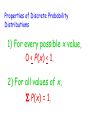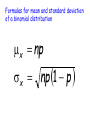Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
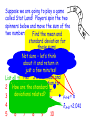
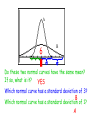
Chapter 7 Random Variables and Probability Distributions Random Variable A grocery store manager might be • A numerical variable whose value interested in the number of broken depends on the outcome of a chance eggs in each carton (dozen of eggs). experiment OR • Associates a numerical value with An environmental scientist might be each interestedofin athe amount of ozone in an outcome chance experiment air sample. • Two types of random variables – Discrete Since these values change and are – Continuous subject to some uncertainty, these are examples of random variables. Two Types of Random Variables: • Discrete – its set of possible values is awe In this chapter, will look collection of isolated points along a at different number line This is typically a “count” of something distributions of discrete and continuous random variables. • Continuous - its set of possible values This is typically a includes an entire interval on of a number “measure” something line Identify the following variables as discrete or continuous 1. The number of broken eggs in each carton Discrete 2. The amount of ozone in samples of air Continuous 3. The weight of a pineapple Continuous 4. The amount of time a customer spends in a store Continuous 5. The number of gas pumps in use Discrete Probability Distributions for Discrete Random Variables Probability distribution is a model that describes the longrun behavior of a variable. In a Wolf City (a fictional place), regulations prohibit This no more than afive dogs or cats per is called discrete probability household. distribution. It can also be displayed in a number histogram with and the probability Let x = the of dogs cats in a on What do you notice about the sum of the vertical axis. randomly selected household in Wolf City these probabilities? Is What this variable discrete or continuous? are the possible values for x 0 1 2 3 4 5 x? Probability P(x) .26 .31 .21 .13 .06 .03 The Department of Animal Control has collected data over the course of several years. They have estimated the long-run probabilities for the values of x. Number of Pets Discrete Probability Distribution 1) Gives the probabilities associated with each possible x value 2) Each probability is the long-run relative frequency of occurrence of the corresponding x-value when the chance experiment is performed a very large number of times 3) Usually displayed in a table, but can be displayed with a histogram or formula Properties of Discrete Probability Distributions 1) For every possible x value, 0 < P(x) < 1. 2) For all values of x, S P(x) = 1. Dogs and Cats Revisited . . . Let x =Just the add number dogs or cats the of probabilities forper 0, household 1, and 2 in Wolf City x 0 P(x) .26 1 2 3 4 5 .31 .21 .13 .06 .03 What does this mean? What is the probability that a randomly selected household in Wolf City has at most 2 pets? P(x < 2) = .26 + .31 + .21 = .78 Dogs and Cats Revisited . . . Notice that this probability Let x = the number of dogs2! or cats per household does NOT include in Wolf City x 0 P(x) .26 1 2 3 4 5 .31 .21 .13 .06 .03 What does this mean? What is the probability that a randomly selected household in Wolf City has less than 2 pets? P(x < 2) = .26 + .31 = .57 Dogs and Cats Revisited . . . Let x = the number of dogs or cats per household in Wolf City When calculating probabilities x 0 1 2 3 4for discrete 5 random variables, you MUST pay close P(x) .26 to.31 .21 certain .13 .06 .03are attention whether values included (< or >) orWhat not included (< or >) in the does this mean? calculation. What is the probability that a randomly selected household in Wolf City has more than 1 but no more than 4 pets? P(1 < x < 4) = .21 + .13 + .06 = .40 Probability Distributions for Continuous Random Variables Consider the random variable: x = the weight (in pounds) of a full-term newborn child Suppose that weight is reported to the nearest pound. The following probability histogram What type of variable is this? If weight is measured with greater What is the sum of the areas of all displays the distribution of weights. The area of the rectangle and greater accuracy, thecentered histogram the rectangles? Notice that the rectangles are The shaded area represents the over 7 pounds represents the This is an example approaches ahistogram smooth curve. Nownarrower