Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
DSP Lecture 02
Chapter 2
TMS320C6000 Architectural Overview
Learning Objectives
•
•
•
•
•
•
2
Describe C6000 CPU architecture.
Introduce some basic instructions.
Describe the C6000 memory map.
Provide an overview of the peripherals.
Performance
Software Development
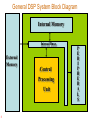
General DSP System Block Diagram
Internal Memory
Internal Buses
External
Memory
Central
Processing
Unit
3
P
E
R
I
P
H
E
R
A
L
S
Implementation of Sum of Products (SOP)
It has been shown in
Chapter 1 that SOP is the
key element for most DSP
algorithms.
So let’s write the code for
this algorithm and at the
same time discover the
C6000 architecture.
N
Y =
an * xn
n = 1
= a1 * x1 + a2 * x2 +... + aN * xN
Two basic
operations are required
for this algorithm.
(1) Multiplication
(2) Addition
Therefore two basic
instructions are required
4
Implementation of Sum of Products (SOP)
So let’s implement the SOP
algorithm!
N
Y =
an * xn
n = 1
= a1 * x1 + a2 * x2 +... + aN * xN
The implementation in this
module will be done in
assembly.
Two basic
operations are required
for this algorithm.
(1) Multiplication
(2) Addition
Therefore two basic
instructions are required
5
Multiply (MPY)
N
Y =
an * xn
n = 1
= a1 * x1 + a2 * x2 +... + aN * xN
The multiplication of a1 by x1 is done in
assembly by the following instruction:
MPY
a1, x1, Y
This instruction is performed by a
multiplier unit that is called “.M”
6
Multiply (.M unit)
40
Y =
an * xn
n = 1
.M
The . M unit performs multiplications in
hardware
MPY
.M
a1, x1, Y
Note: 16-bit by 16-bit multiplier provides a 32-bit result.
32-bit by 32-bit multiplier provides a 64-bit result.
7
Addition (.?)
40
Y =
an * xn
n = 1
.M
.?
8
MPY
.M
a1, x1, prod
ADD
.?
Y, prod, Y
Add (.L unit)
40
Y =
an * xn
n = 1
.M
.L
MPY
.M
a1, x1, prod
ADD
.L
Y, prod, Y
RISC processors such as the C6000 use registers to
hold the operands, so lets change this code.
9
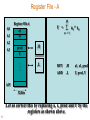
Register File - A
40
Register File A
A0
A1
a1
x1
A2
A3
Y =
an * xn
n = 1
prod
Y
.M
.
.
.
.L
MPY
.M
a1, x1, prod
ADD
.L
Y, prod, Y
A15
32-bits
Let us correct this by replacing a, x, prod and Y by the
registers as shown above.
10
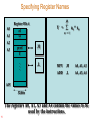
Specifying Register Names
40
Register File A
A0
A1
a1
x1
A2
A3
Y =
an * xn
n = 1
prod
Y
.M
.
.
.
.L
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
A15
32-bits
The registers A0, A1, A3 and A4 contain the values to be
used by the instructions.
11
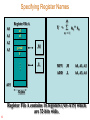
Specifying Register Names
40
Register File A
A0
A1
a1
x1
A2
A3
Y =
an * xn
n = 1
prod
Y
.M
.
.
.
.L
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
A15
32-bits
Register File A contains 16 registers (A0 -A15) which
are 32-bits wide.
12
Data loading
Register File A
A0
A1
a1
x1
A2
A3
prod
Y
.M
.
.
.
.L
A15
32-bits
13
Q: How do we load the
operands into the registers?
Load Unit “.D”
Register File A
A0
A1
Q: How do we load the
operands into the registers?
a1
x1
A2
A3
prod
Y
.M
.
.
.
.L
.D
A15
32-bits
Data Memory
14
A: The operands are loaded
into the registers by loading
them from the memory
using the .D unit.
Load Unit “.D”
Register File A
A0
A1
a1
x1
A2
A3
prod
Y
.M
.
.
.
.L
.D
A15
32-bits
Data Memory
15
It is worth noting at this
stage that the only way to
access memory is through the
.D unit.
Load Instruction
Register File A
A0
A1
a1
x1
A2
A3
prod
Y
.M
.
.
.
.L
.D
A15
32-bits
Data Memory
16
Q: Which instruction(s) can be
used for loading operands
from the memory to the
registers?
Load Instructions (LDB, LDH,LDW,LDDW)
Register File A
A0
A1
a1
x1
A2
A3
prod
Y
.M
.
.
.
.L
A: The load instructions.
.D
A15
32-bits
Data Memory
17
Q: Which instruction(s) can be
used for loading operands
from the memory to the
registers?
Using the Load Instructions
Before using the load unit you
have to be aware that this
processor is byte addressable,
which means that each byte is
represented by a unique
address.
Data
address
00000000
00000002
00000004
00000006
00000008
Also the addresses are 32-bit
wide.
FFFFFFFF
16-bits
18
Using the Load Instructions
The syntax for the load
instruction is:
LD *Rn,Rm
Where:
Rn is a register that contains
the address of the operand to
be loaded
Data
address
a1
x1
00000000
00000002
00000004
00000006
00000008
prod
Y
and
Rm is the destination register.
FFFFFFFF
16-bits
19
Using the Load Instructions
The syntax for the load
instruction is:
LD *Rn,Rm
The question now is how many
bytes are going to be loaded
into the destination register?
Data
address
a1
x1
00000000
00000002
00000004
00000006
00000008
prod
Y
FFFFFFFF
16-bits
20
Using the Load Instructions
The syntax for the load
instruction is:
LD *Rn,Rm
The answer, is that it depends on
the instruction you choose:
Data
address
a1
x1
00000000
00000002
00000004
00000006
00000008
prod
Y
• LDB: loads one byte (8-bit)
• LDH: loads half word (16-bit)
• LDW: loads a word (32-bit)
• LDDW: loads a double word (64-bit)
Note: LD on its own does not
exist.
