Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
1
Lecture 19: Assessing the
Assumption of Normality
Sources of Information
Sokal & Rohlf Chapter 6 (sections 6.6 and 6.7)
2
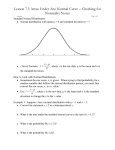
The Normal Distribution
The Normal distribution (also called Gaussian
distribution) is the single most important
distribution in statistics.
A continuous random variable has a Normal
distribution if that distribution is symmetric and
bell-shaped, and fits the formula:
You don’t need to know the formula!
What it shows is that any particular normal
distribution is determined by 2 parameters: the
mean () and the standard deviation ().
An infinite number of Normal curves can be
drawn by altering the mean and standard
deviation.
3
A Model for the Normal Distribution
We have learned that a large proportion of
biological variables approximate the Normal
distribution, because:
If many factors act independently and
additively, then the distribution will
approach Normality.
Conditions that tend to produce Normal
frequency distributions:
1. If there are many factors involved (single or
composite)
2. Factors are independent in their occurrence
3. If their effects are additive
4. If they make equal contributions to the
variance.
4
Applications of the Normal Distribution
It is the most widely used distribution in statistics.
Applications include:
1. To know whether a given sample is distributed
normally before we can apply a test to it
(Parametric statistics). Here, we have to calculate
expected frequencies for a Normal curve with the
same mean and SD as in our sample.
2. Knowing whether a sample is distributed normally
may confirm or reject a certain underlying
hypothesis about the nature of the factors affecting
the phenomenon studied (e.g., skewness,
bimodality, etc. tells a lot about control factors).
3. If we assume a given distribution to be Normal, we
may make predictions and tests of a given
hypothesis based upon this assumption. (Here we
calculate how many SD units a value is away from
the mean and turn this into a probability).
5
Overview of Methods
to Assess Normality
There are a large number of formal tests for
normality.
Increasingly, analysts are making use of graphical
methods.
Graphical Methods
Histogram (density plot)
Quantile plot
Normal probability plot
(or, Normal-quantile plot)
Formal Tests
Skewness & Kurtosis
6
Frequency Histograms
Frequency histograms (also called density plots) can
be extremely useful for displaying the characteristics
of a dataset.
They are easily produced in most statistical
programs.
BUT, they are a poor tool to objectively assess
Normality.
The problem is that the shape of a histogram is
usually a function of the number and width of the
bars, particularly in small samples.
Example:
Summary of
Count
Mean
Median
MidRange
StdDev
Min
Max
Range
Interorbital width in pigeons
40
11.48
11.6
11.75
0.691783
10.2
13.3
3.1
7
These data are approximately Normally distributed
But, our visual detection depends on the number
and width of bars.
So, in general, histograms should not be used to
examine the hypothesis of Normality for a dataset.
8
Quantile Plots
A quantile plot provides an excellent and reliable
alternative to histograms.
A 1-sample quantile plot compares a variable to its
own quantiles.
A quantile = The value at which the fraction of the
data points are to it (the quantile).
e.g., the 0.25 quartile contains the smallest 25% of
the data points (= quartile),
The 0.5 quartile contains the smallest 50% of the data
points (= median), etc.
9
If the data are normally distributed, a 1-sample
quantile plot should form an S-shaped curve, called a
sigmoid.
Fig. 6.3 shows the cumulative frequency of a
normal distribution.
Fig. 6.5 shows the quantiles expressed in standard
deviation units from the mean. These are called
Normal equivalent deviates (NEDs). These are the
same as nscores obtained from DataDesk. They are
used in Normal probability plots, or Normalquantile plots.
10
Normal Probability Plots
A Normal probability plot provides a simple way to
tell whether the values in a variable are
approximately Normally distributed.
If a plot of the data points of a variable versus the
nscores (or NEDs) fall on a straight line (or nearly
straight line), then the distribution of the variable is
nearly normal.