suppose that and the weight is reported begins to to the probability 6 < x < 8. probability 6.5 appearance. < xof < 7.5 a density curve. have a smoother nearest 0.1 pound. This would be the probability histogram. Probability Distributions for Continuous Variables • Is specified by a curve called a density curve. • The function that describes this curve is denoted by f(x) and is called the density function. • The probability of observing a value in a particular interval is the area under the curve and above the given interval. Properties of continuous probability distributions 1. f(x) > 0 (the curve cannot dip below the horizontal axis) 2. The total area under the density curve equals one. Let x denote the amount of gravel sold (in tons) during a randomly selected week at a particular sales facility. Suppose that the density curve has a height f(x) above the value x, where 2(1 x ) 0 x 1 f (x ) otherwise 0 The density curve is shown in the figure: Density 2 1 Tons 1 Gravel problem continued . . . What is the probability that at most ½ ton of gravel is sold during a randomly selected week? P(x < ½) = Density 2 1 1 – ½(0.5)(1) = .75 This area can be found by use the OR,The more easily, by finding the probability would be the formula for the area of a area of the triangle, shaded area under the curve and trapezoid: 1 above the interval from 0 to 0.5. A 1 bh A 2b1 b2 h 2 that area from 1. and subtracting Tons 1 Gravel problem continued . . . What is the probability that exactly ½ ton of gravel is sold during a randomly selected week? P(x = ½) = 2 0 How do we find the area of a line The probability would be the area Since a line segment has NO area, Density segment? the curve that and above 0.5. thenunder the probability exactly ½ ton is sold equals 0. 1 Tons 1 Gravel problem continued . . . What is the probability that less than ½ ton of gravel is sold during a randomly selected week? P(x < ½) = P(x < ½) Density 2 1 = 1 – ½(0.5)(1) = .75 Does theHmmm probability change . . . This is whether different the ½ is included or not? than discrete probability distributions where it does change the probability whether a value is included or Tons not! 1 Suppose x is a continuous random variable defined as the amount of time (in minutes) taken by a clerk to process a certain type of application form. Suppose x has a probability distribution with density function: .5 4 x 6 f (x ) 0 otherwise The following is the graph of f(x), the density curve: Density 0.5 4 5 6 Time (in minutes) Application Problem Continued . . . What is the probability that it takes more than 5.5 minutes to process the application form? P(x > 5.5) = .5(.5) = .25 When the density is constant over an interval the probability by curve), calculating (resultingFind in a horizontal density the area of the shaded region probabilitythe distribution is called a uniform (base × height). distribution. Density 0.5 4 5 6 Time (in minutes) Other Density Curves Some density curves resemble the one below. Integral calculus is used to find the area under the these curves. Don’t worry – we will use tables (with the values already calculated). We can also use calculators or statistical software to find the area. The probability that a continuous random variable x lies between a lower limit a and an upper limit b is This will be to useful laterofinb) – P(a < x < b) = (cumulative area the left thisarea chapter! (cumulative to the left of a) P(a < x < b) = P(x < b) – P(x < a) Means and Standard Deviations of Probability Distributions • The mean value of a random variable x, denoted by mx, describes where the probability distribution of x is centered. • The standard deviation of a random variable x, denoted by sx, describes variability in the probability distribution Mean and Variance for Discrete Probability Distributions • Mean is sometimes referred to as the expected value (denoted E(x)). μx xp • Variance is calculated using s x m x p 2 2 • Standard deviation is the square root of the variance. Dogs and Cats Revisited . . . Let x = the number of dogs and cats in a randomly selected household in Wolf City x 0 1 2 3 4 5 P(x) .26 .31 .21 .13 .06 .03 xP(x) 0 + .31 .31 + .42 + .39 + .24 .24 + .15 What is the mean number of pets per household in Wolf City? First multiply x-value Next find the each sum of thesetimes values. its corresponding probability. mx = 1.51 pets Dogs and Cats Revisited . . . Let x = the number of dogs or cats per household in Wolf City x 0 P(x) .26 1 2 3 4 5 .31 .21 .13 .06 .03 What is the standard deviation of the number of pets per household in Wolf City?