Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
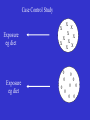
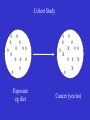
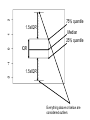
MBP1010 – Jan. 4, 2011 Today’s Topics 1. Introduction 2. Course Information 3. Study Design 4. Looking at Data Introduction to the Practice of Statistics Ch. 1, 2.5, 3.2 Meaning from Data (1) How can we describe and draw meaning from a collection of data? (2) How can we infer information about the whole population when we know data from only some of the population (a sample)? What is statistics? - science of understanding data and making decisions in the face of variability and uncertainty - statistics is NOT a field of mathematics Statistical Thinking -humans are good at recognizing patterns and there is real danger of over-interpreting patterns that are merely due to the play of chance (false leads) - role of statistics - to reject chance as an explanation so that we can have reasonable assurance that patterns seen are worthy of interpretation Statistical Thinking - explore data prior to analysis - think about context and design - reasoning behind standard statistical methods Interpretation/Conclusions Course Overview 1. Study designs/Looking at data 2. Concepts of statistical inference and hypothesis testing 3. Specific statistical tests - 1 and 2 sample test for continuous and categorical data - correlation, regression and ANOVA 4. Other Topics - eg sensitivity/specifiicity, survival analysis, logistic regression 5. Bioinformatics Changes to MBP1010 this year Good news/Bad news! Good news: doing less actual statistical analysis focus more on concepts/interpretation Bad news: short time frame to implement changes Department has made attendance at lectures mandatory. Information Requested What statistical software is available in your lab? What software does you supervisor recommend? What statistical software have you used? Email to: [email protected] by Mon Jan 10 at the latest Course Information Lectures: Tuesdays 1 to 3 pm 620 University, 7-709 Tutorials: Thursdays 2 to 3:30 pm OCI 7-605 First tutorial: Jan 13, 2011 TA: Dave Stock Course Website – U of T Blackboard • UTORiD and password; • U of T email address • Updated course information and schedule posted at website no lecture or tutorial (Jan 25/27) •Updated marking scheme 3 Biostatistics Assignments: Biostatistics Exam : Bioinformatics Assignment Participation 5+15+15=35% 30% 30% 5% Resources Introduction to the Practice of Statistics (5th Edition), by Moore, DS and McCabe, GP). Presenting medical statistics from proposal to publication: A step-by-step guide. by Janet Peacock and Sally Kerry • see website for electronic resources Study Design Can what we eat influence our risk of cancer? The case of dietary fat and breast cancer Posted on website: New York Times article Searching for clarity: A primer on medical studies What should we do next? Observational Studies An observational study observes individuals and measures variables of interest but does not attempt to influence the responses. Observational Studies Case/control and cohort studies common in cancer research (epidemiology) - outcome is binary: cancer/ no cancer Observational studies often examine factors associated with continuous outcome variables - eg association of body weight or diet with hormone levels - calcium intake and blood pressure Case Control Study Exposure eg diet Exposure eg diet X X X X X X X X X X 0 0 0 0 0 0 0 0 0 0 Cohort Study 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Exposure eg diet 0 X 0 0 X 0 0 0 0 0 0 X X Cancer (yes/no) Relative Risk • Compare risk of disease in those with highest versus lowest intake RR = 1.0 no association RR = 1.4 1.4 times the risk 40% higher risk RR = 0.8 20% lower risk a. Total Fat Case Control: Challier (1998) DeStefani (1998) Ewertz (1990) Franceschi (1996) Graham (1982) Graham (1991) Hirohata (1985) Hirohata (1987) (Caucasian) Hirohata (1987) (Japanese) Ingram (1991) Katsouyanni (1988) Katsouyanni (1994) Landa (1994) Lee (1991) Levi (1993) Mannisto (1999) Martin-Moreno (1994) Miller (1978) Núñez (1996) Potischman (1998) Pryor (1989) Richardson (1991) Rohan (1988) Shun-Zhang (1990) Toniolo (1989) Trichopoulou (1995) van't Veer (1990,1991) Wakai (2000) Witte (1997) Yuan (1995) Zaridze (1991) Case Control Summary Cohort: Bingham (2003) Cho (2003) Gaard (1995) Graham (1992) Holmes (1999) Howe (1991) Jones (1987) Knekt (1990) Kushi (1992) Thiébaut (2001) Toniolo (1994) van den Brandt (1993) Velie (2000) Wolk (1998) Cohort Summary All Studies Summary 0 1 2 3 4 5 Odds Ratio or Relative Risk 6 13 14 15 Interpretation Suppose we find that women who eat a low fat diet tend to have lower risk of breast cancer. Can we conclude that the fat in the diet is responsible for the lower risk of breast cancer? Interpretation Suppose we find that women who eat a low fat diet tend to have lower risk of breast cancer. Can we conclude that the fat in the diet is responsible for the lower risk of breast cancer? No. Other factors may be responsible for the association with dietary fat (confounding) Problem of Confounding Suppose A is associated with B: This may be because: • A causes B • B causes A • X is associated with both A and B X need not be a cause of either A or B Problem of Confounding In our dietary fat example: -women who eat more dietary fat may differ from those who less fat (eg. weight, exercise, other dietary factors) -these factors may influence the risk of breast cancer Trying to control for confounding - measure potential confounders eg. measure weight and physical activity -“control” for possible confounders in analysis - but…what about confounding with variables we don’t know exist or can’t measure? Observational Studies An observational study observes individuals and measures variables of interest but does not attempt to influence the responses. Association between variables a response variable, even if it is very strong, is not good evidence of a cause and effect link between variables Correlation is not causation Basic principles of experimental design 1. Formulate question/goal in advance 2. Comparison/control 3. Replication 4. Randomization 5. Stratification (or blocking) Example Question: Does salted drinking water affect blood pressure (BP) in mice? Experiment: 1 Provide treatment - water containing 1% NaCl for 14 days 1. Measure outcome - BP 29 Comparison/control Good experiments are comparative. • Compare BP in mice fed salt water to BP in mice fed plain water. Ideally, the experimental group is compared to concurrent controls (rather than to historical controls). 30 Why replicate? • Reduce the effect of uncontrolled variation (i.e., increase precision). • Quantify uncertainty. A related point: An estimate of effect is of no value without some statement of the uncertainty in the estimate. 31 Randomization Experimental subjects (“units”) should be assigned to treatment groups at random. At random does not mean haphazardly. One needs to explicitly randomize using • A computer, or • Coins, dice or cards. 32 Why randomize? • Avoid bias. – For example: the first six mice you grab may have intrinsically higher BP. • Control the role of chance. – Randomization allows the later use of probability theory, and so gives a solid foundation for statistical analysis. 33 Stratification • Suppose that measurements will be made in males and females AND • You anticipate a difference in response between males and females – Randomize within males and females separately - any systematic difference by sex removed - this is sometimes called “blocking”. -Take account of the difference between males and females in analysis: - helps control variability Randomization and stratification • If you can (and want to), fix a variable. – e.g., study only men or women or a single strain of animal • If you don’t fix a variable, stratify on it. – e.g., randomize treatment men and women • If you can neither fix nor stratify a variable, randomize to treatment. Other points • Blinding – Measurements made by people can be influenced by unconscious biases. – Ideally, measurements should be made without knowledge of the treatment applied. • Internal controls – use the subjects themselves as their own controls (e.g., consider the response after vs. before treatment). – Why? Increased precision. 36 Other points • Representativeness – Are the subjects/tissues you are studying really representative of the population you want to study? – Ideally, your study material is a random sample from the population of interest. 