Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
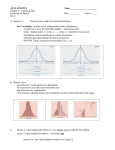
PHYSICS 1A WEEK #1 LAB EXPERIMENTAL ERRORS INTRODUCTION The verification of a physical law usually depends on some form of measurement of a physical quantity. All experimenters need to have a common standard of basic units (e.g. mass, length and time) so that measurements made in California can be compared to those made in Rio de Janeiro, Moscow or on Mars. For this class we will assume these standard units are the MKS system. Now we will address how well a measurement can be made. The uncertainty in a measurement is frequently as important as the measurement itself. This uncertainty is referred to as the error of the measurement. This does NOT mean a mistake, but tells you the fundamental limits of the measurement, which result sometimes from the techniques used, and sometimes from fundamental principles such as the uncertainty principle of quantum mechanics. (Of course any one of us may also make a mistake eg reading 7.5 cm instead of 8.5 cm on the ruler. We hope that good experimental technique will help you find and remove these oopses). Suppose a lab class of 30 students is given a fork from the cafeteria. They pass it around and each student is asked to measure and record the length of the fork. All the measurements are then presented on the blackboard for comparison. What would you expect to see? Some students will reach for their 99c rulers and try to read the length to the nearest millimeter. Some may use inches and convert. Some may borrow the meter stick in the corner of the lab. The values will probably be close but not identical. We will assume you can identify and remove any mistakes from the data set There will be 2 types of errors: random errors and systematic errors. The systematic errors result from using a faulty ruler (Did you leave that plastic ruler on the dashboard of your car on a sunny day, or put it through the dryer in the pocket of your pants? In general systematic errors result from making measurements with instruments whose calibration, that is comparison to standards of mass, length and time, is poor or unknown.) The random errors result from the small differences in readings that would happen if everyone used the same ruler. Random errors tend to form a cluster around a most common value. The number of measurements in a given length interval will be peaked at this most common value. These measurements will form a random distribution also called a normal distribution. There is an entire field of study devoted to the statistical analysis of data. This lab will be your introduction to this work. We will try to help you gain familiarity with the treatment of random errors through practice with the normal distribution. We will also look at how systematic errors arise and influence our results. EXPERIMENT In this experiment we will drop popcorn kernels onto a plate marked into 8 equal sections. We should find the average number of kernels that land on a section and the frequency at which this happens compared to scoring other counts of kernels/section. We are creating a probability distribution. Page - 1 - PHYSICS 1A WEEK #1 LAB EXPERIMENTAL ERRORS The variable x is the number of popcorn kernels that land on one sector of a platter after a free fall and some bouncing.* Its distribution p(x) is the number of times x occurs, the number of occurrences p(x) of the variable x: how many sectors p(1) on the platter contain x = 1 kernel, how many contain 2, etc. 1. Put a handful of kernels into the funnel, holding your finger over the bottom so they don’t fall out. Hold the funnel above the center of the platter and let the popcorn fall. Practice a few times, adjusting the height of the funnel until about three-quarters of the popcorn remain on the platter. For best results use between 50 and 100 kernels. After each attempt gather them all up and use the same number for each successive try. 2. Make a table to record the number of the run and the number of kernels remaining on the platter. Prepare a graph whose horizontal axis (a.k.a. abscissa) is the number of kernels per sector (the variable x), and whose vertical axis (a.k.a. ordinate) is the number of times, p(x) = 1, 2, 3, 4, etc., this was observed. The practice runs should give you an idea of the appropriate numbers to use on the abscissa. 