21
FFFFFFFF
16-bits
Using the Load Instructions
The syntax for the load
instruction is:
Data
1
0
0xA
0xB
0xC
0xD
0x2
0x1
Example:
0x4
0x3
If we assume that A5 = 0x4 then:
0x6
0x5
(1) LDB *A5, A7 ; gives A7 = 0x00000001
0x8
0x7
LD *Rn,Rm
address
00000000
00000002
00000004
00000006
00000008
(2) LDH *A5,A7; gives A7 = 0x00000201
(3) LDW *A5,A7; gives A7 = 0x04030201
(4) LDDW *A5,A7:A6; gives A7:A6 =
0x0807060504030201
FFFFFFFF
16-bits
22
Using the Load Instructions
The syntax for the load
instruction is:
Data
1
0
0xA
0xB
0xC
0xD
0x2
0x1
Example:
0x4
0x3
If we assume that A5 = 0x4 then:
0x6
0x5
(1) LDB *A5, A7 ; gives A7 = 0x00000001
0x8
0x7
LD *Rn,Rm
address
00000000
00000002
00000004
00000006
00000008
(2) LDH *A5,A7; gives A7 = 0x00000201
(3) LDW *A5,A7; gives A7 = 0x04030201
(4) LDDW *A5,A7:A6; gives A7:A6 =
0x0807060504030201
FFFFFFFF
16-bits
23
Using the Load Instructions
The syntax for the load
instruction is:
Data
1
0
0xA
0xB
0xC
0xD
0x2
0x1
Example:
0x4
0x3
If we assume that A5 = 0x4 then:
0x6
0x5
(1) LDB *A5, A7 ; gives A7 = 0x00000001
0x8
0x7
LD *Rn,Rm
address
00000000
00000002
00000004
00000006
00000008
(2) LDH *A5,A7; gives A7 = 0x00000201
(3) LDW *A5,A7; gives A7 = 0x04030201
(4) LDDW *A5,A7:A6; gives A7:A6 =
0x0807060504030201
FFFFFFFF
16-bits
24
Using the Load Instructions
The syntax for the load
instruction is:
Data
1
0
0xA
0xB
0xC
0xD
0x2
0x1
Example:
0x4
0x3
If we assume that A5 = 0x4 then:
0x6
0x5
(1) LDB *A5, A7 ; gives A7 = 0x00000001
0x8
0x7
LD *Rn,Rm
address
00000000
00000002
00000004
00000006
00000008
(2) LDH *A5,A7; gives A7 = 0x00000201
(3) LDW *A5,A7; gives A7 = 0x04030201
(4) LDDW *A5,A7:A6; gives A7:A6 =
0x0807060504030201
FFFFFFFF
16-bits
25
Using the Load Instructions
The syntax for the load
instruction is:
Data
1
0
0xA
0xB
0xC
0xD
0x2
0x1
Example:
0x4
0x3
If we assume that A5 = 0x4 then:
0x6
0x5
(1) LDB *A5, A7 ; gives A7 = 0x00000001
0x8
0x7
LD *Rn,Rm
address
00000000
00000002
00000004
00000006
00000008
(2) LDH *A5,A7; gives A7 = 0x00000201
(3) LDW *A5,A7; gives A7 = 0x04030201
(4) LDDW *A5,A7:A6; gives A7:A6 =
0x0807060504030201
FFFFFFFF
16-bits
26
Using the Load Instructions
The syntax for the load
instruction is:
LD *Rn,Rm
Question:
If data can only be accessed by the
load instruction and the .D unit,
how can we load the register
pointer Rn in the first place?
address
Data
0xA
0xB
0xC
0xD
0x2
0x1
0x4
0x3
0x6
0x5
0x8
0x7
00000000
00000002
00000004
00000006
00000008
FFFFFFFF
16-bits
27
Loading the Pointer Rn
• The instruction MVKL will allow a move of a 16-bit constant into
a register as shown below:
MVKL .?
a, A5
(‘a’ is a constant or label)
• How many bits represent a full address?
32 bits
• So why does the instruction not allow a 32-bit move?
All instructions are 32-bit wide (see instruction opcode).
28
Loading the Pointer Rn
• To solve this problem another instruction is available:
MVKH
eg.
MVKH
.?
a, A5
(‘a’ is a constant or label)
ah
al
a
ah
x
A5
• Finally, to move the 32-bit address to a register we can
use:
29
MVKL
a, A5
MVKH
a, A5
Loading the Pointer Rn
• Always use MVKL then MVKH, look at the following
examples:
Example 1
A5 = 0x87654321
MVKL
0x1234FABC, A5
A5 = 0xFFFFFABC (sign extension)
MVKH
0x1234FABC, A5
A5 = 0x1234FABC ; OK
Example 2
MVKH
A5 = 0x12344321
30
0x1234FABC, A5
MVKL
0x1234FABC, A5
A5 = 0xFFFFFABC ; Wrong
LDH, MVKL and MVKH
Register File A
A0
A1
a
x
A2
A3
A4
prod
Y
.M
.
.
.
.L
.D
A15
MVKL
MVKH
pt1, A5
pt1, A5
MVKL
MVKH
pt2, A6
pt2, A6
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
32-bits
pt1 and pt2 point to some locations
Data Memory
31
in the data memory.
Creating a loop
So far we have only
implemented the SOP
for one tap only, i.e.
Y= a1 * x1
So let’s create a loop
so that we can
implement the SOP
for N Taps.
32
MVKL
MVKH
pt1, A5
pt1, A5
MVKL
MVKH
pt2, A6
pt2, A6
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
Creating a loop
So far we have only
implemented the SOP
for one tap only, i.e.
Y= a1 * x1
So let’s create a loop
so that we can
implement the SOP
for N Taps.
33
With the C6000 processors
there are no dedicated
instructions such as block
repeat. The loop is created
using the B instruction.
What are the steps for creating a loop
1. Create a label to branch to.
2. Add a branch instruction, B.
3. Create a loop counter.
4. Add an instruction to decrement the loop counter.
5. Make the branch conditional based on the value in
the loop counter.
34
1. Create a label to branch to
loop
35
MVKL
MVKH
pt1, A5
pt1, A5
MVKL
MVKH
pt2, A6
pt2, A6
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
2. Add a branch instruction, B.
loop
36
MVKL
MVKH
pt1, A5
pt1, A5
MVKL
MVKH
pt2, A6
pt2, A6
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
B
.?
loop
Which unit is used by the B instruction?
Register File A
A0
A1
a
x
.S
prod
Y
.M
.M
.
.
.
