, 1W, 1R. Assume that al ...
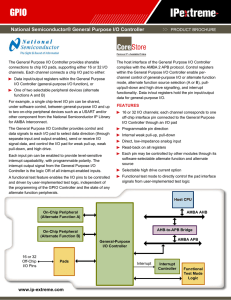
General-Purpose I/O Controller Brochure
... mode, alternate function source selection (A or B), pullup/pull-down and high drive signalling, and interrupt functionality. Data in/out registers hold the pin input/output data for general-purpose I/O. ...
... mode, alternate function source selection (A or B), pullup/pull-down and high drive signalling, and interrupt functionality. Data in/out registers hold the pin input/output data for general-purpose I/O. ...

Copilot - a Coprocessor-based Kernel Runtime Integrity Monitor Timothy Fraser
... PCI Local Bus CPU cache bridge/ memory controller ...
... PCI Local Bus CPU cache bridge/ memory controller ...


PPT - National Taiwan University
... protocol is invoked if an “access fault” occurs on the line Different approaches distinguished by (a) to (c) ...
... protocol is invoked if an “access fault” occurs on the line Different approaches distinguished by (a) to (c) ...


Computer-System Architecture Computer
... indicating its type, address, and state. Operating system indexes into I/O device table to determine device status and to modify table entry to include interrupt. ...
... indicating its type, address, and state. Operating system indexes into I/O device table to determine device status and to modify table entry to include interrupt. ...

ppt
... Guest OS runs in supervisor mode Access to a “supervisor” memory segment No privileged mode or physical memory access Virtual processors time shared across physical Data structure stored for each Virtual processor Process state,TLB Privileged mode instructions trap to disco monitor for ...
... Guest OS runs in supervisor mode Access to a “supervisor” memory segment No privileged mode or physical memory access Virtual processors time shared across physical Data structure stored for each Virtual processor Process state,TLB Privileged mode instructions trap to disco monitor for ...

NP_ch04
... Arrange for store of zero to address D to stop disk Arrange for fetch from address D+1 to return current status Note: effect of store to address D+1 can be defined as ...
... Arrange for store of zero to address D to stop disk Arrange for fetch from address D+1 to return current status Note: effect of store to address D+1 can be defined as ...
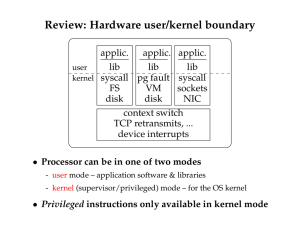
Network Interface Cards - Stanford Secure Computer Systems Group
... • CPU accesses physical memory over a bus • Devices access memory over I/O bus with DMA • Devices can appear to be a region of memory ...
... • CPU accesses physical memory over a bus • Devices access memory over I/O bus with DMA • Devices can appear to be a region of memory ...

Mid Semester Presentation - High Speed Digital Systems Laboratory
... Block Diagram – First Step Simple CAN application : The user pushes a button. the CAN controller decides which of the two CAN devices (#1 or #2) gets to send a massage on the bus, and the result is shown in the LEDs (LED<0> for device #1, LED<1> for device #2) ...
... Block Diagram – First Step Simple CAN application : The user pushes a button. the CAN controller decides which of the two CAN devices (#1 or #2) gets to send a massage on the bus, and the result is shown in the LEDs (LED<0> for device #1, LED<1> for device #2) ...

DS80C400-FCS - Maxim Integrated Products, Inc.
... The DS80C400 is a fast 8051-compatible microcontroller. The redesigned core executes 8051 instructions up to 3 times faster than the original for the same crystal speed. The DS80C400 supports a maximum crystal speed of 50 MHz, resulting in a minimum instruction cycle time of 80 ns. The DS80C400 util ...
... The DS80C400 is a fast 8051-compatible microcontroller. The redesigned core executes 8051 instructions up to 3 times faster than the original for the same crystal speed. The DS80C400 supports a maximum crystal speed of 50 MHz, resulting in a minimum instruction cycle time of 80 ns. The DS80C400 util ...

Generating a Quick and Controlled Waveform With the DAC
... operating as a 32-bit bus master connected to the system bus. The programming model is accessed through a 32-bit connection with the slave peripheral bus. DMA data transfers may be explicitly initiated by software or by peripheral hardware requests. The terms peripheral request and DREQ refer to a D ...
... operating as a 32-bit bus master connected to the system bus. The programming model is accessed through a 32-bit connection with the slave peripheral bus. DMA data transfers may be explicitly initiated by software or by peripheral hardware requests. The terms peripheral request and DREQ refer to a D ...
Direct memory access

Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system (RAM) memory independently of the central processing unit (CPU).Without DMA, when the CPU is using programmed input/output, it is typically fully occupied for the entire duration of the read or write operation, and is thus unavailable to perform other work. With DMA, the CPU first initiates the transfer, then it does other operations while the transfer is in progress, and it finally receives an interrupt from the DMA controller when the operation is done. This feature is useful at any time that the CPU cannot keep up with the rate of data transfer, or when the CPU needs to perform useful work while waiting for a relatively slow I/O data transfer. Many hardware systems use DMA, including disk drive controllers, graphics cards, network cards and sound cards. DMA is also used for intra-chip data transfer in multi-core processors. Computers that have DMA channels can transfer data to and from devices with much less CPU overhead than computers without DMA channels. Similarly, a processing element inside a multi-core processor can transfer data to and from its local memory without occupying its processor time, allowing computation and data transfer to proceed in parallel.DMA can also be used for ""memory to memory"" copying or moving of data within memory. DMA can offload expensive memory operations, such as large copies or scatter-gather operations, from the CPU to a dedicated DMA engine. An implementation example is the I/O Acceleration Technology.