Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Chapter 14
Probabilistic Reasoning
1
Outlines
• Representing Knowledge in an Uncertain
Domain
• The semantics of Bayesian Networks
• Efficient Representation of Conditional
Distributions
• Exact inference in Bayesian Networks
• Approximate inference in in Bayesian
Networks
• Extending Probability to FOL representations
• Other approaches to Uncertain Reasoning 2
14-1
• Full joint probability distribution
– can answer any question about the domain, but can become
intractably large as the number of variables grows.
– Furthermore, specifying probabilities for atomic events is
rather unnatural and can be very difficult unless a large
amount of data is available from which to gather statistical
estimates.
• We also saw that independence and conditional
independence relationships among variables can
greatly reduce the number of probabilities that need
to be specified in order to define the full joint
distribution.
• This section introduces a data structure called a
Bayesian networks to represent the dependencies
among variables and to give a concise specification
of any full joint probability distribution.
3
Definition
A Bayesian network is a directed acyclic graph (DAG) which
consists of:
• A set of random variables which makes up the nodes of the
network.
• A set of directed links (arrows) connecting pairs of nodes. If there
is an arrow from node X to node Y, X is said to be a parent of Y.
• Each node Xi has a conditional probability distribution
P(Xi|Parents(Xi)) that quantifies the effect of the parents on the
node.
Intuitions:
• A Bayesian network models our incomplete understanding of
the causal relationships from an application domain.
• A node represents some state of affairs or event.
• A link from X to Y means that X has a direct influence on Y.
4
What are Bayesian Networks?
• Graphical notation for conditional
independence assertions
• Compact specification of full joint
distributions
• What do they look like?
– Set of nodes, one per variable
– Directed, acyclic graph
– Conditional distribution for each node given its
parents: P(Xi|Parents(Xi))
5
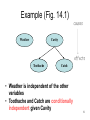
Example (Fig. 14.1)
Weather
causes
Cavity
effects
Toothache
Catch
• Weather is independent of the other
variables
• Toothache and Catch are conditionally
independent given Cavity
6
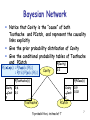
Bayesian Network
Notice that Cavity is the “cause” of both
Toothache and PCatch, and represent the causality
links explicitly
Give the prior probability distribution of Cavity
Give the conditional probability tables of Toothache
and PCatch
P(Cavity)
P(ctpc) = P(tpc|c) P(c)
= P(t|c) P(pc|c) P(c)
Cavity
0.2
P(Toothache|c)
Cavity
Cavit
y
P(PClass|c)
0.6
0.1
Cavity
Cavit
y
Toothache
0.9
0.02
PCatch
5 probabilities, instead of 7
7
Another Example
Sample Domain:
• You have a burglar alarm installed in your home.
It is fairly reliable at detecting a burglary, but also
responds on occasion to minor earthquakes.
• You also have to neighbors, John and Mary, who
have promised to call you at work when they
hear the alarm.
• John always calls when he hears the alarm, but
sometimes confuses the telephone ringing with
the alarm and calls then, too.
• Mary, on the other hand, likes rather loud music
and sometimes misses the alarm altogether.
8
Example
• I’m at work, neighbor John calls to say my
alarm is ringing, but neighbor Mary doesn’t
call. Sometimes it’s set off by minor
earthquakes. Is there a burglar?
• What are the variables?
–
–
–
–
–
Burglar
Earthquake
Alarm
JohnCalls
MaryCalls
9
Another Example (continued)
• Network Topology reflects causal knowledge:
–
–
–
–
A burglar can set the alarm off
An earthquake can set the alarm off
The alarm can cause Mary to call
The alarm can cause John to call
• Assumption
– they do not perceive any burglaries directly,
– they do not notice the minor earthquakes, and
– they do not confer before calling.
10
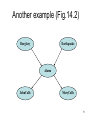
Another example (Fig.14.2)
Burglary
Earthquake
Alarm
JohnCalls
MaryCalls
11
Conditional Probability table (CPT)
• Each distribution is shown as a conditional probability table, or
CPT.
• CPT can be used for discrete variables; other representations,
including those suitable for continuous variables
• Each row in a CPT contains the conditional
probability of each node value for a conditioning case.
• A conditioning case is just a possible combination of values for
the parent nodes—a miniature atomic event, if you like.
• Each row must sum to 1, because the entries represent an
exhaustive set of cases for the variable.
• For Boolean variables, once you know that the probability of a
true value is p, the probability of false must be 1 – p, so we
often omit the second number, as in Figure 14.2.