.L
.L
A2
A3
loop
.D
.D
A15
32-bits
37
Data Memory
MVKL
MVKH
pt1, A5
pt1, A5
MVKL
MVKH
pt2, A6
pt2, A6
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
B
.?
loop
Which unit is used by the B instruction?
Register File A
A0
A1
a
x
.S
prod
Y
.M
.M
.
.
.
.L
.L
A2
A3
loop
.D
.D
A15
32-bits
38
Data Memory
MVKL .S
MVKH .S
pt1, A5
pt1, A5
MVKL .S
MVKH .S
pt2, A6
pt2, A6
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
B
.S
loop
3. Create a loop counter.
Register File A
A0
A1
a
x
.S
prod
Y
.M
.M
.
.
.
.L
.L
A2
A3
loop
.D
.D
A15
32-bits
39
Data Memory
MVKL .S
MVKH .S
pt1, A5
pt1, A5
MVKL .S
MVKH .S
MVKL .S
pt2, A6
pt2, A6
count, B0
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
B
.S
loop
B registers will be introduced later
4. Decrement the loop counter
Register File A
A0
A1
a
x
.S
prod
Y
.M
.M
.
.
.
.L
.L
A2
A3
loop
.D
.D
A15
32-bits
40
Data Memory
MVKL .S
MVKH .S
pt1, A5
pt1, A5
MVKL .S
MVKH .S
MVKL .S
pt2, A6
pt2, A6
count, B0
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
SUB
.S
B0, 1, B0
B
.S
loop
5. Make the branch conditional based on the value
in the loop counter
• What is the syntax for making instruction conditional?
[condition] Instruction
Label
e.g.
[B1] B
loop
(1) The condition can be one of the following
registers: A1, A2, B0, B1, B2.
(2) Any instruction can be conditional.
41
5. Make the branch conditional based on the value
in the loop counter
• The condition can be inverted by adding the exclamation symbol “!”
as follows:
[!condition] Instruction
Label
e.g.
42
[!B0]
B
loop ;branch if B0 = 0
[B0] B
loop
;branch if B0 != 0
5. Make the branch conditional
MVKL .S2 pt1, A5
MVKH .S2 pt1, A5
Register File A
A0
A1
a
x
.S
prod
Y
.M
.M
.
.
.
.L
.L
A2
A3
loop
.D
.D
A15
32-bits
43
MVKL .S2 pt2, A6
MVKH .S2 pt2, A6
MVKL .S2 count, B0
Data Memory
[B0]
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
SUB
.S
B0, 1, B0
B
.S
loop
More on the Branch Instruction (1)
With this processor all the instructions are
encoded in a 32-bit.
Therefore the label must have a dynamic range
of less than 32-bit as the instruction B has to be
coded.
32-bit
B
Case 1:
21-bit relative address
B .S1
label
Relative branch.
Label limited to +/- 220 offset.
44
More on the Branch Instruction (2)
By specifying a register as an operand instead of
a label, it is possible to have an absolute branch.
This will allow a dynamic range of 232.
32-bit
B
Case 2:
B .S2
Absolute branch.
Operates on .S2 ONLY!
45
5-bit register
code
register
Testing the code
MVKL .S2 pt1, A5
MVKH .S2 pt1, A5
MVKL .S2 pt2, A6
MVKH .S2 pt2, A6
MVKL .S2 count, B0
This code performs the following
operations:
loop
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
However, we would like to perform:
ADD
.L
A4, A3, A4
a0*x0 + a1*x1 + a2*x2 + … + aN*xN
SUB
.S
B0, 1, B0
B
.S
loop
a0*x0 + a0*x0 + a0*x0 + … + a0*x0
[B0]
46
Modifying the pointers
MVKL .S2 pt1, A5
MVKH .S2 pt1, A5
MVKL .S2 pt2, A6
MVKH .S2 pt2, A6
MVKL .S2 count, B0
The solution is to modify the pointers
loop
A5 and A6.
[B0]
47
LDH
.D
*A5, A0
LDH
.D
*A6, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
SUB
.S
B0, 1, B0
B
.S
loop
Indexing Pointers
Syntax
Description
*R
Pointer
Pointer
Modified
No
In this case the pointers are used but not modified.
R can be any register
48
Indexing Pointers
Syntax
Description
*R
*+R[disp]
*-R[disp]
Pointer
+ Pre-offset
- Pre-offset
Pointer
Modified
No
No
No
In this case the pointers are modified BEFORE being used
and RESTORED to their previous values.
49
[disp] specifies the number of elements size in DW (64-bit), W
(32-bit), H (16-bit), or B (8-bit).
disp = R or 5-bit constant.
R can be any register.
Indexing Pointers
Syntax
Description
*R
*+R[disp]
*-R[disp]
*++R[disp]
*--R[disp]
Pointer
+ Pre-offset
- Pre-offset
Pre-increment
Pre-decrement
Pointer
Modified
No
No
No
Yes
Yes
In this case the pointers are modified BEFORE being used
and NOT RESTORED to their Previous Values.
50
Indexing Pointers
Syntax
Description
*R
*+R[disp]
*-R[disp]
*++R[disp]
*--R[disp]
*R++[disp]
*R--[disp]
Pointer
+ Pre-offset
- Pre-offset
Pre-increment
Pre-decrement
Post-increment
Post-decrement
Pointer
Modified
No
No
No
Yes
Yes
Yes
Yes
In this case the pointers are modified AFTER being used
and NOT RESTORED to their Previous Values.
51
Indexing Pointers
Syntax
Description
*R
*+R[disp]
*-R[disp]
*++R[disp]
*--R[disp]
*R++[disp]
*R--[disp]
Pointer
+ Pre-offset
- Pre-offset
Pre-increment
Pre-decrement
Post-increment
Post-decrement
52
Pointer
Modified
No
No
No
Yes
Yes
Yes
Yes
[disp] specifies # elements - size in DW, W, H, or B.
disp = R or 5-bit constant.
R can be any register.
