
Anomaly Detection Algorithms by Andrew Weekley
... • optimal clusters in time domain and delay space • build a “feature” in the time domain from optimal clusters in the time domain • drop-out and non-stationary cases have two optimal clusters in delay space, but distinct representations in the time domain. • nominal, block and uniform cases have sin ...
... • optimal clusters in time domain and delay space • build a “feature” in the time domain from optimal clusters in the time domain • drop-out and non-stationary cases have two optimal clusters in delay space, but distinct representations in the time domain. • nominal, block and uniform cases have sin ...

PDF
... Interpretation: The Normal probability plot is quite linear, so it is reasonable to believe that the data follow a Normal distribution. ...
... Interpretation: The Normal probability plot is quite linear, so it is reasonable to believe that the data follow a Normal distribution. ...


Chapter 15
... 3. Differences analysis: used to compare the mean of the responses of one group to that of another group 4. Associative analysis: determines the strength and direction of relationships between two or more variables Ch 15 ...
... 3. Differences analysis: used to compare the mean of the responses of one group to that of another group 4. Associative analysis: determines the strength and direction of relationships between two or more variables Ch 15 ...




2016-2017 VOCABULARY 2-Operations with Rational Numbers and
... that is ordered from least to greatest. If there is an even number of items in the data set, the median is the average of the two middle numbers. ...
... that is ordered from least to greatest. If there is an even number of items in the data set, the median is the average of the two middle numbers. ...

Vocabulary
... Histogram (A graphical representation of a numerical data set that has been grouped into intervals. Each interval is represented by a bar drawn above that interval that has a height corresponding to the number of observations in that interval.) ...
... Histogram (A graphical representation of a numerical data set that has been grouped into intervals. Each interval is represented by a bar drawn above that interval that has a height corresponding to the number of observations in that interval.) ...






Quadratic Functions
... graphing utility. If you are doing it by hand, scales for the x (independent) variable and the y (dependent) variable will need to be chosen so that the data is spread out enough to make the trend recognizable. Analyzing the data for a trend After creating the scatterplot it is necessary to analyze ...
... graphing utility. If you are doing it by hand, scales for the x (independent) variable and the y (dependent) variable will need to be chosen so that the data is spread out enough to make the trend recognizable. Analyzing the data for a trend After creating the scatterplot it is necessary to analyze ...



Chapter Three Day Six
... Laboratories use regression to calibrate such techniques. The data below show the results of five measurements for each of four amounts of the substance being investigated. The explanatory variable x is the amount of the substance in the specimen, measure in nanograms (10 -9 gram). The response vari ...
... Laboratories use regression to calibrate such techniques. The data below show the results of five measurements for each of four amounts of the substance being investigated. The explanatory variable x is the amount of the substance in the specimen, measure in nanograms (10 -9 gram). The response vari ...
Summary: Differences between univariate and bivariate data.
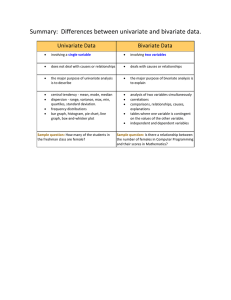
... correlations comparisons, relationships, causes, explanations tables where one variable is contingent on the values of the other variable. independent and dependent variables ...
... correlations comparisons, relationships, causes, explanations tables where one variable is contingent on the values of the other variable. independent and dependent variables ...



STATISTICS For Research - John C. Fremont High School
... 1. Quantitatively describe and summarize data ...
... 1. Quantitatively describe and summarize data ...

Integrating Statistical Analysis with Visualization
... the sum of the squares of the vertical deviations from each data point to the line. • Coefficient of determination (R2 value) indicates how much of the total variation in y can be explained by the relationship between x and y. • Linear regression in D3: http://bl.ocks.org/benvandyke/8459843 ...
... the sum of the squares of the vertical deviations from each data point to the line. • Coefficient of determination (R2 value) indicates how much of the total variation in y can be explained by the relationship between x and y. • Linear regression in D3: http://bl.ocks.org/benvandyke/8459843 ...


Time series

A time series is a sequence of data points, typically consisting of successive measurements made over a time interval. Examples of time series are ocean tides, counts of sunspots, and the daily closing value of the Dow Jones Industrial Average. Time series are very frequently plotted via line charts. Time series are used in statistics, signal processing, pattern recognition, econometrics, mathematical finance, weather forecasting, intelligent transport and trajectory forecasting, earthquake prediction, electroencephalography, control engineering, astronomy, communications engineering, and largely in any domain of applied science and engineering which involves temporal measurements.Time series analysis comprises methods for analyzing time series data in order to extract meaningful statistics and other characteristics of the data. Time series forecasting is the use of a model to predict future values based on previously observed values. While regression analysis is often employed in such a way as to test theories that the current values of one or more independent time series affect the current value of another time series, this type of analysis of time series is not called ""time series analysis"", which focuses on comparing values of a single time series or multiple dependent time series at different points in time.Time series data have a natural temporal ordering. This makes time series analysis distinct from cross-sectional studies, in which there is no natural ordering of the observations (e.g. explaining people's wages by reference to their respective education levels, where the individuals' data could be entered in any order). Time series analysis is also distinct from spatial data analysis where the observations typically relate to geographical locations (e.g. accounting for house prices by the location as well as the intrinsic characteristics of the houses). A stochastic model for a time series will generally reflect the fact that observations close together in time will be more closely related than observations further apart. In addition, time series models will often make use of the natural one-way ordering of time so that values for a given period will be expressed as deriving in some way from past values, rather than from future values (see time reversibility.)Time series analysis can be applied to real-valued, continuous data, discrete numeric data, or discrete symbolic data (i.e. sequences of characters, such as letters and words in the English language.).