• In general, a table for a Boolean variable with k Boolean
parents contains 2k independently specifiable probabilities.
• A node with no parents has only one row, representing the
prior probabilities of each possible value of the variable.
12
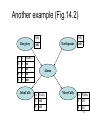
Another example (Fig.14.2)
P(B)
Burglary
B
E
P(A|B,E)
T
T
.95
T
F
.94
F
T
.29
F
F
.001
JohnCalls
P(E)
Earthquake
.001
.001
Alarm
A
P(J|A)
T
F
MaryCalls
A
P(M|A)
.90
T
.70
.05
F
.01
13
Compactness
B
E
P(A|B,E)
T
T
T
F
.95
.94
F
F
T
F
.29
.001
B
E
A
J
M
• Conditional Probability Table (CPT): distribution
over Xi for each combination of parent values
• Each row requires one number p for for Xi=true
(since the false case is just 1-p)
• A CPT for Boolean Xi with k Boolean parents has
2k rows for the combinations of parent values
• Full network requires O(n = 2k) numbers (instead
of 2n)
14
14.2 Semantics of Bayesian
Networks
• Global: Representing the full joint
distribution
– be helpful in understanding how to
construct networks,
• Local: Representing conditional
independence
– be helpful in designing inference
procedures
15
Global Semantics
• Global semantics defines the full joint distribution as
the product of the local conditional distributions
• P(X1=x1, X2=x2, X3=x3, …,Xn=xn)
• = P(X1,…,Xn)=ni=1 P(Xi|Parents(Xi))
– where parents (Xi) denotes the specific values of the variables
in Parents(Xi).
– Thus, each entry in the joint distribution is represented by the
product of the appropriate elements of the conditional
probability tables (CPTs) in the Bayesian network.
– The CPTs therefore provide a decomposed representation of
the joint distribution.
• Example:
What is P(j m a b e)?
= P(j|a)P(m|a)P(a| b, e)P( b)P( e)
0.90*0.70*0.001*0.999*0.998=0.00062
16
But does a BN represent a
belief state?
In other words, can we compute
the full joint distribution of the
propositions from it?
17
Calculation of Joint Probability
Burglary
P(B)
Earthquake
0.00
1
P(JMABE) = ??
Alarm
JohnCalls
A
P(J|…)
T
F
0.90
0.05
P(E)
0.00
2
B E P(A|…)
T
T
F
F
T
F
T
F
0.95
0.94
0.29
0.001
MaryCalls
A P(M|…)
T 0.70
F 0.01
18
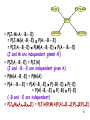
Burglary
Earthquake
Alarm
JohnCalls
MaryCalls
P(JMABE)
= P(JM|A,B,E) P(ABE)
= P(J|A,B,E) P(M|A,B,E) P(ABE)
(J and M are independent given A)
P(J|A,B,E) = P(J|A)
(J and BE are independent given A)
P(M|A,B,E) = P(M|A)
P(ABE) = P(A|B,E) P(B|E) P(E)
= P(A|B,E) P(B) P(E)
(B and E are independent)
P(JMABE) = P(J|A)P(M|A)P(A|B,E)P(B)P(E)
19
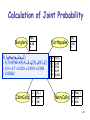
Calculation of Joint Probability
Burglary
P(B)
Earthquake
0.00
1
P(JMABE)
= P(J|A)P(M|A)P(A|B,E)P(B)P(E)
= 0.9 x 0.7 x 0.001 x 0.999 Alarm
x 0.998
= 0.00062
JohnCalls
A
P(J|…)
T
F
0.90
0.05
P(E)
0.00
2
B E P(A|…)
T
T
F
F
T
F
T
F
0.95
0.94
0.29
0.001
MaryCalls
A P(M|…)
T 0.70
F 0.01
20
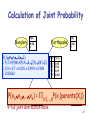
Calculation of Joint Probability
Burglary
P(B)
Earthquake
0.00
1
P(JMABE)
= P(J|A)P(M|A)P(A|B,E)P(B)P(E)
= 0.9 x 0.7 x 0.001 x 0.999 Alarm
x 0.998
= 0.00062
P(E)
0.00
2
B E P(A|…)
T
T
F
F
T
F
T
F
0.95
0.94
0.29
0.001
P(x1x
= Pi=1,…,nP(x
JohnCalls
MaryCalls
T 0.70 i))
2…xnT) 0.90
i|parents(X
A
P(J|…)
A P(M|…)
F
0.05
F 0.01
full joint distribution table
21
Calculation of Joint Probability
Since a BN definesP(E)the
Burglary 0.00 full jointEarthquake
0.00 of a
distribution
1
2
set of propositions, it
P(JMABE)
B E P(A| )
represents
a belief state
= P(J|A)P(M|A)P(A|B,E)P(B)P(E) T T 0.95
P(B)
…
= 0.9 x 0.7 x 0.001 x 0.999 Alarm
x 0.998
= 0.00062
T F 0.94
F T 0.29
F F 0.001
P(x1x
= Pi=1,…,nP(x
JohnCalls
MaryCalls
T 0.70 i))
2…xnT) 0.90
i|parents(X
A
P(J|…)
A P(M|…)
F
0.05
F 0.01
full joint distribution table
22
23
Chain Rule
24
• We need to choose parents for each node such that
this property holds. Intuitively, the parents of node Xi
should contain all those nodes in X1, ... , Xi_1 that
directly influence Xi.