Modify and testing the code
MVKL .S2 pt1, A5
MVKH .S2 pt1, A5
MVKL .S2 pt2, A6
MVKH .S2 pt2, A6
MVKL .S2 count, B0
This code now performs the following
loop
operations:
a0*x0 + a1*x1 + a2*x2 + ... + aN*xN
[B0]
53
LDH
.D
*A5++, A0
LDH
.D
*A6++, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
SUB
.S
B0, 1, B0
B
.S
loop
Store the final result
MVKL .S2 pt1, A5
MVKH .S2 pt1, A5
MVKL .S2 pt2, A6
MVKH .S2 pt2, A6
MVKL .S2 count, B0
This code now performs the following
loop
operations:
a0*x0 + a1*x1 + a2*x2 + ... + aN*xN
[B0]
54
LDH
.D
*A5++, A0
LDH
.D
*A6++, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
SUB
.S
B0, 1, B0
B
.S
loop
STH
.D
A4, *A7
Store the final result
MVKL .S2 pt1, A5
MVKH .S2 pt1, A5
MVKL .S2 pt2, A6
MVKH .S2 pt2, A6
MVKL .S2 count, B0
loop
The Pointer A7 has not been initialized.
[B0]
55
LDH
.D
*A5++, A0
LDH
.D
*A6++, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
SUB
.S
B0, 1, B0
B
.S
loop
STH
.D
A4, *A7
Store the final result
MVKL .S2 pt1, A5
MVKH .S2 pt1, A5
MVKL .S2 pt2, A6
MVKH .S2 pt2, A6
MVKL .S2 pt3, A7
MVKH .S2 pt3, A7
MVKL .S2 count, B0
The Pointer A7 is now initialized.
loop
[B0]
56
LDH
.D
*A5++, A0
LDH
.D
*A6++, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
SUB
.S
B0, 1, B0
B
.S
loop
STH
.D
A4, *A7
What is the initial value of A4?
MVKL .S2 pt1, A5
MVKH .S2 pt1, A5
MVKL .S2 pt2, A6
MVKH .S2 pt2, A6
A4 is used as an accumulator,
so it needs to be reset to zero.
loop
[B0]
57
MVKL
MVKH
MVKL
ZERO
LDH
.S2
.S2
.S2
.L
.D
pt3, A7
pt3, A7
count, B0
A4
*A5++, A0
LDH
.D
*A6++, A1
MPY
.M
A0, A1, A3
ADD
.L
A4, A3, A4
SUB
.S
B0, 1, B0
B
.S
loop
STH
.D
A4, *A7
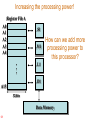
Increasing the processing power!
Register File A
A0
A1
A2
A3
A4
.S1
.M1
.
.
.
How can we add more
processing power to
this processor?
.L1
.D1
A15
32-bits
Data Memory
58
Increasing the processing power!
Register File A
A0
A1
A2
A3
A4
.S1
.M1
.
.
.
(1) Increase the clock
frequency.
(2) Increase the number
of Processing units.
.L1
.D1
A15
32-bits
Data Memory
59
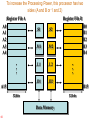
To increase the Processing Power, this processor has two
sides (A and B or 1 and 2)
Register File A
Register File B
A0
B0
.S1
.S2
A1
B1
A2
B2
A3
B3
.M1
.M2
A4
B4
.
.
.
A15
.L1
.L2
.D1
.D2
32-bits
B15
32-bits
Data Memory
60
.
.
.
Can the two sides exchange operands in order to increase
performance?
Register File A
Register File B
A0
B0
.S1
.S2
A1
B1
A2
B2
A3
B3
.M1
.M2
A4
B4
.
.
.
A15
.L1
.L2
.D1
.D2
32-bits
B15
32-bits
Data Memory
61
.
.
.
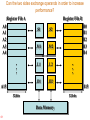
The answer is YES but there are limitations.
To exchange operands between the two
sides, some cross paths or links are
required.
What is a cross path?
62
A cross path links one side of the CPU to
the other.
There are two types of cross paths:
Data cross paths.
Address cross paths.
Data Cross Paths
63
Data cross paths can also be referred to
as register file cross paths.
These cross paths allow operands from
one side to be used by the other side.
There are only two cross paths:
one path which conveys data from side B
to side A, 1X.
one path which conveys data from side A
to side B, 2X.
TMS320C67x Data-Path
64
Data Cross Paths
65
Data cross paths only apply to the .L, .S
and .M units.
The data cross paths are very useful,
however there are some limitations in
their use.
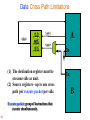
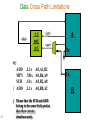
Data Cross Path Limitations
<dst>
.L1
.M1
.S1
<src>
(1) The destination register must be
on same side as unit.
(2) Source registers - up to one cross
path per execute packet per side.
Execute packet: group of instructions that
execute simultaneously.
66
A
<src>
2x
1x
B
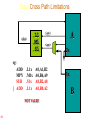
Data Cross Path Limitations
<dst>
eg:
ADD
MPY
SUB
|| ADD
67
.L1
.M1
.S1
.L1x
.M1x
.S1x
.L1x
A
<src>
<src>
A0,A1,B2
A0,B6,A9
A8,B2,A8
A0,B0,A2
|| Means that the SUB and ADD
belong to the same fetch packet,
therefore execute
simultaneously.
2x
1x
B
Data Cross Path Limitations
<dst>
eg:
ADD
MPY
SUB
|| ADD
.L1
.M1
.S1
.L1x
.M1x
.S1x
.L1x
68
<src>
A0,A1,B2
A0,B6,A9
A8,B2,A8
A0,B0,A2
NOT VALID!
A
<src>
2x
1x
B
Data Cross Paths for both sides
<dst>
<dst>
69
.L1
.M1
.S1
.L2
.M2
.S2
A
<src>
<src>
2x
<src>
<src>
1x
B
Address cross paths
Data
Addr
A
.D1
(1) The pointer must be on the same
side of the unit.
LDW.D1T1 *A0,A5
STW.D1T1 A5,*A0
70
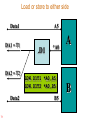
Load or store to either side
Data1
DA1 = T1
DA2 = T2
Data2
71
A5
.D1
*A0
LDW.D1T1 *A0,A5
LDW.D1T2 *A0,B5
B5
A
B
Standard Parallel Loads
Data1
DA1 = T1
DA2 = T2
A5
.D1
*A0
.D2
*B0
A
B
LDW.D1T1 *A0,A5
|| LDW.D2T2 *B0,B5
72
B5
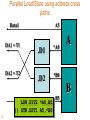
Parallel Load/Store using address cross
paths
Data1
DA1 = T1
DA2 = T2
A5
.D1
*A0
.D2
*B0
A
B
LDW.D1T2 *A0,B5
|| STW.D2T1 A5,*B0
73
B5
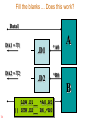
Fill the blanks ... Does this work?