– take the This is the variance First find the of each xNext multiply bydeviation the corresponding square root of this value. 2 2 fromThen the mean. Then2values. square probability. add these sxvalue = (0-1.51) (.26) + (1-1.51) (.31) + 2(.21)deviations. these (2-1.51) + (3-1.51)2(.13) + (4-1.51)2(.06) + (5-1.51)2(.03) = 1.7499 sx = 1.323 pets Mean and Variance for Continuous Random Variables For continuous probability distributions, mx and sx can be defined and computed using methods from calculus. • The mean value mx locates the center of the continuous distribution. • The standard deviation, sx, measures the extent to which the continuous distribution spreads out around mx. A company receives concrete of a certain type from two different suppliers. Let x = compression strength of a randomly selected Thebatch firstfrom supplier is preferred to Supplier 1 second strength both in terms of mean y = the compression of a randomly selected batch fromand Supplier 2 value variability. Suppose that mx = 4650 pounds/inch2 sx = 200 pounds/inch2 my = 4500 pounds/inch2 sy = 275 pounds/inch2 4300 4500 4700 my mx 4900 would happenhad to the mean and Suppose What Wolf City Grocery a total standard deviation if weare hadthe to deduct of 14 employees. The following $100 from everyone’s salary because monthly salaries of all the employees. of business being bad? 3500 1300 1200 1500 1900 1700 1400 2300 2100 1200 1800 1400 1200 1300 The and standard of thesalaries Let’smean graph boxplots of deviation these monthly monthly salaries are to the distributions . . . to see what happens mx = $1700 and sx = $603.56 What We see that the distribution What happened just shifts to theisright happene Suppose business really100 good, so the manager to new the but the spread the per month. The dunits to the gives everyone a $100israise standard same. means? mean and standard deviation would be deviations? mx = $1800 and sx = $603.56 Wolf City Grocery Continued . . . mx = $1700 and sx = $603.56 Suppose the manager gives everyone a 20% raise - the new mean and standard deviation would be m = $2040 and sx = $724.27 x Let’s graph boxplots of these monthly salaries to see what happens to the distributions . . . NoticeNotice that multiplying that bothbythe mean and standard a constant stretches the deviation increased by 1.2. distribution, thus, changing the standard deviation. Mean and Standard Deviation of Linear functions If x is a random variable with mean, mx, and standard deviation, sx, and a and b are numerical constants, and the random variable y is defined by y a bx and m y m a bx a bm x 2 sy 2 sa bx 2 2 b sx or s y b s x Consider the chance experiment in which a customer of a propane gas company is randomly selected. Let x be the number of gallons required to fill a propane tank. Suppose that the mean and standard deviation is 318 gallons and 42 gallons, respectively. The company is considering the pricing model of a service charge of $50 plus $1.80 per gallon. Let y be the random variable of the amount billed. What is the equation for y? y = 50 + 1.8x What are the mean and standard deviation for the amount billed? my = 50 + 1.8(318) = $622.40 sy = 1.8(42) = $75.60 Suppose we are going to play a game called Stat Land! Players spin the two spinners below and move the sum of the two numbers. Find the mean and 2 1 2 1 3 standard deviation for 4 3 6 4 5 these sums. Spinner B Spinner A Not sure – let’s think mA = 2.5 mB = 3.5 about it and return in sjust sB = 1.708 a few minutes! A = 1.118 are sums the mean and List all the Here possible (A + B). standard deviation for Notice that the mean 2 How 3 are 4 theeach 5standard 6 7 spinner. of the sums is the deviations related? mA+B = 6 3 4 5 6 7 8 sum of the means! 4 5 5 6 6 7 7 8 8 9 9 10 ? Move 1s sA+B =2.041 Stat Land Continued . . . Suppose one variation of the game had players move the difference of the spinners 2 1 2 4 3 1 6 ? Move 1s 3 4 5 Find the and weB mean find the Spinner Spinner A How do standard deviation standard for for the mA = 2.5 mBdeviation = 3.5 these differences. sums or differences? sA = 1.118 sB = 1.708 List all the possible differences (B - A). 0 1 2 3 4 5 -1 -2 -3 Notice that the mean 0WOW -1 -2 – this is the of1 the differences is 0 -1 same value asofthe the difference the 2 1 0 standard deviation of means! 