• For example, suppose we have completed the
network in Figure 14.2 except for the choice of
parents for MaryCalls. MaryCalls is certainly
influenced by whether there is a Burglary or an
Earthquake, but not directly influenced. Intuitively,
our knowledge of the domain tells us that these
events influence Mary's calling behavior only
through their effect on the alarm.
• Also, given the state of the alarm, whether John calls
has no influence on Mary's calling. Formally
speaking, we believe that the following conditional
independence statement holds:
25
• P(MaryCalls John Calls , Alarm, Earthquake,
Constructing Bayesian
Networks (cont.)
• Direct influencers should be added to the
network first
• The correct order in which to add nodes is to
add “root causes” first, then the variables
they influence, and so on.
• We need to choose parents for each node
such that this property holds. Intuitively, the
parents of node Xi should contain all those
nodes in X1, X2, ... , Xi-1 that directly influence
Xi.
• If we don’t follow these rules, we can end up
with a very complicated network.
26
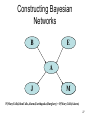
Constructing Bayesian
Networks
B
E
A
J
M
P(MaryCalls|JohnCalls,Alarm,Earthquake,Burglary) = P(MaryCalls|Alarm)
27
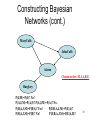
Constructing Bayesian
Networks (cont.)
MaryCalls
Chosen order: M,J,A,B,E
P(J|M)=P(J)?
28
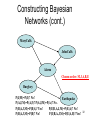
Constructing Bayesian
Networks (cont.)
MaryCalls
JohnCalls
Chosen order: M,J,A,B,E
P(J|M)=P(J)? No!
P(A|J,M)=P(A|J)? P(A|J,M)=P(A)?
29
Constructing Bayesian
Networks (cont.)
MaryCalls
JohnCalls
Alarm
Chosen order: M,J,A,B,E
P(J|M)=P(J)? No!
P(A|J,M)=P(A|J)? P(A|J,M)=P(A)? No.
P(B|A,J,M)=P(B|A)?
P(B|A,J,M)=P(B)?
30
Constructing Bayesian
Networks (cont.)
MaryCalls
JohnCalls
Alarm
Chosen order: M,J,A,B,E
Burglary
P(J|M)=P(J)? No!
P(A|J,M)=P(A|J)? P(A|J,M)=P(A)? No.
P(B|A,J,M)=P(B|A)? Yes!
P(E|B,A,J,M)=P(E|A)?
P(B|A,J,M)=P(B)? No!
P(E|B,A,J,M)=P(E|A,B)?
31
Constructing Bayesian
Networks (cont.)
MaryCalls
JohnCalls
Alarm
Chosen order: M,J,A,B,E
Burglary
P(J|M)=P(J)? No!
Earthquake
P(A|J,M)=P(A|J)? P(A|J,M)=P(A)? No.
P(B|A,J,M)=P(B|A)? Yes!
P(E|B,A,J,M)=P(E|A)? No!
P(B|A,J,M)=P(B)? No!
P(E|B,A,J,M)=P(E|A,B)? Yes!
32
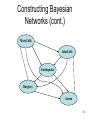
Bad example
33
Constructing Bayesian
Networks (cont.)
MaryCalls
JohnCalls
Earthquake
Burglary
Alarm
34
Local Semantics
• Local Semantics: Each node is
conditionally independent of its
nondescendants given its parents
35
Markov Blanket
• A node is conditionally independent of all other nodes in the
network, given its parents, children, and children's parents—
that is, given its Markov blanket.
36
14-3 Efficient Representation of
Conditional Distributions
• Even if the maximum number of parents k is smallish,
filling in the CPT for a node requires up to O(2k)
numbers and perhaps a great deal of experience with all
the possible conditioning cases.