37 Summary Characteristics of good experiments: • comparative - control group • Unbiased – Randomization – Blinding • High precision – Replication – Blocking 38 • Simple – Protect against mistakes • Able to estimate uncertainty – Replication – Randomization Randomized Design Dietary fat and mammary tumors in Sprague-Dawley rats (n=30 per diet group) Diet % energy from fat % developed cancer Time to Cancer (weeks) Low Fat 5 50.0 14.5 1.38 High Fat 26 76.6 11.6 0.96 Jackson et al. Nutr.Cancer, 1998 Factorial Experiment Dietary fat and fiber and mammary tumors in Sprague-Dawley rats (n=30) Diet Low fat - high fiber Low fat - mid fiber Low fat - low fiber Mid fat - high fiber Mid fat - mid fiber Mid fat - low fiber High fat – high fiber High fat – mid fiber High fat – low fiber % developed cancer 56.7 50.0 56.7 80.0 70.0 76.7 60.0 76.6 86.7 Time to Cancer (weeks) 14.2 1.4 14.5 1.4 13.2 1.4 13.9 1.2 12.7 1.2 11.6 0.9 12.4 1.5 11.6 1.0 11.8 0.8 Randomized Clinical Trials in Humans Dietary Fat and Breast Cancer Women’s Health Initiative (US) - 48,835 postmenopausal women - followed for 8-12 years Diet and Breast Cancer Prevention Study - 4793 high risk women - followed for 7-17 years Women’s Health Initiative - Postmenopausal women (50-79 years of age) - n=48,835; follow-up 8-12 years - randomized 40:60 intervention and control - group dietary counselling - follow up for breast cancer Kaplan-Meier Estimates of the Cumulative Hazard for Invasive Breast Cancer Prentice, R. L. et al. JAMA 2006;295:629-642. Copyright restrictions may apply. Eligible Subjects Identified (> 50% density) Prerandomization Assessment Intervention (n=2,343) Control (n=2,350) Annual Visits • demo/anthro data • diet records • non fasting serum Follow up until Dec 2005 (7-17 years per subject) breast cancer incidence Cumulative breast cancer hazards and odds ratios according to randomized group. Martin L J et al. Cancer Res 2011;71:123-133 ©2011 by American Association for Cancer Research Randomized Clinical Trials in Humans Practical Issues: - long (particularly for cancer outcomes!) - expensive - limited in “treatment” options Randomized Clinical Trials in Humans Other issues: - highly selected subjects - selection criteria and motivation - subject/investigator blinding - subjects drop out -compliance? - other changes with intervention? Does salted drinking water affect BP in mice? salt intake? food intake? weight? activity? Main Points - primary interest is causal relationships between variables - observational studies show associations only - randomized studies best for causation but are not without challenges - totality of evidence important What’s in the dataset? What are the observations (individuals)? Eg people, animals, cells, countries How many observations are in the dataset? How many observations should there be? Are the observations independent? - repeated in an individudal? What’s in the dataset? What are the variables? What is their exact definition? How were they measured? What are the units of measurement? What type of variables? Main Types of Variables Categorical: - include nominal and dichotomous variables - qualitative difference between values - eg sex (male/female), smoker/non smoker Continuous: - quantitative - equal distance between each value - eg blood pressure, age, dietary fat Ordinal variables can be ordered but they do not have specific numeric values, eg scales, ratings Continuous Variables Examining a distribution: • overall pattern can be described by shape, centre and spread • in a graph of data look for overall pattern and striking deviations from the pattern • outlier – individual value that falls outside the overall pattern Stem and Leaf Plots - displays distribution of small/moderate amounts of data - includes the actual numerical values Example data: Blood pressure data in 21 patients 107 110 123 129 112 111 107 112 136 102 123 109 112 102 98 114 119 112 110 117 130 Stem (all but last digit) Leaf (last digit) 9:8 10 : 22779 11 : 0012222479 12 : 339 13 : 06 (left)—Serum albumin values in 248 adults FIG 2 (right)—Normal distribution with the same mean and standard deviation as the serum albumin values. Altman D G , Bland J M BMJ 1995;310:298 ©1995 by British Medical Journal Publishing Group Importance of Normal Distribution* 1. Distributions of real data are often close to normal. 