3 2 sums! 1 the 4 3 2 mB-A= 1 sB-A =2.041 Mean and Standard Deviations for Linear Combinations If x1, x2, …, xn are random variables with means m1, m2, …, mn and variances s12, s22, …, sn2, respectively, and is true ONLY if the x’s This result y = aare + a2x2 + … + anxn 1x1 independent. then This result is true regardless of whether my a1the mx x’s are a2mindependent. ... a m x n xn 2 1 s y a12s x21 a22s x22 ... an2s x2n A commuter airline flies small planes between San Luis Obispo and San Francisco. For small planes the baggage weight is a concern. Suppose it is known that the variable x = weight (in pounds) of baggage checked by a randomly selected passenger has a mean and standard deviation of 42 and 16, respectively. Consider a flight on which 10 passengers, all traveling alone, are flying. The total weight of checked baggage, y, is y = x1 + x2 + … + x10 Airline Problem Continued . . . mx = 42 and sx = 16 The total weight of checked baggage, y, is y = x1 + x2 + … + x10 What is the mean total weight of the checked baggage? mx = m1 + m2 + … + m10 = 42 + 42 + … + 42 = 420 pounds Airline Problem Continued . . . 42 and sx =are 16 all traveling Since them10 x =passengers alone, it is reasonable to think that the 10 The total weight of checked baggage, y, is baggage weights are unrelated and therefore y = x1 + x2independent. + … + x10 What isTo the standard deviation of the total find the standard deviation, take weight of the baggage? thechecked square root of this value. sx2 = sx12 + sx22 + … + sx102 = 162 + 162 + … + 162 = 2560 pounds s = 50.596 pounds Special Distributions Two Discrete Distributions: Binomial and Geometric One Continuous Distribution: Normal Distributions Suppose we decide to record the gender of the next 25 newborns at a particular hospital. These questions can be answered using a binomial distribution. Properties of a Binomial Experiment 1. There are a fixed number of trials 2. Each trial results in one of two mutually We use n to denote the fixed exclusive outcomes. (success/failure) number of trials. 3. Outcomes of different trials are independent 4. The probability that a trial results in success is the same for all trials The binomial random variable x is defined as x = the number of successes observed when a binomial experiment is performed Are these binomial distributions? 1) Toss a coin 10 times and count the number of heads Yes 2) Deal 10 cards from a shuffled deck and count the number of red cards No, probability does not remain constant 3) The number of tickets sold to children under 12 at a movie theater in a one hour period No, no fixed number Binomial Probability Formula: Let n = number of independent trials in a binomial experiment p = constant probability that any trial results in a success Where: n! x n x P (x ) p (1 p ) x ! (n x )! n 9 can be used n ! Appendix Table to find Technology, as calculators and n C xsuch binomial probabilities. x statistical software, x ! (n x )!will also perform this calculation. Instead of recording the gender of the next 25 newborns at a particular hospital, let’s record the gender of the next 5 newborns at this hospital. is the probability of Is this a What binomial experiment? “success”? Yes, if the births were not multiple births (twins, etc). Define the random variable of interest. What will the largest value of the Will a binomial random variable x = the number of females born out of the next binomial random value be? always include the value of 0? 5 births What are the possible values of x? x 0 1 2 3 4 5 Newborns Continued . . . What is the probability that exactly 2 girls will be born out of the next 5 births? P (x 2) 5 C 2 0.5 0.5 .3125 2 3 What is the probability that less than 2 girls will be born out of the next 5 births? P (x 2) p (0) p (1) 5 C 0 .5 .5 5 C 1 .5 .5 0 .1875 5 1 4 Newborns Continued . . . Let’s construct the discrete probability distribution table for this binomial random variable: x 0 1 2 3 p(x) .03125 .15625 .3125 .3125 4 5 .15625 .03125 is the multiplying WhatNotice is the that meanthis number ofsame girls as born in the next five births? n×p Since this is a +discrete mx = 0(.03125) + 1(.15625) 2(.3125) + distribution, could use: 3(.3125) + 4(.15625)we + 5(.03125) =2.5 mx xp Formulas for mean and standard deviation of a binomial distribution mx np sx np 1 p Newborns Continued . . . How many girls would you expect in the next five births at a particular hospital? mx np 5(.5) 2.5 What is the standard deviation of the number of girls born in the next five births? sx np (1 p ) 5(.5)(.5) 1.118 Remember, in binomial distributions, trials should be independent. However, when we sample, we typically sample without replacement, which replacement would mean