• In fact, this is a worst-case scenario in which the
relationship between the parents and the child is
completely arbitrary.
• Usually, such relationships are describable by a
canonical distribution that fits some standard pattern.
• In such cases, the complete table can be specified by
naming the pattern and perhaps supplying a few
parameters—much easier than supplying an
exponential number of parameters.
37
Deterministic nodes
• A deterministic node has its value specified
exactly by the values of its parents, with no
uncertainty.
– The relationship can be a logical one:
• for example, the relationship between the parent nodes
Canadian, US, Mexican and the child node NorthAmerican is
simply that the child is the disjunction of the parents.
– The relationship can also be numerical:
• for example, if the parent nodes are the prices of a particular
model of car at several dealers, and the child node is the
price that a bargain hunter ends up paying, then the child
node is the minimum of the parent values; or
• if the parent nodes are the inflows (rivers, runoff, precipitation)
into a lake and the outflows (rivers, evaporation, seepage)
from the lake and the child is the change in the water level of
the lake, then the value of the child is the difference between
the inflow parents and the outflow parents.
38
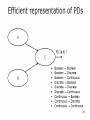
Efficient representation of PDs
39
Efficient representation of PDs
40
Noisy-OR relation
• The standard example is the noisy-OR
relation, which is a generalization of the
logical OR.
• In propositional logic, we might say that
Fever is true if and only if Cold, Flu(流行性感
冒), or Malaria(瘧疾) is true.
• The noisy-OR model allows for uncertainty
about the ability of each parent to cause the
child to be true—the causal relationship
between parent and child may be inhibited,
and so a patient could have a cold, but not
exhibit a fever.
41
Noisy-OR relation
• The model makes two assumptions.
– First, it assumes that all the possible causes are
listed. (This is not as strict as it seems, because
we can always add a so-called leak node that
covers "miscellaneous causes.")
– Second, it assumes that inhibition of each parent
is independent of inhibition of any other parents:
• for example, whatever inhibits Malaria from causing a fever is
independent of whatever inhibits Flu from causing a fever.
• Fever is false if and only if all its true parents are inhibited,
and the probability of this is the product of the inhibition
probabilities for each parent.
42
Example
• Let us suppose these individual inhibition probabilities
(or noisy paramaters) are as follows:
– P(fever |cold, flu , malaria) = 0.6 , [P(fever |cold) = 0.4 ],
– P( fever | cold , flu, malaria) = 0.2 , [P(fever|flu) = 0.8 ],
– P( fever | cold , flu, malaria) = 0.1 . [P(fever|malaria) = 0.9 ],
• Then, from this information and the noisy-OR
assumptions, the entire CPT can be built.
O(k)
43
44
45
•
Bayesian nets with cont.
Many real-worldvariables
problems involve
continuous quantities.
• Much of statistics deals with random
variables whose domains are continuous. By
definition, continuous variables have an
infinite number of possible values, so it is
impossible to specify conditional
probabilities explicitly for each value.
• Handle continuous variables is to avoid them
by using discretizations, dividing up the
possible values into a fixed set of intervals.
• Discretization is sometimes an adequate
solution, but often results in a considerable 46
loss of accuracy and very large CPTs.
cont. variables
• The other solution is to define standard
families of probability density functions (see
Appendix A) that are specified by a finite
number of parameters.
– For example, a Gaussian (or normal) distribution
N(µ, σ2) (x) has the mean µ and the variance σ2 as
parameters.
• A network with both discrete and continuous
variables is called a hybrid Bayesian network.
– the conditional distribution for a continuous
variable given discrete or continuous parents;
P(C|C) or P(C|D)
– the conditional distribution for a discrete variable
given continuous parents. P(D|C)
47
48
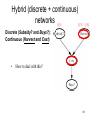
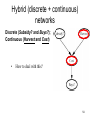
Hybrid (discrete + continuous)
networks 補助
產季、收穫
Discrete (Subsidy? and Buys?);
Continuous (Harvest and Cost)
•
How to deal with this?
49
Probability density functions
• Instead of probability distributions
• For continuous variables
• Ex.: let X denote tomorrow’s maximum
temperature in the summer in
Eindhoven
Belief that X is distributed uniformly
between 18 and 26 degree Celsius:
P(X=x) = U[18,26](x)
P(X=20,5) = U[18,26](20,5)=0,125/C
50
PDF
51
CDF
52
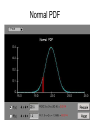
Normal PDF
53
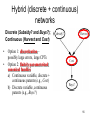
Hybrid (discrete + continuous)
networks
Discrete (Subsidy? and Buys?);
Continuous (Harvest and Cost)
•
How to deal with this?