12
An Example of Skewed Data
13
Notes on Normal Probability
Plots
If you find yourself wondering whether the
data in a Normal probability plot exhibit
evidence of non-Normality, then you probably
don’t have a sufficiently severe violation to
worry about.
If the violation of the Normality assumption is
enough to be worrisome, it will be readily
apparent in the Normal probability plot.
Usually we are only interested in severe
violations of the Normality assumption. The
central-limit theorem gives us confidence that
even for severely non-normal distributions,
statistics such as means will tend to be
Normally distributed.
Since we are usually interested in the
distributions of statistics (such as means) and
not so much in the distributions of the raw
data, mild departures from Normality are of
little concern.
14
Small Samples
Normal probability plots work best for fairly
large samples (n > 50).
Assessing the Normality assumption in small
samples is problematic. In smaller samples, a
difference of one item per class (in a
histogram) would make a substantial
difference in the cumulative percentage in the
tails of a distribution.
For small samples (<50), the method of
Rankits is preferable.
With this method, instead of quantiles, we use
the ranks of each observation in the sample,
and instead of nscores we plot values from a
table of rankits = the average positions in SD
units of the ranked items in a Normally
distributed sample of n items.
I have never seen rankits used in the scientific
literature. If you need to use the method, refer
to Box 6.3 in Sokal & Rohlf.
15
Formal Tests – Skewness and
Kurtosis
We learned before that distributions can deviate from
Normality due to Skewness and Kurtosis. Thus,
statistics that measure these departures can be useful.
1. Skewness (= asymmetry): means that 1 tail of the
curve is drawn out more than the other.
Distributions can be skewed to the right or the left.
2. Kurtosis describes the proportions of observations
found in the centre and in the tails in relation to
those found in the shoulders.
A leptokurtic curve has more items in the centre
and at the tails, with fewer items in the shoulders
relative to a Normal distribution with the same
mean and variance.
A platykurtic curve has fewer items at the centre
and tails, but has more in the shoulders. A bimodal
distribution is an extreme platykurtic distribution.
16
We can use sample statistics for measuring skewness
and kurtosis, called g1 and g2, to represent the
population parameters 1 and 2.
Their computation is tedious and should be done with
a computer.
In DataDesk, you get these values together with the
{Summary Statistics}.
They are not included with the defaults, so you must
select them: Choose: {Calc} {Summary Options}
Select {Moments} “Skewness” and “Kurtosis”.
Then the values appear when you choose: {Calc}
{Summaries} {Reports}.
In a population with a Normal distribution, both 1
and 2 = 0.
A negative g1 indicates skewness to the left, and
positive g1 skewness to the right.
A negative g2 indicates platykurtosis, a positive g2
indicates leptokurtosis.
17
Examples from DataDesk
The absolute values of g1 and g2 do not mean much,
these statistics have to be tested for significance.
18
Testing Hypotheses about g1 and g2
We use the general test for significance of any
sample statistic.
ts = St – Stp
SSt
Where,
St is a sample statistic
Stp is the parametric value against which the
sample statistic is to be tested.
SSt is the estimated standard error
To calculate the standard error (SSt):
Sg1 =
Sg2 =
d.f. =
19
The Hypothesis Test
The Ho is that the distribution is not skewed – that is
that 1 = 0.
It is a 2-tailed test because g1 can be either negative
or positive and we wish to test whether there is any
skewness. Thus,
Step 1: Ho: 1 = 0 Ho: 1 0
Step 2: If we want to test this using sample data with
g1 = 0.18936 and n = 9456:
ts
= (g1 - 1)
Sg1
= 0.18936 – 0
SQRT(6/9456)
= 0.1893
0.02517
= 7.52
20
Step 3: We use the critical t-value with d.f. =
t.05, = 1.960
t.01, = 2.576
t.001, = 3.291
Therefore, ts = 7.52 has P << 0.001. Thus we reject
the null hypothesis and conclude that 1 0. Since g1
is positive, we conclude that the data are significantly
skewed to the right.