Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
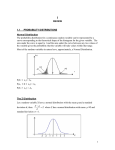
z Tests and Confidence Intervals for a Difference Between Two Population Means Basic Assumptions 1. X1, X2,….Xm is a random sample from a distribution with mean 1 and variance . 2. Y1, Y2,…..Yn is a random sample from a distribution with mean 2 and variance . 3. The X and Y samples are independent of one another. 1 z Tests and Confidence Intervals for a Difference Between Two Population Means The use of m for the number of observations in the first sample and n for the number of observations in the second sample allows for the two sample sizes to be different. Sometimes this is because it is more difficult or expensive to sample one population than another. In other situations, equal sample sizes may initially be specified, but for reasons beyond the scope of the experiment, the actual sample sizes may differ. 2 z Tests and Confidence Intervals for a Difference Between Two Population Means Proposition The expected value of is 1 – 2, so is an unbiased estimator of 1 – 2. The standard deviation of is 3 Test Procedures for Normal Populations with Known Variances Standardizing gives the standard normal variable (9.1) In a hypothesis-testing problem, the null hypothesis will state that 1 – 2 has a specified value. 4 Test Procedures for Normal Populations with Known Variances Rejection regions for Ha: 1 – 2 < 0 and Ha: 1 – 2 ≠ 0 that yield tests with desired significance level are lowertailed and two-tailed, respectively. Null hypothesis:H0 : 1 – 2 = 0 Test statistic value: z = 5 Test Procedures for Normal Populations with Known Variances Alternative Hypothesis Rejection Region for Level Test Ha: 1 – 2 > 0 z z (upper-tailed) Ha: 1 – 2 < 0 z – z (lower-tailed) Ha: 1 – 2 ≠ 0 either z z/2 or z – z/2(twotailed) Because these are z tests, a P-value is computed as it was for the z tests [e.g., P-value = 1 – (z) for an upper-tailed test]. 6 Large-Sample Tests The assumptions of normal population distributions and known values of 1 and 2 are fortunately unnecessary when both sample sizes are sufficiently large. In this case, the Central Limit Theorem guarantees that has approximately a normal distribution regardless of the underlying population distributions. Furthermore, using and in place of and in Expression (9.1) gives a variable whose distribution is approximately standard normal: 7 Large-Sample Tests Use of the test statistic value along with the previously stated upper-, lower-, and twotailed rejection regions based on z critical values gives large-sample tests whose significance levels are approximately . These tests are usually appropriate if both m > 40 and n > 40. A P-value is computed exactly as it was for our earlier z tests. 8 Confidence Intervals for 1 – 2 Manipulation of the inequalities inside the parentheses to isolate 1 – 2 yields the equivalent probability statement This implies that a 100(1 – )% CI for 1 – 2 has lower limit upper limit where is the square-root expression. This interval is a special case of the general formula 9 Confidence Intervals for 1 – 2 Provided that m and n are both large, a CI for 1 – 2 with a confidence level of approximately 100(1 – )% is where – gives the lower limit and the upper limit of the interval. An upper or a lower confidence bound can also be calculated by retaining the appropriate sign (+ or –) and replacing z/2 by z. Our standard rule of thumb for characterizing sample sizes as large is m > 40 and n > 40. 10 The Two-Sample t Test and Confidence Interval We could, for example, assume that both population distributions are members of the Weibull family or that they are both Poisson distributions. It shouldn’t surprise you to learn that normality is typically the most reasonable assumption. Assumptions Both population distributions are normal, so that X1, X2,…, Xm is a random sample from a normal distribution and so is Y1,…,Yn (with the X’s and Y’s independent of one another). 11 The Two-Sample t Test and Confidence Interval Theorem When the population distribution are both normal, the standardized variable (9.2) has approximately a t distribution with df v estimated from the data by 12 The Two-Sample t Test and Confidence Interval where (round v down to the nearest integer). Manipulating T in a probability statement to isolate 1 – 2 gives a CI, whereas a test statistic results from replacing 1 – 2 by the null value 0. 13 The Two-Sample t Test and Confidence Interval The two-sample t confidence interval for 1 – 2 with confidence level 100(1 – ) % is then A one-sided confidence bound can be calculated as described earlier. The two-sample t test for testing H0: 1 – 2 = 0 is as follows: Test statistic value: t = 14 The Two-Sample t Test and Confidence Interval Alternative Hypothesis Rejection Region for Approximate Level Test Ha: 1 – 2 > 0 t t,v (upper-tailed) Ha: 1 – 2 < 0 t – t,v (lower-tailed) Ha: 1 – 2 0 either t t/2,v or t –t/2,v (two-tailed) 15 Pooled t Procedures Alternatives to the two-sample t procedures just described result from assuming not only that the two population distributions are normal but also that they have equal variances . That is, the two population distribution curves are assumed normal with equal spreads, the only possible difference between them being where they are centered. 