54
Hybrid (discrete + continuous)
networks
Discrete (Subsidy? and Buys?);
Continuous (Harvest and Cost)
•
•
Option 1: discretization –
possibly large errors, large CPTs
Option 2: finitely parameterized
canonical families
a) Continuous variable, discrete +
continuous parents (e.g., Cost)
b) Discrete variable, continuous
parents (e.g., Buys?)
55
a) Continuous child variables
• Need one conditional density function for child
variable given continuous parents, for each possible
assignment to discrete parents
• Most common is the linear Gaussian model, e.g.:
• Mean Cost varies linearly w. Harvest, variance is
fixed
• Linear variation is unreasonable over the full range,
but works OK if the likely range of Harvest is narrow56
Continuous child variables – ex.
• All-continuous network w. LG distribution
full joint is a multivariate Gaussian
• Discrete + continuous LG network is a conditional
Gaussian network, i.e., a multivariate Gaussian
over all continuous variables for each
combination of discrete variable values
57
b) Discrete child, continuous parent
• P(buys|Cost=c) = ((-c + ) / )
• with - threshold for buying
• Probit distribution:
– - the integral on the standard normal
x
distribution
( x)
N (0,1)( x)dx
• Logit distribution:
– Uses the sigmoid function
1
( x)
1 e
2 x
58
Probit distribution
59
14-4 Exact inference in Bayesian
Networks
• Let us use the following notations:
– X denotes the query variable
– e denotes the set of evidence variables E1, … , En
– y denotes the set of nonevidence (hidden) variables
Y1, … , Yn
– Complete set of variable X={X}E Y.
• A typical query asks for the posterior probability
distribution P(Xle).
• P(Burglary|JohnCalls = true, MaryCalls = true)
= <0.284, 0.716>
60
Inference by enumeration
• any conditional probability can be computed by
summing terms from the full joint distribution.
• query P(X le) can be answered using Equation (13.6),
• Bayesian network gives a complete representation
of the full joint distribution.
• The terms P(x, e, y) in the joint distribution can be
written as products of conditional probabilities from
the network.
• Therefore, a query can be answered using a
Bayesian network by computing sums of products of
conditional probabilities from the network.
61
62
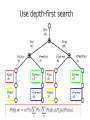
13-4 Enumerate-Joint-Ask
63
64
Computation
Hidden variables
65
Improvement
66
67
68
69
70
71
72
73
Variable elimination algorithm
The enumeration algorithm can be improved
substantially by eliminating repeated calculations of
the kind illustrated in Figure 14.8.
The idea is simple: do the calculation once and
save the results for later use. This is a form of
dynamic programming. There are several versions of
this approach; we present the variable elimination
algorithm, which is the simplest.
Variable elimination works by evaluating
expressions such as Equation (14.3) in right-to-left
order (that is, bottom-up in Figure 14.8). Intermediate
results are stored, and summations over each
variable are done only for those portions of the
expression that depend on the variable.
74
75
Pointwise product
76
77
78
Elimination-ASK
79
Querying the BN
New evidence E indicates that JohnCalls with
some probability p
We would like to know the posterior
probability of the other beliefs, e.g.
P(Burglary|E)
P(B|E)
= P(BJ|E) + P(B J|E)
= P(B|J,E) P(J|E) + P(B |J,E) P(J|E)
= P(B|J) P(J|E) + P(B|J) P(J|E)
= p P(B|J) + (1-p) P(B|J)
We need to compute P(B|J) and P(B|J)
80
Querying the BN
Cavity
P(C)
0.1
C P(T|c)
Toothache
T 0.4
F 0.0111
1
The BN gives P(t|c)
What about P(c|t)?
P(Cavity|t)
= P(Cavity t)/P(t)
= P(t|Cavity) P(Cavity) /
P(t)
[Bayes’ rule]
P(c|t) = a P(t|c) P(c)
Querying a BN is just
applying the trivial Bayes’
rule on a larger scale
81
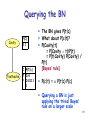
Querying the BN
P(b|J) = a P(bJ)
= a
= a
SmSaSeP(bJmae) [marginalization]
SmSaSeP(b)P(e)P(a|b,e)P(J|a)P(m|a)
P(b)SeP(e)SaP(a|b,e)P(J|a)SmP(m|a)
[BN]
= a
[re-ordering]
Depth-first evaluation of P(b|J) leads to computing
each of the 4 following products twice:
P(J|A) P(M|A), P(J|A) P(M|A), P(J|A) P(M|A), P(J|A) P(M|A)
Bottom-up (right-to-left) computation + caching –
e.g., variable elimination algorithm (see R&N) –
avoids such repetition
For singly connected BN, the computation takes time
linear in the total number of CPT entries ( time
linear in the # propositions if CPT’s size is bounded)
82
Singly Connected BN
A BN is singly connected (or polytree) if there
is at most one undirected path between any
two nodes
Burglary
Earthquake
is singly connected
Alarm
JohnCalls
MaryCalls
The time and space complexity of exact inference in polytrees
is linear in the size of the network (the number of CPT entries).