that When sampling without if n the trials not5% independent. . binomial is atare most of N, then. the distribution gives a good In this case, the number of success observed to the probability would notapproximation be a binomial distribution but rather distribution of x. hypergeometric distribution. But when sample size, n, is small and The the calculation for probabilities in the a population size, N, is large, probabilities hypergeometric distribution are even calculatedmore usingtedious binomial distributions and than the binomial formula! are VERY close! hypergeometric distributions Newborns Revisited . . . Suppose we were not interested in the number of females born out of the next five births, but which birth would result in the first female being born? How is this question different from a binomial distribution? Properties of Geometric Distributions: • There are two mutually exclusive outcomes that result in a success or failure So what are the • Each trial is independent of the others possible values of x • The probability of success is the same for all trials. To infinity How far will this go? A geometric random variable x is defined as x = the number of trials UNTIL the FIRST success is observed ( including the success). x 1 2 3 4 . . . Probability Formula for the Geometric Distribution Let p = constant probability that any trial results in a success x 1 p (x ) (1 p ) Where x = 1, 2, 3, … p Suppose that 40% of students who drive to campus at your school or university carry jumper cables. Your car has a dead battery and you don’t have jumper cables, so you decide to stop students as they are headed to the parking lot and ask them whether they have a pair of jumper cables. Let x = the number of students stopped before finding one with a pair of jumper cables Is this a geometric distribution? Yes Jumper Cables Continued . . . Let x = the number of students stopped before finding one with a pair of jumper cables p = .4 What is the probability that third student stopped will be the first student to have jumper cables? P(x = 3) = (.6)2(.4) = .144 What is the probability that at most three student are stopped before finding one with jumper cables? P(x < 3) = P(1) + P(2) + P(3) = (.6)0(.4) + (.6)1(.4) + (.6)2(.4) = .784 Normal Distributions • Continuous probability distribution is this To overcome the need for How calculus, wedone rely on • Symmetrical bell-shaped (unimodal) density mathematically? technology or on a table of areas for the curve defined by m and s standard normal distribution • Area under the curve equals 1 • Probability of observing a value in a particular interval is calculated by finding the area under the curve • As s increases, the curve flattens & spreads out • As s decreases, the curve gets taller and thinner A 6 B s s Do these two normal curves have the same mean? If so, what is it? YES Which normal curve has a standard deviation of 3? B Which normal curve has a standard deviation of 1? A Notice that the normal curve is curving downwards from the center (mean) to points that are one standard deviation on either side of the mean. At those points, the normal curve begins to turn upward. Standard Normal Distribution • Is a normal distribution with m = 0 and s = 1 • It is customary to use the letter z to represent a variable whose distribution is described by the standard normal curve (or z curve). Using the Table of Standard Normal (z) Curve Areas • For any number z*, from -3.89 to 3.89 and use theplaces, table: the Appendix rounded to twoTodecimal Table 2 gives the area under the z curve and to•the left ofcorrect z*. Find the row and column (see the following P(z < example) z*) = P(z < z*) • The number at the intersection of Where that row and column is the probability the letter z is used to represent a random variable whose distribution is the standard normal distribution. Suppose we are interested in the probability that z* is less than -1.62. In the table of areas: P(z < -1.62) = .0526 •Find the row labeled -1.6 •Find the column labeled 0.02 -1.7 -1.6 -1.5 .0446 .0548 .0668 .0436 .0537 .0655 .0427 .0526 .0643 … … … … … •Find the intersection of the row and column … z* .00 .01 .02 .0418 .0516 .0618 Suppose we are interested in the probability that z* is less than 2.31. P(z < 2.31) = .9896 2.2 2.3 2.4 .9861 .9893 .9918 .9864 .9896 .9920 .9868 .9898 .9922 … … .02 … .01 … .00 … … z* .9871 .9901 .9925 Suppose we are interested in the probability that z* is greater than 2.31. 