3. Drop the first handful of kernels as run number 1. Count all the kernels that remain on the platter and enter into the table. Tally occurrences, e.g. 2 sectors with 5 kernels in each, 3 sectors with 8 kernels in each, etc., and shade in your graph accordingly: a rectangle p(5) = 2 units high above the x = 5 on the abscissa, one 3 units high above the 8, etc. Repeat until you have shaded most of the page. Your plot should look something like this. # of occurrences 0 1 2 3 4 5 6 7 8 9 Kernels/sector ANALYSIS AND DISCUSSION 1. The Average. From your data compute x , the average number of kernels per sector. Hint: You can do this the hard way or the easy way, it is up to you. 2. The Median. The median xm of a distribution p(x) is that value of the variable such that half the occurrences p(x) occur at values x below xm. In this instance, half the sectors on the platter contain less than xm kernels. To calculate the median of your distribution, start from one end of the graph and simply add occurrences p(x) until half the total number of occurrences is reached. The value of the variable at which this happens is the median. You may have to split the last column of the graph to be added. The total number of occurrences N, a.k.a. the * Though the trajectory of each kernel, and hence its end point (that is, where it lands), is completely determined by the laws of mechanics (as you will learn in this class), the fact that said trajectory depends so exquisitely on initial conditions (that is, on exactly how the kernel is released), which initial conditions we do not attempt to control totally, nor even to know, results in a random distribution of end points. Simply put, dropping popcorn is throwing dice. Page - 2 - PHYSICS 1A WEEK #1 LAB EXPERIMENTAL ERRORS number of tries, is simply the total number of runs times the total number of sectors on the platter. The average and the median of a symmetric distribution are equal. Your distribution is probably a symmetric bell curve, called a normal distribution. As you make more runs your distribution will get smoother and become more like a normal distribution. Draw and justify an imaginary distribution whose average is a) less than, b) more than its median. Give and justify one plausible example of each from real life. 3. The Standard Deviation. Those of you who are mathematically inclined may want to refer to the mathematical appendix to this lab. The standard deviation of a distribution, usually denoted σ, is a measure of the spread of the variable about its average value. To obtain the standard deviation of your distribution, first draw a smooth curve through the tops of the columns you have shaded. Then measure the height p( x ) of the distribution at its average x . Draw a horizontal line through the graph at 0.61 times this height above the horizontal axis. This line cuts the smooth curve at two points, whose abscissa xlow and xhigh straddle the average: xlow < x < xhigh. The difference xhigh xlow is the standard deviation of the distribution. In a normal distribution 68% of occurrences fall within one standard deviation (± σ) of the average, 95.4% within two standard deviations, and 99.7% within three. Verify these percentages on your distribution. If the same experiment were performed a) by a person with Parkinson's Disease, b) on a platter tilted from the horizontal, would you expect the average, the median, the standard deviation, to be smaller than, comparable to, or greater than those of your distribution? Explain. 4. Below are ten measurements of a certain dimensionless quantity x: 2.0, 2.5, 2.2, 2.6, 2.4, 2.4, 2.3, 2.5, 2.3, 2.4 Just by looking at these numbers give an eyeball estimate of their “spread”. Plot this distribution and calculate its average, median and standard deviation as you have done with the popcorn. How does the average compare to the median? Does this distribution look like a normal one? Calculate the standard deviation by the formula: (x σ= i x )2 N 1 The summation Σ goes over all the ten values xi from i = 1 to i = N = 10. Compare the two values of σ, from the plot of the distribution and from the formula. Compare these two values to your eyeball “spread”, how close was your guess to the rigorous evaluations? Suppose the eleventh measurement was 3.2, what would you do with it? Given the standard deviation you have computed what is the probability that you would get a result as large as 3.2? 5. "There are three kinds of lies: lies, damned lies and statistics." (Quote attributed to English politician Disraeli in Mark Twain's autobiography) Comment! Do you think that the statistics of samples are adequately discussed in popular reporting of political races, or in other situations of social importance? Page - 3 - PHYSICS 1A WEEK #1 LAB EXPERIMENTAL ERRORS MATHEMATICAL APPENDIX If the "true" value of a quantity is X, and the standard deviation of the distribution is then the smooth curve for the normal distribution has the mathematical form ( x X ) 2 1 f ( x) e 2 2 2 f(x) Normal distribution Area under curve = 1.0 Max probability 1 2 0.61*max x=X x mean value Note that the peak value occurs at x = X, and this value is f ( x) 1 2 . The half width of the function at a height of 0.61 of the max is , the standard deviation. You may also see the same function referred to as a Gaussian distribution. The rather strange normalizing factor of 1 is set so that the area under the curve is unity. Hence you 2 can find the probability of an event falling within a certain range of the mean value of X by integrating the function (finding the area under the curve). For example the probability of getting a value between x and x is the area shown between the 2 dotted lines, which is 0.68 or 68%. If you extend the integral to 2 from the mean you get a larger area and a larger probability of occurrence (0.954). Page - 4 -