16 Pooled t Procedures The following weighted average of the two sample variances, called the pooled (i.e., combined) estimator of 2,adjusts for any difference between the two sample sizes: The first sample contributes m – 1 degrees of freedom to the estimate of 2, and the second sample contributes n – 1 df, for a total of m + n – 2 df. 17 Pooled t Procedures Statistical theory says that if replaces 2 in the expression for Z, the resulting standardized variable has a t distribution based on m + n – 2 df. In the same way that earlier standardized variables were used as a basis for deriving confidence intervals and test procedures, this t variable immediately leads to the pooled t CI for estimating 1 – 2 and the pooled t test for testing hypotheses about a difference between means. 18 Analysis of Paired Data Assumptions The data consists of n independently selected pairs (X1,Y1), (X2, Y2),…(Xn, Yn), with E(Xi) = 1 and E(Yi) = 2. Let D1 = X1 – Y1, D2 = X2 – Y2,…, Dn = Xn – Yn so the Di’s are the differences within pairs. Then the Di’s are assumed to be normally distributed with mean value D and variance (this is usually a consequence of the Xi’s and Yi’s themselves being normally distributed). 19 The Paired t Test Because different pairs are independent, the Di’s are independent of one another. Let D = X – Y, where X and Y are the first and second observations, respectively, within an arbitrary pair. Then the expected difference is D = E(X – Y) = E(X) – E(Y) = 1 – 2 (the rule of expected values used here is valid even when X and Y are dependent). Thus any hypothesis about 1 – 2 can be phrased as a hypothesis about the mean difference D. 20 The Paired t Test But since the Di’s constitute a normal random sample (of differences) with mean D, hypotheses about D can be tested using a one-sample t test. That is, to test hypotheses about 1 – 2 when data is paired, form the differences D1, D2,…, Dn and carry out a one-sample t test (based on n – 1 df) on these differences. 21 The Paired t Test The Paired t Test Null hypothesis: H0: D = 0 (where D = X – Y is the difference between the first and second observations within a pair, and D = 1 – 2) Test statistic value: (where and sD are the sample mean and standard deviation, respectively, of the di’s) 22 The Paired t Test Alternative Hypothesis Ha: D > 0 Rejection Region for Level Test t t,n –1 Ha: D < 0 t – t,n – 1 Ha: D ≠ 0 either t t/2,n–1 or t – t/2,n–1 A P-value can be calculated as was done for earlier t tests. 23 The Paired t Confidence Interval In the same way that the t CI for a single population mean is based on the t variable T = at confidence interval for D (= 1 – 2) is based on the fact that has a t distribution with n – 1 df. Manipulation of this t variable, as in previous derivations of CIs, yields the following 100(1 – )% CI: The paired t CI for D is 24 Inferences Concerning a Difference Between Population Proportions Proposition Let and where X ~ Bin(m, p1) and Y ~ Bin(n, p2 ) with X and Y independent variables. Then So is an unbiased estimator of p1 – p2, and (where qi = 1 – pi) (9.3) 25 A Large-Sample Test Procedure The most general null hypothesis an investigator might consider would be of the form H0: p1 – p2 = Although for population means the case no difficulties, for population proportions must be considered separately. 0 presented = 0 and 0 Since the vast majority of actual problems of this sort involve = 0 (i.e., the null hypothesis p1 = p2). we’ll concentrate on this case. When H0: p1 – p2 = 0 is true, let p denote the common value of p1 and p2 (and similarly for q). 26 A Large-Sample Test Procedure Then the standardized variable (9.4) has approximately a standard normal distribution when H0 is true. However, this Z cannot serve as a test statistic because the value of p is unknown—H0 asserts only that there is a common value of p, but does not say what that value is. 27 A Large-Sample Test Procedure A test statistic results from replacing p and q in (9.4) by appropriate estimators. Assuming that p1 = p2 = p, instead of separate samples of size m and n from two different populations (two different binomial distributions), we really have a single sample of size m + n from one population with proportion p. The total number of individuals in this combined sample having the characteristic of interest is X + Y. The natural estimator of p is then (9.5) 28 A Large-Sample Test Procedure The second expression for shows that it is actually a weighted average of estimators and obtained from the two samples. Using and = 1 – in place of p and q in (9.4) gives a test statistic having approximately a standard normal distribution when H0 is true. Null hypothesis: H0: p1 – p2 = 0 Test statistic value (large samples): 29 A Large-Sample Test Procedure Alternative Hypothesis Rejection Region for Approximate Level Test Ha: p1 – p2 > 0 z za Ha: p1 – p2 < 0 z –za Ha: p1 – p2 0 either z za/2 or z –za/2 A P-value is calculated in the same way as for previous z tests. The test can safely be used as long as are all at least 10. and 30 We skip Sec 9.5 31