2.2 2.3 2.4 .9861 .9893 .9918 .9864 .9896 .9920 .9868 .9898 .9922 … … … … … The Table of Areas gives the area to the P(z > 2.31) = LEFT of the z*. 1 - .9896 = .0104 To find the area to the right, subtract the value in the table from 1 … z* .00 .01 .02 .9871 .9901 .9925 Suppose we are interested in the finding the z* for the smallest 2%.To find z*: Look for the area .0200 in the body of P(z < z*) .02 the= Table. Follow the row and column Since .0200out doesn’t appear in the body back to read the z-value. z* = -2.08 of the Table, use the z* value closest to it. -2.1 -2.0 -1.9 .0162 .0207 .0262 .0158 .0202 .0256 … … .08 … … … … .07 … .06 … … z* .0154 .0197 .0250 Suppose we are interested in the finding the z* for the largest 5%. Since .9500 is exactly between .9495 .95 P(z > z*)and = .05 .9505, we can average the z* for each of these z* = 1.645 z* … … … … … Remember the Table of Areas gives the area to the LEFT of z*. … z* .03 .04 .05 1 – (area to the right of z*) … 1.5 Then look up this.9382 value in .9398 the body.9406 of … the.9495 1.6 .9515 table. .9505 … 1.7 .9591 .9599 .9608 Finding Probabilities for Other Normal Curves • To find the probabilities for other normal curves, standardize the relevant values and then use the table of z areas. • If x is a random variable whose behavior is described by a normal distribution with mean m and standard deviation s , then P(x < b) = P(z < b*) P(x > a) = P(z > a*) P(a < x < b) = P(a* < z < b*) Where z is a variable whose distribution is standard normal and a* a m s b* b m s Data on the length of time to complete registration for classes using an on-line registration system suggest that the distribution of the variable x = time to register for students at a particular university can well be approximated by a normal distribution with mean m = 12 minutes and standard deviation s = 2 minutes. Registration Problem Continued . . . x = time to register Standardized this value. m = 12 minutes and s = 2 minutes What is the probability that willvalue take up a in Lookitthis randomly selected student less than 9 minutes to the table. complete registration? P(x < 9) = .0668 9 12 b* 1.5 2 9 Registration Problem Continued . . . x = time to register Standardized this value. m = 12 minutes and s = 2 minutes What is the probability that willvalue take up a in Lookitthis randomly selected student more than 13 the table andminutes to complete registration? subtract from 1. P(x > 13) = 1 - .6915 = .3085 13 12 a* .5 2 13 Registration Problem Continued . . . x = time to register Standardized these values. m = 12 minutes and s = 2 minutes these values in take the table and What is the Look probability that itup will a randomly selected studentsubtract between 7 and 15 (value for a*) – (value for b*) minutes to complete registration? P(7 < x < 15) = .9332 - .0062 = .9270 15 12 a* 1.5 2 7 12 b* 2.5 2 7 15 Registration Problem Continued . . . x = time to register m = 12 minutes and s = 2 minutes Look up thedoarea to off theproperly, the Because some students not log Use the formula for university would to in logthe off students automatically left like of a* table. standardizing to find x. after some time has elapsed. It is decided to select this time so that only 1% of students will be automatically logged off while still trying to register. What time should the automatic log off be set at? P(x > a*) = .01 a* = 16.66 .99 x 12 2.33 2 .01 a* Ways to Assess Normality What should Some of theifmost happen our frequently used statistical methods are valid only when x , x , …, x has come 1 2 n data set is from a population distribution that at least is normally approximately normal. One way to see whether an distributed? assumption of population normality is plausible is to construct a normal probability plot of the data. A normal probability plot is a scatterplot of (normal score, observed values) pairs. Consider a random sample with n = 5. To find the appropriate normal scores for a Each region has sample ofthese size 5, divide the standard Why are an area equal to normal into 5 equal-area regions. regionscurve not the same width? 