Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
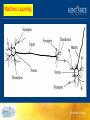
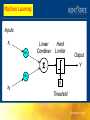
Machine Learning Mehdi Ghayoumi MSB rm 132 [email protected] Ofc hr: Thur, 11-12 a Machine Learning THE NAÏVE BAYES CLASSIFIER In the naïve Bayes classification scheme, the required estimate of the pdf at a point x=[x(1),...,x(l)]T∈Rl is given as That is, the components of the feature vector x are assumed to be statistically independent. Machine Learning Example . Generate a set X1 that consists of N1 = 50 5-dimensional data vectors that stem from two classes, ω1 and ω2. The classes are modeled by Gaussian distributions with means m1 = [0,0,0,0,0]T and m2 = [1,1,1,1,1]T and respective covariance matrices Machine Learning Step 1. Classify the points of the test set X2 using the naive Bayes classifier, where for a given x, p(x|ωi ) is estimated as Machine Learning Step 2. Compute the ML estimates of m1, m2, S1, and S2 using X1. Employ the ML estimates in the Bayesian classifier Machine Learning Step 3. Compare the results obtained in steps 1 and 2. The resulting classification errors—naive_error and Bayes_ML_error—are 0.1320 and 0.1426, respectively. In other words, the naive classification scheme outperforms the standard ML-based scheme. Machine Learning The techniques that are built around the optimal Bayesian classifier rely on the estimation of the pdf functions describing the data distribution in each class. Machine Learning Machine Learning Machine Learning Machine Learning The focus is on the direct design of a discriminant function/decision surface that separates the classes in some optimal sense according to an adopted criterion. Machine Learning Machine learning involves adaptive mechanisms that enable computers to learn from experience, learn by example and learn by analogy. Learning capabilities can improve the performance of an intelligent system over time. The most popular approaches to machine learning are artificial neural networks and genetic algorithms. This lecture is dedicated to neural networks. Machine Learning • Cell structures – Cell body – Dendrites – Axon – Synaptic terminals Machine Learning • Networks of processing units (neurons) with connections (synapses) between them • Large number of neurons: 1010 • Large connectitivity: 105 • Parallel processing • Distributed computation/memory • Robust to noise, failures Machine Learning Understanding the Brain • Levels of analysis (Marr, 1982) 1. Computational theory 2. Representation and algorithm 3. Hardware implementation • Reverse engineering: From hardware to theory • Parallel processing: SIMD vs MIMD Machine Learning Real Neural Learning • Synapses change size and strength with experience. • Hebbian learning: When two connected neurons are firing at the same time, the strength of the synapse between them increases. • “Neurons that fire together, wire together.” Machine Learning Synapse Axon Soma Synapse Dendrites Axon Soma Dendrites Synapse Machine Learning Biological Neural Network Soma Dendrite Axon Synapse Artificial Neural Network Neuron Input Output Weight Machine Learning Neural Network Learning • Learning approach based on modeling adaptation in biological neural systems. • Perceptron: Initial algorithm for learning simple neural networks (single layer) developed in the 1950’s. • Backpropagation: More complex algorithm for learning multi-layer neural networks developed in the 1980’s. Machine Learning Perceptron Learning Algorithm • First neural network learning model in the 1960’s • Simple and limited (single layer models) • Basic concepts are similar for multi-layer models so this is a good learning tool • Still used in many current applications Machine Learning Input Signals Weights Output Signals x1 Y w1 x2 w2 Neuron wn xn Y Y Y Machine Learning Step function Sign function Sigmoid function Linear function Y Y Y Y +1 +1 1 1 0 X 0 X -1 -1 1, if X 0 step Y 0, if X 0 0 -1 1, if X 0 sigmoid sign Y Y 1, if X 0 X 0 -1 1 1 e X Y linear X X Machine Learning Inputs x1 w1 Linear Combiner Hard Limiter Output Y w2 x2 Threshold Machine Learning Perceptron Node – Threshold Logic Unit x1 w 1 x2 w q z 2 xn n w n 1 if åx w ³q i i i =1 z= n 0 if åx w <q i i =1 i Machine Learning x1 w 1 x2 q w z 2 xn w n • Learn weights such that an n objective function is maximized. • What objective function should we use? • What learning algorithm should we use? 1 if åx w ³q i i i =1 z= n 0 if åx w <q i i =1 i Machine Learning Perceptron Learning Algorithm x1 .4 z .1 x2 -.2 n x1 x2 t .8 .3 1 .4 .1 0 1 if åx w ³q i i i =1 z= n 0 if åx w <q i i =1 i Machine Learning First Training Instance .8 .4 z =1 .1 .3 -.2 net = .8*.4 + .3*-.2 = .26 n x1 x2 t .8 .3 1 .4 .1 0 1 if åx w ³q i i i =1 z= n 0 if åx w <q i i =1 i Machine Learning Second Training Instance .4 .4 .1 .1 -.2 net = .4*.4 + .1*-.2 = .14 n x1 x2 t .8 .3 1 .4 .1 0 1 if åx w ³q i i i =1 z= n 0 if z =1 åx w <q i i =1 i Thank you!




































![Neuron [or Nerve Cell]](http://s1.studyres.com/store/data/000229750_1-5b124d2a0cf6014a7e82bd7195acd798-150x150.png)