Data1
DA1 = T1
DA2 = T2
.D1
*A0
.D2
*B0
A
B
LDW.D1__ *A0,B5
|| STW.D2__ B6,*B0
74
Not Allowed!
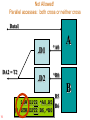
Parallel accesses: both cross or neither cross
Data1
DA2 = T2
.D1
*A0
.D2
*B0
B5
LDW.D1T2 *A0,B5
B6
|| STW.D2T2 B6,*B0
75
A
B
Conditions Don’t Use Cross Paths
• If a conditional register comes from the opposite side,
it does NOT use a
data or address cross-path.
• Examples:
[B2]
[A1]
76
ADD
LDW
.L1
.D2
A2,A0,A4
*B0,B5
‘C62x Data-Path Summary
CPU
Ref Guide
Full CPU Datapath
(Pg 2-2)
77
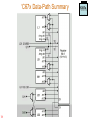
‘C67x Data-Path Summary
78
‘C67x
Cross Paths - Summary
•
• Address
79
Data
– Destination register on same side as unit.
– Source registers - up to one cross path per execute
packet per side.
– Use “x” to indicate cross-path.
– Pointer must be on same side as unit.
– Data can be transferred to/from either side.
– Parallel accesses: both cross or neither cross.
Conditionals Don’t Use Cross Paths.
Code Review (using side A only)
40
Y =
n = 1
MVK
loop: LDH
LDH
MPY
ADD
SUB
[A2] B
STH
.S1
.D1
.D1
.M1
.L1
.L1
.S1
.D1
an * xn
40, A2
*A5++, A0
*A6++, A1
A0, A1, A3
A3, A4, A4
A2, 1, A2
loop
A4, *A7
; A2 = 40, loop count
; A0 = a(n)
; A1 = x(n)
; A3 = a(n) * x(n)
; Y = Y + A3
; decrement loop count
; if A2 0, branch
; *A7 = Y
Note: Assume that A4 was previously cleared and the pointers are initialised.
80
Dual Resources : Twice as Nice
Register File A
A0
A1
A2
A3
A4
A5
A6
A7
..
A15
or
A31
104
cn
xn
cnt
prd
sum
*c
*x
*y
..
32-bits
Register File B
.S1
.S2
.M1
.M2
.L1
.L2
.D1
.D2
..
32-bits
B0
B1
B2
B3
B4
B5
B6
B7
..
B15
or
B31
Our final view of the sum of products example...
Optional - Resource Specific Coding
40
y =
Register File A
A0
A1
A2
A3
A4
A5
A6
A7
..
A15
or
A31
105
cn
xn
cnt
prd
sum
*c
*x
*y
..
32-bits
cn * xn
n = 1
.S1
loop:
.M1
.L1
MVK
.S1
40, A2
LDH
.D1
*A5++, A0
LDH
.D1
*A6++, A1
MPY
.M1
A0, A1, A3
ADD
.L1
A4, A3, A4
SUB
.S1
A2, 1, A2
.S1
loop
.D1
A4, *A7
[A2] B
.D1
STW
It’s easier to use symbols rather than
register names, but you can use
either method.
TMS320C6000 Instruction Set
106
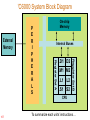
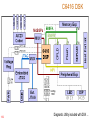
'C6000 System Block Diagram
External
Memory
Internal Buses
.D1 .D2
.M1 .M2
.L1 .L2
.S1 .S2
Reggister Set B
Register Set A
P
E
R
I
P
H
E
R
A
L
S
On-chip
Memory
CPU
107
To summarize each units’ instructions ...
‘C62x RISC-like instruction set
.S Unit
.S
.L
.D
ADD
ADDK
ADD2
AND
B
CLR
EXT
MV
MVC
MVK
MVKH
NEG
NOT
OR
SET
SHL
SHR
SSHL
SUB
SUB2
XOR
ZERO
108
ABS
ADD
AND
CMPEQ
CMPGT
CMPLT
LMBD
MV
NEG
NORM
NOT
OR
SADD
SAT
SSUB
SUB
SUBC
XOR
ZERO
.M Unit
.D Unit
.M
.L Unit
ADD
NEG
ADDAB (B/H/W) STB
(B/H/W)
LDB
(B/H/W) SUB
SUBAB (B/H/W)
MV
ZERO
MPY
MPYH
MPYLH
MPYHL
SMPY
SMPYH
No Unit Used
NOP
IDLE
'C62x RISC-Like Instruction Set (by category)
Arithmetic
Logical
ABS
ADD
ADDA
ADDK
ADD2
MPY
MPYH
NEG
SMPY
SMPYH
SADD
SAT
SSUB
SUB
SUBA
SUBC
SUB2
ZERO
AND
CMPEQ
CMPGT
CMPLT
NOT
OR
SHL
SHR
SSHL
XOR
Bit Mgmt
CLR
EXT
LMBD
NORM
SET
Data Mgmt
LDB/H/W
MV
MVC
MVK
MVKL
MVKH
MVKLH
STB/H/W
Program Ctrl
B
IDLE
NOP
Note: Refer to the 'C6000 CPU Reference Guide for more details.
109
‘C67x: Superset of Fixed-Point (by units)
.S Unit
.S
.L
.D
ADD
ADDK
ADD2
AND
B
CLR
EXT
MV
MVC
MVK
MVKH
NEG
NOT
OR
SET
SHL
SHR
SSHL
SUB
SUB2
XOR
ZERO
ABSSP
ABSDP
CMPGTSP
CMPEQSP
CMPLTSP
CMPGTDP
CMPEQDP
CMPLTDP
RCPSP
RCPDP
RSQRSP
RSQRDP
SPDP
.D Unit
.M
110
ADD
NEG
ADDAB (B/H/W) STB
(B/H/W)
LDB
(B/H/W) SUB
LDDW
SUBAB (B/H/W)
MV
ZERO
.L Unit
ABS
ADD
AND
CMPEQ
CMPGT
CMPLT
LMBD
MV
NEG
NORM
NOT
OR
SADD
SAT
SSUB
SUB
SUBC
XOR
ZERO
ADDSP
ADDDP
SUBSP
SUBDP
INTSP
INTDP
SPINT
DPINT
SPRTUNC
DPTRUNC
DPSP
.M Unit
MPY
MPYH
MPYLH
MPYHL
SMPY
SMPYH
MPYSP
MPYDP
MPYI
MPYID
No Unit Required
NOP
IDLE
'C64x: Superset of ‘C62x Instruction Set
.S
.D
111
Dual/Quad Arith
SADD2
SADDUS2
SADD4
Data Pack/Un
PACK2
PACKH2
PACKLH2
PACKHL2
Bitwise Logical UNPKHU4
ANDN
UNPKLU4
Shifts & Merge SWAP2
SPACK2
SHR2
SPACKU4
SHRU2
SHLMB
SHRMB
Dual Arithmetic Mem Access
ADD2
LDDW
SUB2
LDNW
LDNDW
Bitwise Logical STDW
AND
STNW
ANDN
STNDW
OR
XOR
Load Constant
MVK (5-bit)
Address Calc.