0.2. Consider a are random samplescores with that n = 5. These the normal we Next – find the median z-score for each region. would plot our data against. Why is the We use technology (calculators or median not in statistical software) to compute these the “middle” of normal scores. each region? -1.28 -.524 0 1.28 .524 Ways to Assess Normality Some of the most Such frequently used statistical as curvature which would methods Or areoutliers valid only whenskewness x1, x2, …,inxnthe hasdata come indicate from a population distribution that at least is approximately normal. One way to see whether an assumption of population normality is plausible is to construct a normal probability plot of the data. A normal probability plot is a scatterplot of (normal score, observed values) pairs. A strong linear pattern in a normal probability plot suggest that population normality is plausible. On the other hand, systematic departure from a straight-line pattern indicates that it is not reasonable to assume that the population distribution is normal. Sketch a scatterplot byprobability pairing theis plot. The Let’s following construct data a normal represent eggplot weights (in Since the normal probability smallest normal score the grams) Since approximately for the avalues sample ofof the 10 normal eggs. scores linear, it with is plausible smallest observation from data set depend the sample size n,the the normal thaton the distribution of egg weights is & so on approximately normal. scores when n = 10 are below: 53.04 53.50 52.53 53.00 53.07 53.5 52.86 52.66 53.23 53.26 53.16 53.0 -1.539 -1.001 -0.656 -0.376 -0.123 0.123 0.376 0.656 1.001 1.539 52.5 -1.5 -1.0 -0.5 0.5 1.0 1.5 Using the Correlation Coefficient to Assess Normality •The correlation coefficient, r, can be calculated for the n (normal score, observed value) pairs. •If r is too much smaller than 1, then normality of the Since underlying distribution is questionable. r > to critical Values to Which r Can be Compared Check r, for Normality How smaller iseggs “too then it is plausible that the60 sample Consider from the weight data: n 5 these 10 points 15 20 25 30 40 of 50 75 of much egg weights came from a smaller than 1”? (-1.539, 52.53) (-1.001, 52.66) (-.656,52.86) (-.376,53.00) Critical (-.123, 53.04) .832 .880 (.123,53.07) 911distribution .929 .941 (.376,53.16) .949 .960 .966(.656,53.23) .971 .976 that was approximately r (1.001,53.26) (1.539,53.50) normal. Calculate the correlation coefficient for these points. r = .986 Transforming Data to Achieve Normality • When the data is not normal, it is common to use a transformation of the data. • For data that shows strong positive skewness (long upper tail), a logarithmic transformation usually applied. • Square root, cube root, and other transformations can also be applied to the data to determine which transformation best normalizes the data. Consider the data set in Table 7.4 (page 463) about plasma and urinary AGT levels. A histogram of the urinary AGT levels is strongly positively skewed. A logarithmic transformation is applied to the data. The histogram of the log urinary AGT levels is more symmetrical. Using the Normal Distribution to Suppose thisabar is centered at x = 6. Approximate Discrete Distribution The bar actually begins at 5.5 and ends at 6.5. endpoints will be used Suppose theTheses probability distribution of a in Often, a probability histogram can be well calculations. discrete random variable x is displayed in the approximated by a normal curve. If so, it histogram below. is customary to sayofthat x has an The probability a particular This is called a continuity correction. approximately normal distribution. value is the area of the rectangle centered at that value. 6 Normal Approximation to a Binomial Distribution Let x be a random variable based on n trials and success probability p, so that: m np s np (1 p ) If n and p are such that: np > 10 and n (1 – p) > 10 then x has an approximately normal distribution. Premature babies are born before 37 weeks, and those born before 34 weeks are most at risk. A study reported that 2% of births in the United States occur before 34 weeks. Suppose that 1000 births are randomly selected and that the number of these births that occurred prior to 34 weeks, x, is to be determined. Since both are greater than 10, the np = 1000(.02) = 20 > 10 distribution of x can Can the distribution of x be be by by approximated a normal n(1 – p) = 1000(.98)approximated = 980 > 10 distribution?a normal distribution Find the mean and standard deviation for the approximated normal distribution. m np 1000(.02) 20 s np (1 p ) 1000(.02)(.98) 4.427 Premature Babies Continued . . . m = 20 and s = 4.427 What is the probability that the number of Look up these babies in the sample ofin1000 values the born tableprior to 34 weeks will be between 10 and 25 and subtract the(inclusive)? To find the shaded probabilities. standardize = .8836 P(10 < x < 25) = .8925 - .0089 area, the endpoints. a* 9.5 20 2.37 4.427 b* 25.5 20 1.24 4.427