83
Multiply Connected BN
A BN is multiply connected if there is more
than one undirected path between a pair of
nodes
Burglary
Earthquake
Alarm
JohnCalls
is multiply connected
MaryCalls
variable elimination can have exponential time and space complexity in the
worst case, even when the number of parents per node is bounded.
it includes inference in propositional logic as a special case, inference in
84
Bayesian networks is NP-hard.
Multiply Connected BN
A BN is multiply connected if there is more
than one undirected path between a pair of
nodes
Burglary
Earthquake
Querying a multiply-connected BN takes
time exponential in the total
number
of
is
multiply
connected
Alarm
CPT entries in the worst case
JohnCalls
MaryCalls
85
Clustering algorithm
• Join tree algorithm O(n)
• Widely used in commercial networks tools.
• join individual nodes of the network to form
cluster nodes in such a way that the
resulting network is a polytree.
• Once the network is in polytree form, a
special-purpose inference algorithm is
applied. Essentially, the algorithm is a form
of constraint propagation (see Chapter 5)
where the constraints ensure that
neighboring clusters agree on the posterior
probability of any variables that they have in
common.
86
Clustering algorithm
87
14-5 Approximate inference in
Bayesian Networks
• Given the intractability of exact inference in large,
multiply connected networks, it is essential to
consider approximate inference methods.
• This section describes randomized sampling
algorithms, also called Monte Carlo algorithms, that
provide approximate answers whose accuracy
depends on the number of samples generated.
• In recent years, Monte Carlo algrithms have become
widely used in computer science to estimate
quantities that are difficult to calculate exactly. For
example, the simulated annealing algorithm.
• We describe two families of algorithms:
– direct sampling and
– Markov chain sampling.
– variational methods and (skip)
88
– loopy propagation (skip).
Methods
i. Sampling from an empty network
ii.Rejection sampling: reject samples
disagreeing w. evidence
iii.Likelihood weighting: use evidence to
weight samples
iv.MCMC: sample from a stochastic
process whose stationary distribution
is the true posterior
89
Introduction
•
•
•
•
The primitive element in any sampling algorithm is
the generation of samples from a known
probability distribution.
For example, an unbiased coin can be thought of
as a random variable Coin with values (heads, tails)
and a prior distribution P(Coin) = (0.5, 0.5).
Sampling from this distribution is exactly like
flipping the coin: with probability 0.5 it will return
heads, and with probability 0.5 it will return tails.
Given a source of random numbers in the range [0,
1], it is a simple matter to sample any distribution
on a single variable.
90
Sampling on Bayesian Network
• The simplest kind of random sampling process for
Bayesiah networks generates events from a network
that has no evidence associated with it.
• The idea is to sample each variable in turn, in
topological order.
• The probability distribution from which the value is
sampled is conditioned on the values already
assigned to the variable's parents.
91
92
Prior-sample
• This algorithm is shown in Figure 14.12. We can
illustrate its operation on the network in Figure
14.11(a), assuming an ordering [Cloudy, Sprinkler,
Rain, WetGrass] :
• Sample from P(Cloudy) _ <0.5, 0.5>; suppose this
returns true.
• Sample from P(Sprinkler |Cloudy = true) = <0.1, 0.9>;
suppose this returns false.
• Sample from P(Rain | Cloudy = true) = <0.8, 0.2>;
suppose this returns true.
• Sample from P( WetGrass| Sprinkler = false, Rain =
true) = <0.9, 0.1>; suppose this returns true.
• PRIOR-SAMPLE returns the event [true, false, true,
93
true].
i. Sampling from an empty
network – cont.
•
•
•
•
•
Probability that PRIOR-SAMPLE generates a particular
event:
SPS(x1, … ,xn) = P n i=1P(Xi|Parents(Xi))=P(x1,…, xn)
NPS (Y=y) no. of samples generated for which Y=y for
any set of variables Y.
