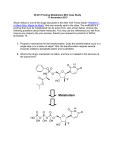
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
10.34, Numerical Methods Applied to Chemical Engineering
Professor William H. Green
Lecture #22: Introduction: Models vs. Data.
Models vs. Data
Engineers think of practical problems and efficient solutions from the top-down.
Scientists use a micro-view and can neglect the big picture in the bottom-up analysis.
Models are always wrong.
But experiments also never match.
more important
p(k)
Ymodel(x(±δx), θ±δθ)
“knobs”
parameters
in model we can
physically adjust
all other
we generally
parameters
know bounds
that affect
on θ
results
prior information
(cannot control)
about θ
diffusion
limit
Figure 1. Normal
distribution.
seldom have sampling capable of making
Ydata(1)(x)
P(Ydata(x))
Ydata(2)(x)
true distribution curve
Ydata
Figure 2. Example of sampling.
Average Value
<Ydata>Nexpts
P(<Ydata>,σdata)≈
P(<Y>Nexpts)
⎡ − (< Y > − < Y > true )2 ⎤
exp ⎢
⎥
2
2σ mean
σ 2π
⎣⎢
⎦⎥
1
σexp.data|Nexpts
<Y>Nexpts
σ mean ≈ σ data
N exp ts
Figure 3. Normal distribution curve
showing 1 standard deviation.
Why do we compare the model to data?
•
Is The Model Consistent With The Data?
|<Ydata> - Ymodel |>> σmean means Inconsistent (akin to confidence interval:
CI ≅ tα ,ν ⋅ σ mean )
Cite as: William Green, Jr., course materials for 10.34 Numerical Methods Applied to Chemical Engineering, Fall
2006. MIT OpenCourseWare (http://ocw.mit.edu), Massachusetts Institute of Technology. Downloaded on [DD
Month YYYY].
•
Model Discrimination
Often more than 1 model: If they are consistent, would like to be able to pick one closer
to the data or say that either model works fine.
•
Parameter Refinement
How narrow can you make the range on θ?
•
Experimental Design
Identify which {θi} are not determined by data. A few θi often control the fit. Some θi
cannot be determined well by experiment (poorly conditioned matrices).
Introduction to Chi-Squared Analysis
Assume all error is Gaussian.
χ ≡
2
N action
< Y n > ( x n ) − Y mod el ( x n ,θ )
i
σ n2
∑
σ mean ~
2
~ N data for the “true” model
S .D.exp
N exp ts
parameter refinement: χ2(θ) Å minimize χ2 by changing θ
experimental design: derivatives of χ2 with respect to θ.
Bayesian View
Prior knowledge p(θ, σ) Æ posterior p(θ, σ; Ydata)
More knowledge after experiment. Use to narrow error bars.
Conditional Probability
P( E1 ∩ E 2 ) = P( E1 ) P( E 2 | E1 ) : probability of E2 knowing E1 happened (correlation)
if independent: P(E2)
model
prior
Pposterior(θ,σ|Ydata) = P(Ydata|θ,σ)P(θ,σ)
∫∫dθ dσ P(Y|θ,σ)P(θ,σ) ≈ P(Ydata)
normalize
P(Ydata|θ,σ): probability of observing Ydata we really observed if θ, σ are true values.
We do not know θ and σ exactly.
10.34, Numerical Methods Applied to Chemical Engineering
Prof. William Green
Lecture 22
Page 2 of 2
Cite as: William Green, Jr., course materials for 10.34 Numerical Methods Applied to Chemical Engineering, Fall
2006. MIT OpenCourseWare (http://ocw.mit.edu), Massachusetts Institute of Technology. Downloaded on [DD
Month YYYY].