2. Mathematically easy to work with so many statistical tests are designed for normal (or close to normal) distributions). 3. If the mean and SD of a normal distribution are known, you can make quantitative predictions about the population. * also called Gaussian curve Describing Distributions with Numbers Blood Pressure Data: n= 21 measurements 98 102 102 107 107 109 110 110 111 112 112 112 112 114 117 119 123 123 129 130 136 mean = 2395/21 = 114 median = observation 11 = 112 Mean versus Median - skewed data 2 8 15 3 29 5 8 1 20 17 6 5 31 44 10 12 23 62 Stem Plot 0: 1: 2: 3: 4: 5: 6: 12355688 0257 039 1 4 2 Mean = 16.7 Median = 11 BP data; n = 10 100 102 104 105 106 112 114 115 116 125 100 Min 104 109 115 Q1 Median Q3 125 Max 75% quantile 1.5xIQR Median 25% quantile IQR 1.5xIQR Everything above or below are considered outliers Dot Plot Measures of Spread - range of data set: largest - smallest value - interquartile range (IQR): 3rd minus 1st quartile - sample variance and standard deviation Deviation from the Mean Choosing a summary Five-number summary -skewed distribution - outliers x and s (mean and std dev.) - reasonably symmetric - free of outliers Extreme Observations or Outliers - rule of thumb 1.5 x IQR for potential outliers - observations that stand apart from the overall pattern (not just extreme values) - do not automatically delete outliers - try to explain them - an error in measurement or in recording data - an usual occurrence - describe outliers, what you do with them and what their effect is Energy expenditure in 29 women measured by doubly labelled water (MJ per day). Stem 18 16 14 12 10 8 6 4 Leaf 9 0258 244579 1122447839 5886689 6 ----+----+----+----+ # 1 Boxplot 0 4 6 10 7 1 | +-----+ *--+--* +-----+ | 1.5 x 3.5(IQR) = 5.25 75th (11.46) + 5.25 = 16.71 19.9 MJ What did we do about the outlier? - checked recording/calculations/data entry - unusual occurrence? - biologically plausible? - re-measured laboratory samples - analysis with and without outlier - described all above in paper Data Display Data presentation Good plot Bad plot 40 35 30 25 20 15 10 5 0 A B Group 78 Dietary fat intake in the intervention and control groups (n=150 intervention and 187 control)Schematic Plots | 45 + | | | | | | 40 + | | | | | | | 35 + 0 | | 0 | | 0 +-----+ | | | 30 + | | | | *--+--* | | | | | | | | 25 + | | | | | +-----+ | | | | +-----+ | 20 + | | | | | | | | *--+--* | | | | | 15 + | | | | +-----+ | | | | 10 + | | | | | | 5 + ------------+-----------+----------GROUP 1 2 % Dietary Fat Group Mean % Dietary Fat (SD) Intervention 17.5 (5.0) Control 28.3 (6.2) Intervention Control How to Display Data Badly H Wainer (1984) How to display data badly. American Statistician 38(2):137-147 - posted at website -use of Microsoft Excel and Powerpoint has resulted in remarkable advances in the field (of poor data display) General principles The aim of good data graphics: Display data accurately and clearly. Some rules for displaying data badly: – Display as little information as possible. – Obscure what you do show (with chart junk). – Use pseudo-3d and color gratuitously. – Make a pie chart (preferably in color and 3d). – Use a poorly chosen scale. Pay attention to scale! Same data, different scale Displaying data well • Be accurate and clear. • Let the data speak. – Show as much information as possible, taking care not to obscure the message. • Science not sales. – Avoid unnecessary frills — esp. gratuitous 3d. • In tables, every digit should be meaningful. Further reading – Data Display • ER Tufte http://www.edwardtufte.com/tufte/ (1983) The visual display of quantitative Information. (1990) Envisioning information. (1997) Visual explanations. •WS Cleveland (1993) Visualizing data. Hobart Press. • WS Cleveland (1994) The elements of graphing data. CRC Press. Information Requested What statistical software is available in your lab? What software does you supervisor recommend? What statistical software have you used? Email to: [email protected] by Mon Jan 10 at the latest