Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
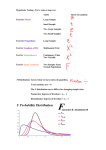
Hypothesis testing • Null hypothesis Ho - this hypothesis holds that if the data deviate from the norm in any way, that deviation is due strictly to chance. • Alternative hypothesis Ha - the data show something important. • Doing decision = accept/reject Ho (the decision centers around null hypothesis) Errors in hypothesis testing • Type I – False Positive • Type II – False Negative • The probability of Type I error: α • The probability of Type II error: β • Test involving sample from a normally distributed population. • Because it’s a normal distribution, you use zscores in the hypothesis test. z x n • The z-score here is called test statistics. • The test statistics constructed according the above formula holds only for the mean. • Tests for other statistics (e.g. variance) use different formulas. • Suppose you think that people living in a particular zip code have higher-than-average IQs. Your data are given in sheet ZIP, test this hypothesis. • n = 16, μZIP = 107.75, α = 0.05 • We know about IQ scores: μ = 100, σ = 16 • What will be the Ho and Ha? – Ha: μZIP > 100 – Ho: μZIP ≤ 100 • Can you reject Ho? x 107.75 100 7.75 z 1.94 16 4 n 16 What is the value of z that cuts off 5% of the area in a standard normal distribution? It’s exactly 1.645. So what’s the decision? The calculated value, 1.94, exceeds 1.645, so it’s in the rejection region. The decision is to reject Ho. • This hypothesis test is called one tailed (one sided). • The rejection region is in one tail of the sampling distribution. • A hypothesis test can be one tailed in the other direction. – Ha: μZIP < 100 – Ho: μZIP ≥ 100 • What is the critical value? -1.645 http://www.emathzone.com/tutorials/basic-statistics • Test can be also two-tailed. • The rejection region is in both tails of the Ho sampling distribution. – Ho: μZIP = 100 – Ha: μZIP ≠ 100 • What is the critical value now? – Find z-score that cuts 2.5% from right (=1.96) and from left (=-1.96). – 1.94 does not exceed 1.96, we do not reject Ho. http://www.emathzone.com/tutorials/basic-statistics • Using one tailed test we rejected Ho, while using two tailed test we did not!! • A two tailed test indicates that you’re looking for a difference between the sample mean and the null-hypothesis mean, but you don’t know in which direction. • A one tailed test shows that you have a pretty good idea of how the difference should come out. • For practical purposes, this means you should try to have enough knowledge to be able to specify a one tailed test. z-test in Excel • ZTEST – Do now: examples2.xlsx | ZIP – provide sample IQ data, null hypothesis value, σ (if omitted, s is used) – p-value is returned – If p-value < α, reject Ho. – Will you reject Ho or not? This is the result of ZTEST • For one tailed test you reject Ho. • What if you do two tailed test? Critical value for one tailed test α = 0.05 Our actual value (red line, pvalue = 0.026) is in the rejection region of one tailed test (0.026 < 0.05). However, it is outside rejection region for two tailed test. To see this, you must compare 0.026 > 0.025. Or you can 2x multiply this equation → 0.052 > 0.05. So if you have α set to 0.05, and you get p-value for one sided test, you get p-value for two sided test doubling the one sided p-value. t for one • In the real world you typically don’t have the luxury of working with such well-defined populations as results of IQ test. • Real world: – small samples – you often don’t know the population parameters • When that’s the case, you – use the sample data to estimate the population standard deviation – you treat the sampling distribution of the mean as a tdistribution – You use t as a test statistic • The formula for the test statistic x t s n with DF = n – 1. The higher the DF, the more closely the t-distribution resembles the normal distribution. • Company claims their vacuum cleaner averages four defects per unit. A consumer group believes this average is higher. The consumer group takes a sample of 9 cleaners and finds an average of 7 defects, with a standard deviation of 3.16. • Is companie’s claim correct or not? • Ho, Ha? – Ho: μ ≤ 4 – Ha: μ > 4 • And what else is missing in defining the hypothesis? – α = 0.05 • Now calculate t test statistic x 74 t 2.85 s 3.16 n 9 • Can you reject Ho? – Get critical value from tables or TINV. • Use Excel TDIST – returns p-value • reject Ho Testing a variance • The family of distributions for the test is called chi-square - χ2 • The formula for test statistics 2 n 1 s 2 2 With this test, you have to assume that what you’re measuring has a normal distribution. • Solve the following example using CHIDIST. • You produce a part of some machine that has to be a certain length with at most a standard deviation of 1.5 cm. • After measuring a sample of 26 parts, you find a standard deviation of 1.8 cm. • Is your process producing these parts OK? – Ho: σ2 ≤ 2.25 (remember to square the “at-most” standard deviation of 1.5 cm) – Ha: σ2 > 2.25 – α = 0.05 2 n 1 s 2 2 25 1.8 1.5 2 2 36 p-value = 0.0716. Do not reject Ho. Two sample hypothesis testing • Compare one sample with another. • Usually, this involves tests of hypotheses about population means. You can also test hypotheses about population variances. • Here’s an example. Imagine a new training technique designed to increase IQ. Take a sample of 25 people and train them under the new technique. Take another sample of 25 people and give them no special training. Suppose that the sample mean for the new technique is 107, and for the no-training sample it’s 101.2. – Did the technique really increased IQ? • Same principles: Ho (no difference between means), Ha, α – one-tailed test • Ho: μ1 – μ2 = 0, Ha: μ1 – μ2 > 0 • Ho: μ1 – μ2 = 0, Ha: μ1 – μ2 < 0 – two-tailed test • Ho: μ1 – μ2 = 0, Ha: μ1 – μ2 ≠ 0 – The zero is typical case, but it’s possible to test for any value. The first sample in the pair always has the same size, and the second sample in the pair always has the same size. The two sample sizes are not necessarily equal. CLT strikes again • If the samples are large, the sampling distribution of the difference between means is approximately a normal distribution. • If the populations are normally distributed, the sampling distribution is a normal distribution even if the samples are small. • The mean of the sampling distribution x x 1 2 1 2 • The standard deviation of the sampling distribution (standard error of the difference between means) 12 22 x x 1 2 n1 n2 • Because CLT says that the sampling distribution is approximately normal for large samples (or for small samples from normally distributed populations), you use the z-score as your test statistic. • i.e. you perform a z-test. • The z test statistics: x1 x2 1 2 z x x 1 2 • Solve the following. • Imagine a new training technique designed to increase IQ. Take a sample of 25 people and train them under the new technique. Take another sample of 25 people and give them no special training. Suppose that the sample mean for the new technique sample is 107, and for the no-training sample it’s 101.2. • Did the technique really increased IQ? • Ho: μ1 – μ2 = 0, Ha: μ1 – μ2 > 0, α = 0.05 • The IQ is known to have a standard deviation of 16, and I assume that standard deviation would be the same in the population of people trained on the new technique. x1 x2 1 2 107 101.2 z x x 1 2 162 162 25 25 5.8 1.28 4.53 • Use either NORMSDIST (supply 1.28, you get pvalue = 1-0.899=0.101) or NORMSINV (probability = 0.95, you get critical value equaling to 1.645). • Accept Ho. • Excel provides a tool z-Test: Two Sample for Means (Data | Data Analysis) • Do now – IQ_Test sheet Variable variance is 162 = 256 (16 is population standard deviation of IQ test distribution) t for Two • The previous example involves a situation you rarely encounter - known population variances. • Not knowing the variances takes the CLT out of play. This means that you can’t use the normal distribution as an approximation of the sampling distribution of the difference between means. • Instead, you use the t-distribution. You perform a t-test. • Unknown variances lead to two possibilities for hypothesis testing: – although the variances are unknown, you have reason to assume they’re equal – you cannot assume they’re equal t for Two – equal variances • Put sample variances together to estimate a population variance – pooling 2 2 N 1 s N 1 s 1 2 2 s 2p 1 N1 1 N2 1 DF x1 x2 1 2 t sp 1 1 N1 N 2 • FarKlempt Robotics is trying to choose between two machines to produce a component for its new microrobot. Speed is of the essence, so they have each machine produce ten copies of the component, and time each production run. • Which machine should they choose? Do now using Data Analysis, Mechine_speed sheet. s 2 p N1 1 s N 2 1 s N1 1 N2 1 2 1 2 2 x1 x2 1 2 t sp 1 1 N1 N 2 • Ho: μ1 - μ2 = 0, Ha: μ1 - μ2 ≠ 0, α = 0.05 • This is a two-tailed test, because we don’t know in advance which machine might be faster. Get critical value using TINV (+-2.10) or p-value using TDIST (0.0252). Result: reject Ho. • The worksheet function TTEST eliminates the muss, fuss, and bother of working through the formulas for the t-test. • Do now – Machines example in examples2.xlsx | Machine_speed It’s more desirable to use the equal variances t-test, which typically provides more degrees of freedom than the unequal variances t-test. • Do now – Data|Data Analysis, use t-Test: TwoSample Assuming Equal Variances t for Two – unequal variances • In the case of unequal variances, the t distribution with (N1-1) + (N2-1) DF is not as close an approximation to the sampling distribution. • DF must be reduced, fairly involved formulas are used to do this. • A pooled estimate is not appropriate. t-test is calculated as x1 x2 1 2 t s12 s22 N1 N 2 Testing two variances • classic: Ho: σ12 = σ22, Ha: σ12 ≠≥≤ σ22, α=0.05 • When you test two variances, you don’t subtract one from the other. Instead, you divide one by the other to calculate the test statistic. • This statistics is called F-ratio, and you’re doing F-test. larger s 2 F smaller s 2 • The family of distributions for the test is called the Fdistribution. • Each member of the family is associated with two values of DF (each DF is n - 1)! • And it makes a difference which DF is in the numerator and which DF is in the denominator. • One use of the F-distribution is in conjunction with the t-test for independent samples. • Before you do the t-test, you use F to help decide whether to assume equal variances or unequal variances in the samples. • Excel: FTEST, FDIST, FINV, F-Test: Two-Sample for Variances • Do now – FarKlempt Robotics produces 10 parts with Machine 1 and finds a sample variance of .60 cm2. They produce 15 parts with Machine 2 and find a sample variance of .44 cm2. Are these variances same? – Data are in the examples2.xlsx | Machine_var 0.60 F 1.36 0.44 • Estimate variances from data using VAR. • FDIST value is exactly ½ of FTEST. (FDIST is one-tailed, FTEST is two-tailed) • It finds a critical value. • Probability is 0.025, because two tailed test is with α = 0.05. For future use http://www.intuitor.com/statistics/CurveApplet.html β power α • Theoretically, when you test a null hypothesis versus an alternative hypothesis, each hypothesis corresponds to a separate sampling distribution. • When you do a hypothesis test, you never know which distribution produces the results. You work with a sample mean - a point on the horizontal axis. It’s your job to decide which distribution the sample mean is part of. You set up a critical value - a decision criterion. If the sample mean is on one side of the critical value, you reject Ho. If not, you don’t.