Then, P’(Y=y) = NPS(Y=y)/N and
lim N P’(Y=y) = Sh SPS(Y=y,H=h) =
= Sh P(Y=y,H=h) =
= P(Y=y)
estimates derived from PRIOR-SAMPLE are consistent
94
II Rejection sampling
• Rejection sampling is a general method for
producing samples from a hard-to-sample
distribution given an easy-to-sample distribution.
• In its simplest form, it can be used to compute
conditional probabilities—that is, to determine
P(X le).
• REJECTION-SAMPLING algorithm
– First, generates samples from the prior distribution
specified by the network.
– Then, it rejects all those that do not match the
evidence.
– Finally, the estimate P(X = x| e) is obtained by
counting how often X = x occurs in the remaining
samples
95
Rejection-sampling algorithm
96
Example
• Assume that we wish to estimate P(Rainl Sprinkler = true),
using 100 samples.
• Of the 100 that we generate, suppose that 73 have Sprinkler =
false and are rejected, while 27 have Sprinkler = true; of the 27,
8 have Rain = true and 19 have Rain = false.
• P( Rain1 |Sprinkler = true) ≈ NORMALIZE(<8,19>) = <0.296,
0.704> .
• The true answer is <0.3, 0.7>.
• As more samples are collected, the estimate will converge to
the true answer. The standard deviation of the error in each
probability will be proportional to 1/sqrt(n), where n is the
number of samples used in the estimate.
• The biggest problem with rejection sampling is that it rejects so
many samples! The fraction of samples consistent with the
evidence e drops exponentially as the number of evidence
variables grows, so the procedure is simply unusable for
complex problems.
97
iii. Likelihood weighting analysis
• avoids the inefficiency of rejection sampling by
generating only events that are consistent with the
evidence e.
• generates consistent probability estimates.
• fixes the values for the evidence variables E and
samples only the remaining variables X and Y. This
guarantees that each event generated is consistent
with the evidence.
• Before tallying the counts in the distribution for the
query variable, each event is weighted by the
likelihood that the event accords to the evidence, as
measured by the product of the conditional
probabilities for each evidence variable, given its
parents.
98
• Intuitively, events in which the actual evidence
appears unlikely should be given less weight.
Example
• query P(Rain lSprinkler = true, WetGrass = true).
•
•
•
•
•
•
•
First, the weight w is set to 1.0.
Then an event is generated:
Sample from P( Cloudy) _=(0.5, 0.5); suppose this returns true.
Sprinkler is an evidence variable with value true.
Therefore, we set
w <-_ w x P(Sprinkler = true| Cloudy = true) = 0.1 .
Sample from P(Rain| Cloudy = true) = (0.8, 0.2); suppose this
returns true.
• WetGrass is an evidence variable with value true.
• Therefore, we set
• w <- w x P(WetGrass = true Sprinkler = true, Rain = true) =
0.099 .
99
100
iii. Likelihood weighting analysis
• Sampling probability for WEIGHTED-SAMPLE is
SWS(y,e) = P l i=1P(yi|Parents(Yi))
• Note: pays attention to evidence in ancestors only
somewhere “in between” prior and posterior distribution
• Weight for a given sample y,e, is
w(y,e) = P n i=1P(ei|Parents(Ei))
• Weighted sampling probability is
SWS(y,e) w(y,e) = P l i=1P(yi|Parents(Yi)) P m i=1P(ei|Parents(Ei))
= P(y,e)
# by standard global semantics of network
• Hence, likelihood weighting is consistent
• But performance still degrades w. many evidence
variables
101
iv. MCMC Example
• Estimate
P(Rain|Sprinkler=tr
ue, WetGrass=true)
• Sample Cloudy then
Rain, repeat.
– Markov blanket of
Cloudy is Sprinkler
and Rain.
– Markov blanket of
Rain is Cloudy,
Sprinkler and
WetGrass.
102
iv. MCMC Example – cont.
0.
Random initial state:
Cloudy=true and Rain=false
1.
P(Cloudy|MB(Cloudy)) = P(Cloudy|Sprinkler, Rain)
sample false
2.