ADDAD
Compares
CMPEQ2
CMPEQ4
CMPGT2
CMPGT4
.L
Branches/PC
BDEC
BPOS
BNOP
ADDKPC
Dual/Quad Arith
ABS2
ADD2
ADD4
MAX
MIN
SUB2
SUB4
SUBABS4
Bitwise Logical
ANDN
.M
Average
AVG2
AVG4
Shifts
ROTL
SSHVL
SSHVR
Data Pack/Un
PACK2
PACKH2
PACKLH2
PACKHL2
PACKH4
PACKL4
UNPKHU4
UNPKLU4
SWAP2/4
Multiplies
MPYHI
Shift & Merge
MPYLI
SHLMB
MPYHIR
SHRMB
MPYLIR
Load Constant
MPY2
MVK (5-bit)
SMPY2
Bit Operations DOTP2
DOTPN2
BITC4
DOTPRSU2
BITR
DOTPNRSU2
DEAL
DOTPU4
SHFL
DOTPSU4
Move
GMPY4
MVD
XPND2/4
Sample C62x Compiler Benchmarks
Algorithm
Used In
Asm
Cycles
Assembly Time
(s)
C Cycles
(Rel 4.0)
C Time (s)
% Efficiency vs
Hand Coded
Block Mean Square Error
MSE of a 20 column image matrix
For motion
compensation of
image data
348
1.16
402
1.34
87%
Codebook Search
CELP based voice
coders
977
3.26
961
3.20
100%
Vector Max
40 element input vector
Search Algorithms
61
0.20
59
0.20
100%
VSELP based voice
coders
238
0.79
280
0.93
85%
Search Algorithms
1185
3.95
1318
4.39
90%
IIR Filter
16 coefficients
Filter
43
0.14
38
0.13
100%
IIR – cascaded biquads
10 Cascaded biquads (Direct Form
II)
Filter
70
0.23
75
0.25
93%
VSELP based voice
coders
61
0.20
58
0.19
100%
51
0.17
47
0.16
100%
279
0.93
274
0.91
100%
All-zero FIR Filter
40 samples,
10 coefficients
Minimum Error Search
Table Size = 2304
MAC
Two 40 sample vectors
Vector Sum
Two 44 sample vectors
MSE
MSE between two 256 element
vectors
112
Mean Sq. Error
Computation in
Vector Quantizer
Completely natural C code (non ’C6000 specific)
Code available at: http://www.ti.com/sc/c6000compiler
TI C62x™ Compiler Performance Release 4.0: Execution Time in s @ 300 MHz
Versus hand-coded assembly based on cycle count
Sample Imaging & Telecom Benchmarks
DSP & Image Processing
Kernels
Cycle Count
Performance
C62x
C64x
Reed Solomon Decode: Syndrome
Accumulation
(204,188,8) Packet
1680
470
Viterbi Decode (GSM)
(16 states)
38.25
FFT - Radix 4 - Complex
(size = N log (N)) (16-bit)
12.7
Polyphase Filter - Image Scaling
(8-bit)
0.77
Correlation - 3x3
(8-bit)
4.5
Median Filter - 3x3
(8-bit)
9.0
Motion Estimation - 8x8 MAD (8-bit)
cycles/packet
14*
cycles/output
6.0
cycles/data
0.33
cycles/output/filter tap
1.28
cycles/pixel
2.1
cycles/pixel
0.953
0.126
cycles/pixel
*
113
Includes traceback
Cycle Improvement
C64:C62
720MHz C64x vs
300MHz C62x
3.5x
8.4x
2.7x
6.5x
2.1x
5x
2.3x
5.5x
3.5x
8.4x
4.3x
10.3x
7.6x
18.2x
Sample C62x Compiler Benchmarks
Algorithm
Used In
Asm
Cycles
Assembly Time
(s)
C Cycles
(Rel 4.0)
C Time (s)
% Efficiency vs
Hand Coded
Block Mean Square Error
MSE of a 20 column image matrix
For motion
compensation of
image data
348
1.16
402
1.34
87%
Codebook Search
CELP based voice
coders
977
3.26
961
3.20
100%
Vector Max
40 element input vector
Search Algorithms
61
0.20
59
0.20
100%
VSELP based voice
coders
238
0.79
280
0.93
85%
Search Algorithms
1185
3.95
1318
4.39
90%
IIR Filter
16 coefficients
Filter
43
0.14
38
0.13
100%
IIR – cascaded biquads
10 Cascaded biquads (Direct Form
II)
Filter
70
0.23
75
0.25
93%
VSELP based voice
coders
61
0.20
58
0.19
100%
51
0.17
47
0.16
100%
279
0.93
274
0.91
100%
All-zero FIR Filter
40 samples,
10 coefficients
Minimum Error Search
Table Size = 2304
MAC
Two 40 sample vectors
Vector Sum
Two 44 sample vectors
MSE
MSE between two 256 element
vectors
114
Mean Sq. Error
Computation in
Vector Quantizer
Completely natural C code (non ’C6000 specific)
Code available at: http://www.ti.com/sc/c6000compiler
TI C62x™ Compiler Performance Release 4.0: Execution Time in s @ 300 MHz
Versus hand-coded assembly based on cycle count
TMS320C6000 Memory
116
Memory size per device
Devices
C6201,
C6204,
C6701
C6205
EMIFA
EMIFB
P
D
=
=
64 kB
64 kB
C6202
P
D
=
=
256 kB
128 kB
C6203
P
D
=
=
384 kB
512 kB
L1P
L1D
L2
=
=
=
4 kB
4 kB
64 kB
C6713
L1P
L1D
L2
=
=
=
4 kB
4 kB
256 kB
128M Bytes
(32-bits wide)
