Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Distributed firewall wikipedia , lookup
Airborne Networking wikipedia , lookup
Recursive InterNetwork Architecture (RINA) wikipedia , lookup
Service-oriented architecture implementation framework wikipedia , lookup
Peer-to-peer wikipedia , lookup
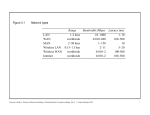
Slides for Chapter 10: Peer-to-Peer Systems From Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edition 4, © Addison-Wesley 2005 Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 1 Introduction Peer-to-peer systems share these characteristics Each system share resources They may unique or duplicate Correct operation does not depends on any server Limited degree Algorithms for placing resources Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 2 Figure 10.1: Distinctions between IP and overlay routing for peer-to-peer applications Scale Load balancing Network dynamics (addition/deletion of objects/nodes) Fault tolerance Target identification Security and anonymity IP Application-level routing overlay IPv4 is limited to 2pow32 addressable nodes. The IPv6 name space is much more generous (2pow128), but addresses in both versions are hierarchically structured and much of the space is pre-allocated according to administrative requirements. Loads on routers are determined by network topology and associated traffic patterns. Peer-to-peer systems can address more objects. The GUID name space is very large and flat (>2pow128), allowing it to be much more fully occupied. Object locations can be randomized and hence traffic patterns are divorced from the network topology. IP routing tables are updated asynchronously on Routing tables can be updated synchronously or a best-efforts basis with time constants on the asynchronously with fractions of a second order of 1 hour. delays. Redundancy is designed into the IP network by Routes and object references can be replicated its managers, ensuring tolerance of a single n-fold, ensuring tolerance of n failures of nodes router or network connectivity failure. n-fold or connections. replication is costly. Each IP address maps to exactly one target Messages can be routed to the nearest replica of node. a target object. Addressing is only secure when all nodes are Security can be achieved even in environments trusted. Anonymity for the owners of addresses with limited trust. A limited degree of is not achievable. anonymity can be provided. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 3 Napster and its legacy Napster is file sharing system which provides a means for users to share files. The first application in which a demand for a globally-scalable information storage and retrieval service emerged was the downloading of digital music files. Napster became very popular for music exchange after its launch in 1999. Several million users were registered and thousands were swapping music files simultaneously. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 4 Napster and its legacy Napster architecture included centralized indexes but users supplied the files, which were stored and accessed on their personnel systems. Napster method of operation as follows in step by step. 1.File location Request 2.List of peers offering the files 3.File request 4.File delivered 5.Index update Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 5 Figure 10.2: Napster: peer-to-peer file sharing with a centralized, replicated index peers Napster serv er Index 1. Fil e lo cation req uest 2. Lis t of pee rs offerin g th e fi le Napster serv er Index 3. Fil e req uest 5. Ind ex upd ate 4. Fil e de livered Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 6 Napster and its legacy Napster used a (replicated) unified index of all available music files. Object discovery and addressing is likely to become a bottleneck. Music files are never updated, avoiding any need to make all the replicas of file consistent after updates. No guarantees are require concerning the availability of individual files – if a music file is temporarily unavailable, it can be downloaded later when it available. This reduces the requirement for dependability of individual computers and their connections to the internet. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 7 Peer-to-Peer middleware A key problem in the design of peer-to-peer applications is to provide a mechanism to enable clients to access data resources quickly and dependably wherever they are located throughout the network. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 8 Peer-to-Peer middleware Middleware layers for the application-independent management of distributed resources on a global scale. Several research teams have completed peer-to-peer middleware platforms Example: Pastry, Tapestry, CAN, Chord and Kademlia These platforms are designed to place resources on a set of computers that are widely distributed throughout the internet. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 9 Peer-to-Peer middleware Functional requirements The function of peer-to-peer middleware is to simplify the constructions of services that are implemented across many hosts in a widely distributed network. Other important requirement includes the ability to add new resources and to remove them at will and to add hosts to the service and remove them. Like other middleware, peer-to-peer middleware should offer simple programming interface. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 10 Peer-to-Peer middleware Non-functional requirements To perform effectively, peer-to-peer middleware must also address the following non-functional requirements. 1.Global scalability: peer-to-peer middleware must therefore be designed to support applications that access millions of objects on tens of thousands of hundreds of thousands of hosts. 2.Load balancing: the performance of any system designed to exploit a large number of computers depends upon the balanced distribution of workload across them. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 11 Peer-to-Peer middleware 3.Optimizationf for local interactions between neighboring peers: the middle ware should aim to place resources close to the nodes that access them the most. 4.Accommodating to highly dynamic host availability: Peer-to-peer systems are constructed from host computers that are free to join or leave the system at any time. 5.Security of data in an environment with heterogeneous trust: use of authentication and encryption mechanisms to ensure the integrity and privacy of information. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 12 Peer-to-Peer middleware 6.Anonymity, deniability and resistance to censorship: A related requirement is that the hosts that hold data should be able plausibly to deny responsibility for holding or supplying it. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 13 Peer-to-Peer middleware The design of a middleware layer to support global-scale peer-to-peer systems is therefore a difficult problem. Knowledge of the locations of objects must be partitioned and distributed throughout the network. In a network each node responsible for maintaining detailed knowledge of the locations of nodes and objects in a portion of the name space as well as a general knowledge of the topology of the entire name space. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 14 Figure 10.3: Distribution of information in a routing overlay AХs rou ting kn owledg e DХs routi ng knowle dge C A D B Obje ct: Node : BХs routing kno wl edge CХs routi ng knowle dge Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 15 Routing overlays A distributed algorithm known as a routing overlay takes responsibility for locating nodes and objects. The GUID used to identify nodes and objects are an example of the pure name also known as opaque identifiers, since they reveal nothing about the locations of the objects to which they refer. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 16 Routing overlays The main tasks of routing overlay 1. Routs the request to a node at which a replica of the object resides. The routing overlay must also perform some other tasks: 1. To make a new object available to a peer-to-peer service computes a GUID for the object and announces it to the routing overlay. 2. When clients request the removal of objects from the service the routing overlay must make them unavailable. 3. Nodes may join and leave the service. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 17 Figure 10.4: Basic programming interface for a distributed hash table (DHT) as implemented by the PAST API over Pastry put(GUID, data) The data is stored in replicas at all nodes responsible for the object identified by GUID. remove(GUID) Deletes all references to GUID and the associated data. value = get(GUID) The data associated with GUID is retrieved from one of the nodes responsible it. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 18 Figure 10.5: Basic programming interface for distributed object location and routing (DOLR) as implemented by Tapestry publish(GUID ) GUID can be computed from the object (or some part of it, e.g. its name). This function makes the node performing a publish operation the host for the object corresponding to GUID. unpublish(GUID) Makes the object corresponding to GUID inaccessible. sendToObj(msg, GUID, [n]) Following the object-oriented paradigm, an invocation message is sent to an object in order to access it. This might be a request to open a TCP connection for data transfer or to return a message containing all or part of the object’s state. The final optional parameter [n], if present, requests the delivery of the same message to n replicas of the object. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 19 Overlay Case Studies: Pastry, Tapestry The prefix routing approach is adopted by both Pastry and Tapestry. Pastry All the nodes and objects that can be accessed through Pastry are assigned 128-bit GUIDs. For nodes, these are computed by applying a secure hash function (such as SHA-1) to the public key with which each node is provided. For objects such as files, the GUID is computed by applying a secure hash function to the object’s name or to some part of the object’s stored state. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 20 Overlay Case Studies: Pastry, Tapestry It will correctly route a message addressed to any GUID in O(log N) steps. Routing involves the use of an transport protocol (normally UDP) to transfer the message to a Pastry node that is ‘closer’ to its destination. It is fully self-organizing Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 21 Overlay Case Studies: Pastry, Tapestry Routing algorithm · The full routing algorithm involves the use of a routing table at each node to route messages efficiently Stage I: simplified form of algorithm. Stage II: The full Pastry algorithm and shows how efficient routing is achieved with the aid of routing tables. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 22 Figure 10.6: Circular routing alone is correct but inefficient Based on Rowstron and Druschel [2001] 0 FFFFF....F (2 128-1) D471 F1 D467 C4 D46A1C D13DA3 The dots depict live nodes. The space is considered as circular: node 0 is adjacent to node (2128-1). The diagram illustrates the routing of a message from node 65A1FC to D46A1C using leaf set information alone, assuming leaf sets of size 8 (l = 4). This is a degenerate type of routing that would scale very poorly; it is not used in practice. 65 A1FC Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 23 Figure 10.7: First four rows of a Pastry routing table Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 24 Figure 10.8: Pastry routing example Based on Rowstron and Druschel [2001] 0 FFFFF....F (2 128-1) Routing a mess age from node 65A1FC to D46A1C. With the aid of a w ell-populated routing table the mess age c an be deliv ered in ~ log16 (N ) hops. D471 F1 D46A1C D467 C4 D462 BA D421 3F D13DA3 65 A1FC Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 25 Overlay Case Studies: Pastry, Tapestry Tapestry Tapestry implements a distributed hash table and routes messages to nodes based on GUIDs associated with resources using prefix routing in a manner similar to Pastry. But Tapestry’s API conceals the distributed hash table from applications behind a DOLR interface. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 26 Figure 10.10: Tapestry routing From [Zhao et al. 2004] 43 77 (Root for 4378 ) Ta pestry routi ngs fo r 437 7 43 7A 43 FE pu blis h pa th 42 28 Lo cation mapp ing fo r 437 8 43 78 Phi lХs Boo ks 43 61 46 64 4A6D 4B4 F Routes a ctu ally ta ken by send(4378) E79 1 57 EC AA93 43 78 Phi lХs Boo ks Replic as of the file PhilХs Books(G=4378) are hos ted at nodes 4228 and AA93. Node 4377 is the root node for object 4378. The Tapes try routings s how n are s ome of the entries in routing tables. The publish paths show routes follow ed by the publish mes sages laying dow n c ac hed loc ation mappings for object 4378. The loc ation mappings are s ubsequently used to route mess ages s ent to 4378. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 27 Overlay Case Studies: Pastry, Tapestry Replicated resources are published with the same GUID. In Tapestry 160-bit identifiers are used to refer both to objects and to the nodes that perform routing actions. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 28 Application Case Studies: Squirrel, OceanStore Squirrel web cache The authors of Pastry have developed the Squirrel peer-to-peer web caching service for use in local networks of personal computers Web caching · Web browsers generate HTTP GET requests for Internet objects like HTML pages, images, etc. Squirrel · The Squirrel web caching service performs the same functions using a small part of the resources of each client computer on a local network. The SHA-1 secure hash function is applied to the URL of each cached object to produce a 128-bit Pastry GUID. Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 29 Application Case Studies: Squirrel, OceanStore The reduction in total external bandwidth used: The total external bandwidth is inversely related to the hit ratio, since it is only cache misses that generate requests to external web servers The latency perceived by users for access to web objects: The use of a routing overlay results in several message transfers (routing hops) across the local network to transmit a request from a client to the host responsible for caching the relevant object (the home node). The computational and storage load imposed on client nodes: The average number of cache requests served for other nodes by each node over the whole period of the evaluation was extremely low Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 30 Application Case Studies: Squirrel, OceanStore OceanStore The developers of Tapestry have designed and built a prototype for a peer-to-peer file store The design includes provision for the replicated storage of both mutable and immutable data objects Storage organization · OceanStore/Pond data objects are analogous to files, with their data stored in a set of blocks. But each object is represented as an ordered sequence of immutable versions that are kept forever. Any update to an object results in the generation of a new version. The versions share any unchanged blocks, following the copy-on-write technique for creating and updating objects Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 31 Figure 10.11: Storage organization of OceanStore objects AGUID BGUID (copy on write) VGUID of current version certificate version i+1 VGUID of version i d1 d2 d3 d2 d3 root block version i Version i+1 has been updated in blocks d1, d2 and d3. The certifi cate and the root bl ocks i ncl ude some metadata not shown. Al l unlabelled arrows are BGUIDs. indirection blocks data blocks d1 d4 d5 VGUID of version i-1 Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 32 Figure 10.12: Types of identifier used in OceanStore Name Meaning Description BGUID block GUID Secure hash of a data block VGUID version GUID BGUID of the root block of a version AGUID active GUID Uniquely identifies all the versions of an object Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 33 Instructor’s Guide for Coulouris, Dollimore and Kindberg Distributed Systems: Concepts and Design Edn. 3 © Addison-Wesley Publishers 2000 34