P(Rain|MB(Rain)) = P(Rain|Cloudy,
Sprinkler,WetGrass)
sample true
Visit 100 states
31 have Rain=true, 69 have Rain=false
P’(Rain|Sprinkler=true,WetGrass=true) =
NORMALIZE(<31,69>) = <0.31,0.69>
103
Probability of x, given MB(x)
P( x | mb( X )) aP( x | parents( X ))
P( y
j
| parents(Y j ))
Y j Children( X )
104
MCMC algorithm
105
Performance of statistical
algorithms
• Polytime approximation
• Stochastic approximation techniques
such as likelihood weighting and
MCMC
– can give reasonable estimates of true
posterior probabilities in a network, and
– can cope with much larger networks
106
14-6 Skip
107
14-7 Other approaches to
uncertain reasoning
• Different generations of expert systems
– Strict logic reasoning (ignore uncertainty)
– Probabilistic techniques using the full Joint
– Default reasoning - believed until a better reason
is found to believe something else
– Rules with certainty factors
– Handling ignorance - Dempster-Shafer theory
– Vagueness(含糊) - something is sort of true (fuzzy
logic)
• Probability makes the same ontological
commitment as logic: the event is true or
false
108
Default reasoning
• The four-wheel car conclusion is reached by
default.
• New evidence can cause the conclusion
retracted, while FOL is strictly monotonic.
• Representatives are default logic,
nonmonotonic logic, circumscription
• There are problematic issues
109
Rule-based methods
• Logical reasoning systems have
properties like:
– Monotonicity
– Locality
• In logical systems, whenever we have a rule of the form AB,
we can conclude B, given evidence A, without worrying about
any other rules.
– Detachment
• Once a logical proof is found for a proposition B, the proposition can be
used regardless of how it was derived. That is, it can be detached from
its justification.
– Truth-functionality
• In logic, the truth of complex sentences can be computed from
the truth of the components.
110
Rule-based method
• These properties are good for obvious
computational advantages;
• bad as they’re inappropriate for
uncertain reasoning.
111
Representing ignorance:
• Dempster—Shafer theory
• The Dempster—Shafer theory is
designed to deal with the distinction
between uncertainty and ignorance(無
知).
• Rather than computing the probability
of a proposition, it computes the
probability that the evidence supports
the proposition.
• This measure of belief is called a belief
112
function, written Bel (X)
Example
• coin flipping for an example of belief functions.
• Suppose a shady character comes up to you and offers to bet
you $10 that his coin will come up heads on the next flip.
• Given that the coin might or might not be fair, what belief
should you ascribe to the event that it comes up heads?
• Dempster—Shafer theory says that because you have no
evidence either way, you have to say that the belief Bel(Heads)
= 0 and also that Bel(Heads) = 0.
• Now suppose you have an expert at your disposal who testifies
with 90% certainty that the coin is fair (i.e., he is 90% sure that
P(Heads) = 0.5).
• Then Dempster—Shafer theory gives Bel(Heads) = 0.9 x 0.5 =
0.45 and likewise Bel( Heads) = 0.45.
• There is still a 10 percentage point "gap" that is not accounted
for by the evidence.
• "Dempster's rule" (Dempster, 1968) shows how to combine
evidence to give new values for Bel, and Shafer's work extends
this into a complete computational model.
113
Fuzzy set & fuzzy logic
• Fuzzy set theory is a means of specifying how well an object
satisfies a vague description(模糊的描述).
• For example, consider the proposition "Nate is tall." Is this true,
if Nate is 5' 10"? Most people would hesitate to answer "true"
or "false," preferring to say, "sort of."
• Note that this is not a question of uncertainty about the
external world—we are sure of Nate's height. The issue is that
the linguistic term "tall" does not refer to a sharp demarcation
of objects into two classes—there are degrees of tallness.
• For this reason, fuzzy set theory is not a method for uncertain
reasoning at all.
• Rather, fuzzy set theory treats Tall as a fuzzy predicate and
says that the truth value of Tall(Nate) is a number between 0
and 1, rather than being just true or false. The name "fuzzy set"
derives from the interpretation of the predicate as implicitly
defining a set of its members—a set that does not have sharp
boundaries.
114
Fuzzy logic
• Fuzzy logic is a method for reasoning with
logical expressions describing membership
in fuzzy sets.
• For example, the complex sentence Tall(Nate)
Heavy(Nate) has a fuzzy truth value that is
a function of the truth values of its
components.
• The standard rules for evaluating the fuzzy
truth, T, of a complex sentence are
– T(A B) = min(T(A), T(B))
– T(A B) = max(T(A),T(B))
– T(A)=1-T(A).
115
Summary
• Reasoning properly
– In FOL, it means conclusions follow from
premises
– In probability, it means having beliefs that allow
an agent to act rationally
• Conditional independence info is vital
• A Bayesian network is a complete
representation for the JPD, but exponentially
smaller in size
• Bayesian networks can reason causally,
diagnostically, intercausally, or combining
two or more of the three.
• For polytrees, the computational time is 116
linear in network size.