N/A
C6411
DM642
L1P
L1D
L2
=
=
=
16 kB
16 kB
256 kB
128M Bytes
(32-bits wide)
N/A
C6414
C6415
C6416
L1P
L1D
L2
=
=
=
16 kB
16 kB
1 MB
256M Bytes
(64-bits wide)
C6211
C6711
C6712
117
Internal
52M Bytes
(32-bits wide)
128M Bytes
(32-bits wide)
N/A
N/A
64M Bytes
(16-bits wide)
64M Bytes
(16-bits wide)
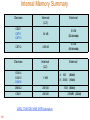
Internal Memory Summary
Devices
Internal
(L2)
C6211
C6711
C6713
64 kB
512M
(32-bit wide)
C6712
256 kB
512M
(16-bit wide)
Devices
Internal
(L2)
C6414
C6415
C6416
1 MB
DM642
256 kB
C6411
256 kB
LINK: TMS320C6000 DSP Generation
118
External
External
A: 1GB
B: 256kB
(64-bit)
(16-bit)
1GB (64-bit)
256MB (32-bit)
Performance
Making use of Parallelism
Given this simple loop …
40
y =
cn * xn
n = 1
c
x
cnt
prod
y
*cp
*xp
*yp
.S1
short mac(short *c, short *x, int count) {
for (i=0; i < count; i++) {
sum += c[i] * x[i]; } …
.M1
.S1
40, cnt
LDH
.D1
*cp++, c
LDH
.D1
*xp++, x
MPY
.M1
c, x, prod
ADD
.L1
y, prod, y
SUB
.L1
cnt, 1, cnt
B
.S1
loop
STW
.D
y, *yp
loop:
.L1
.D1
[cnt]
120
MVK
How many of these instructions can we get in parallel?
C62x Intense Parallelism
short mac(short *c, short *x, int count) {
for (i=0; i < count; i++) {
sum += c[i] * x[i]; } …
MPY
||
MPYH
|| [B0] B
||
LDW
||
LDW
.M2
.M1
.S1
.D1
.D2
B7,A3,B4
B7,A3,A5
L3
*A4++,A3
*B6++,B7
L2: ; PIPED LOOP PROLOG
MPY .M2 B7,A3,B4
||
MPYH .M1 B7,A3,A5
Given this
code
LDW C
.D1
*A4++,A3
|| [B0] B
.S1 L3
||
LDW .D2 *B6++,B7
||
LDW .D1 *A4++,A3
The C62x compiler can achieve||
LDW .D2 *B6++,B7
LDW .D1 *A4++,A3
;** -----------------------*
Two
|| Sum-of-Products
LDW .D2 *B6++,B7 per cycle
L3:
[B0] B
.S1 L3
||
LDW .D1 *A4++,A3
||
LDW .D2 *B6++,B7
[B0] B
.S1 L3
||
LDW .D1 *A4++,A3
||
LDW .D2 *B6++,B7
[B0] B
.S1 L3
||
LDW .D1 *A4++,A3
||
LDW .D2 *B6++,B7
||
||
||
||
||
||
||
; PIPED LOOP KERNEL
ADD .L2 B4,B5,B5
ADD .L1 A5,A0,A0
MPY .M2 B7,A3,B4
MPYH .M1 B7,A3,A5
[B0]B
.S1 L3
[B0]SUB .S2 B0,1,B0
LDW .D1 *A4++,A3
LDW .D2 *B6++,B7
;** -----------------------*
121
What about the ‘C67x?
C67x MAC using Natural C
Memory
The C67x compiler gets two 32-bit
A0
B0
.D1
.D2
floating-point
Sum-of-Products per iteration
.M1
.M2
.L1
.L2
..
A15
..
.S1
.S2
Controller/Decoder
122
B15
float mac(float *c, float *x, int count)
{ int i, float sum = 0;
for (i=0; i < count; i++) {
sum += c[i] * x[i]; } …
;** --------------------------------------------------*
LOOP: ; PIPED LOOP KERNEL
LDDW .D1
A4++,A7:A6
||
LDDW .D2
B4++,B7:B6
||
MPYSP .M1X
A6,B6,A5
||
MPYSP .M2X
A7,B7,B5
||
ADDSP .L1
A5,A8,A8
||
ADDSP .L2
B5,B8,B8
|| [A1] B
.S2
LOOP
|| [A1] SUB
.S1
A1,1,A1
;** --------------------------------------------------*
Can the 'C64x do better?
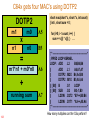
C64x gets four MAC’s using DOTP2
short mac(short *c, short *x, int count)
{ int i, short sum = 0;
DOTP2
m1
m0
A5
n0
B5
x
n1
=
m1*n1 + m0*n0
A6
+
running sum
123
A7
for (i=0; i < count; i++) {
sum += c[i] * x[i]; } …
;** --------------------------------------------------*
; PIPED LOOP KERNEL
LOOP: ADD
.L2
B8,B6,B6
||
ADD
.L1
A6,A7,A7
||
DOTP2 .M2X B4,A4,B8
||
DOTP2 .M1X B5,A5,A6
|| [ B0] B
.S1
LOOP
|| [ B0] SUB
.S2
B0,-1,B0
||
LDDW .D2T2 *B7++,B5:B4
||
LDDW .D1T1 *A3++,A5:A4
;** --------------------------------------------------*
How many multiplies can the ‘C6x perform?
MMAC’s
How many 16-bit MMACs (millions of MACs per second)
can the 'C6201 perform?
400 MMACs
(two .M units x 200 MHz)
How about 16x16 MMAC’s on the ‘C64x devices?
2 .M units
x
2 16-bit MACs (per .M unit / per cycle)
x 720 MHz
---------------2880 MMACs
How many 8-bit MMACs on the ‘C64x?
5760 MMACs (on 8-bit data)
124
How Do We Get Such High Parallelism?
Compiler and Assembly Optimizer use a technique called Software Pipelining
Software pipelining enables high performance
(esp. on DSP-type loops)
Key point: Tools do all the work!
125
What is software pipelining?
Let's look at a simple example ...
Tools Use Software Pipelining
Here’s a simple example to demonstrate ...
LDH
||
How many cycles would
it take to perform this
loop 5 times?
LDH
MPY
5 x 3 = 15
______________
cycles
ADD
126
Our functional units could be used like ...
Without Software Pipelining
Cycle
.D1
.D2
1
ldh
ldh
2
.M1
ldh
.S1
.S2
ldh
mpy
6
127
.L2
add
5
7
.L1
mpy
3
4
.M2
add
ldh
ldh
In seven cycles, we’re almost half-way done ...
With Software Pipelining
Cycle
.D1
.D2
1
ldh
ldh
2
ldh
ldh
mpy
3
ldh
ldh
mpy
add
4
ldh
ldh
mpy
add
Completes
in only 7 cycles
5
ldh
ldh
mpy
add
mpy
add
6
7
128
.M1
.M2
.L1
.L2
.S1
.S2
add
It takes 1/2 the time! How does this translate to code?
S/W Pipelining Translated to Code
c1:
Cycle
1
.D1
ldh
.D2
ldh
2
ldh
ldh
mpy
3
ldh
ldh
mpy
c2:
add
4
ldh
ldh
mpy
add
5
ldh
ldh
mpy
add
mpy
add
6
7
129
||
add
.S1
LDH
LDH
.S2
||
||
MPY
LDH
LDH
||
||
||
ADD
MPY
LDH
LDH
c3:
DSK
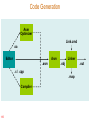
Code Composer Studio
C6416 DSK
131
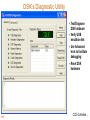
Diagnostic Utility included with DSK ...
C6416 DSK
132
Diagnostic Utility included with DSK ...
DSK’s Diagnostic Utility
133
Test/Diagnose
DSK hardware
Verify USB
emulation link
Use Advanced
tests to facilitate
debugging
Reset DSK
hardware
CCS Overview ...
Code Composer Studio
Standard
Runtime
Libraries
Compiler
Asm Opto
SIM
DSK
Asm
Edit
Link
.out
Debug
EVM
DSP/BIOS
Config
Tool
DSP/BIOS
Libraries
Third
Party
DSK’s Code Composer Studio Includes:
Integrated Edit / Debug GUI Simulator
Code Generation Tools
BIOS: Real-time kernel
Real-time analysis
134
XDS
DSP
Board
CCS is Project centric ...
Code Generation
Asm
Optimizer
Link.cmd
.sa
Asm
Editor
.asm
Linker
.obj
.out
.c / .cpp
.map
Compiler
135
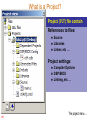
What is a Project?
Project (.PJT) file contain:
References to files:
Source
Libraries
Linker, etc …
Project settings:
136
Compiler Options
DSP/BIOS
Linking, etc …
The project menu ...
Project Menu
Hint:
Project Menu
Create
andvia
open
projects
Access
pull-down
menu
by right-clicking
.pjt file
fromorthe
Project menu,
in project explorer window
not the File menu.
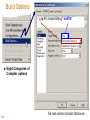
Build Options...
137
Next slide
Build Options
-g -q -fr"c:\modem\Debug" -mv6700
138
Eight Categories of
Compiler options
The most common Compiler Options are ...
Compiler’s Build Options
debug
options
140
Nearly one-hundred compiler options available to
tune your code's performance, size, etc.
Following table lists the most common options:
Options
Description
-mv6700
-mv6400
-fr <dir>
-fs <dir>
-q
-g
-s
Generate ‘C67x code (‘C62x is default)
Generate 'C64x code
Directory for object/output files
Directory for assembly files
Quiet mode (display less info while compiling)
Enables src-level symbolic debugging
Interlist C statements into assembly listing
In Chapter 4 we will examine the options which
enable the compiler’s optimizer
And, the Config Tool ...
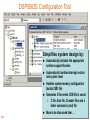
DSP/BIOS Configuration Tool
Simplifies system design by:
142
Automatically includes the appropriate
runtime support libraries
Automatically handles interrupt vectors
and system reset
Handles system memory configuration
(builds CMD file)
Generates 5 files when CDB file is saved:
C file, Asm file, 2 header files and a
linker command (.cmd) file
More to be discussed later …
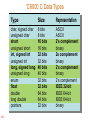
‘C6000 C Data Types
143
Type
Size
Representation
char, signed char
unsigned char
short
unsigned short
int, signed int
unsigned int
long, signed long
unsigned long
enum
float
double
long double
pointers
8 bits
8 bits
16 bits
16 bits
32 bits
32 bits
40 bits
40 bits
32 bits
32 bits
64 bits
64 bits
32 bits
ASCII
ASCII
2’s complement
binary
2s complement
binary
2’s complement
binary
2’s complement
IEEE 32-bit
IEEE 64-bit
IEEE 64-bit
binary
GEL Scripting
GEL: General Extension
Language
C style syntax
Large number of debugger
commands as GEL functions
Write your own functions
Create GEL menu items
146
CCS Scripting
147
Debug using VB Script or Perl
Using CCS Scripting, a simple script can:
Start CCS
Load a file
Read/write memory
Set/clear breakpoints
Run, and perform other basic testing
functions
TCONF Scripting (CDB)
Tconf Script (.tcf)
hello_dsk62cfg.tcf
utils.loadPlatform("dsk6211");
utils.getProgObjs(prog);
LOG_system.bufLen = 128;
utils.importFile("hello");
prog.gen();
Tconf Include File (.tci)
var trace = LOG.create("trace");
trace.bufLen = 32;
/* load DSK6211 platform into TCOM */
/* make all prog objects JavaScript global vars */
/* set buffer length of LOG_system to 128 */
/* import portable application script */
/* generate cfg files (and CDB file) */
hello.tci
/* create a new user log, named trace */
/* initialize its length to 32 (words) */
Your Application
hello.c
#include <log.h>
extern LOG_Obj trace;
/* created in hello.tci */
int main() {
• A textual way to configure CDB files
LOG_printf(&trace, "Hello World!\n");
• Runs on both PC and Unix
return (0);
}
• Create #include type files (.tci)
• More flexible than Config Tool
148
Chapter 2
TMS320C6000 Architectural Overview
- End -