Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Introduction to Concurrency in Programming Languages:
Chapter 11: Data Parallelism
Matthew J. Sottile
Timothy G. Mattson
Craig E Rasmussen
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
1
Objectives
• Introduce the data parallel algorithmic pattern.
• Demonstrate application of this pattern to:
– Matrix multiplication
– Cellular automaton
• Discuss limitations of this pattern for general-purpose
programming.
• Discuss use of task parallel constructs to express data
parallelism.
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
2
The Algorithm Design Patterns
Start with a basic concurrency decomposition
•
•
•
A problem decomposed into a set of tasks
A data decomposition aligned with the set of tasks … designed to minimize
interactions between tasks and make concurrent updates to data safe.
Dependencies and ordering constraints between groups of tasks.
Specialist
Parallelism
Pipeline
Event Based
Coordination
Agenda
Parallelism
Task
Parallelism
Recursive
algorithms
Embarrassingly
Parallel
Separable
Dependencies
Result
Parallelism
Geometric
Decomposition
Data
Parallelism
Recursive
Data
Patterns covered in this lecture
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
3
Result Parallelism: Algorithm Patterns
• The core idea is to define the algorithm in terms of the data
structures within the problem and how they are
decomposed.
– Data parallelism:
• A broadly applicable pattern in which the parallelism is expressed as
streams of instructions applied concurrently to the elements of a data
structure (e.g., arrays).
– Geometric decomposition:
• A data parallel pattern where the data structures at the center of the
problem are broken into sub-regions or tiles that are distributed about
the threads or processes involved in the computation. The algorithm
consists of updates to local or interior points, exchange of boundary
regions, and update of the edges.
– Recursive data:
• A data parallel pattern used with recursively defined data structures.
Extra work (relative to the serial version of the algorithm) is expended
to traverse the data structure and define the concurrent tasks, but this
is compensated for by the potential for parallel speedup.
Not covered in this lecture
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
4
Supporting Patterns
•
Fork-join
–
•
SPMD
–
•
A process or thread (the master) sets up a task queue and manages other threads (the workers)
as they grab a task from the queue, carry out the computation, and then return for their next task.
This continues until the master detects that a termination condition has been met, at which point
the master ends the computation.
SIMD
–
•
Parallelism is expressed in terms of loops that execute concurrently.
Master-worker
–
•
Multiple copies of a single program are launched typically with their own view of the data. The
path through the program is determined in part base don a unique ID (a rank). This is by far the
most commonly used pattern with message passing APIs such as MPI.
Loop parallelism
–
•
A computation begins as a single thread of control. Additional threads are created as needed
(forked) to execute functions and then when complete terminate (join). The computation
continues as a single thread until a later time when more threads might be useful.
The computation is a single stream of instructions applied to the individual components of a data
structure (such as an array).
Functional parallelism
–
Concurrency is expressed as a distinct set of functions that execute concurrently. This pattern
may be used with an imperative semantics in which case the way the functions execute are
defined in the source code (e.g., event based coordination). Alternatively, this pattern can be
used with declarative semantics, such as within a functional language, where the functions are
defined but how (or when) they execute is dictated by the interaction of the data with the
language model.
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
5
Outline
• Data parallel algorithms and the SIMD Pattern
• Case studies:
– Matrix multiplication
– Cellular automaton
• Beyond SIMD
• Geometric decomposition
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
6
Data Parallelism Pattern
• Use when:
– Your problem is defined in terms of collections of data
elements operated on by a similar (if not identical)
sequence of instructions; i.e. the concurrency is in the
data.
• Solution
– Define collections of data elements that can be updated
in parallel.
– Define computation as a sequence of collective
operations applied together to each data element.
Tasks
Data 1
Data 2
Data 3
……
Data n
7
Source: Mattson and Keutzer, UCB CS294
SIMD: Single Instruction Multiple Data
• A supporting pattern for
data parallelism.
• Definition: A single
instruction stream is
applied to multiple data
elements.
• One program text
• One instruction counter
• Distinct data streams per
Processing Element (PE)
PE
PE
PE
PE
Source: Mattson and Keutzer, UCB CS294
8
Pattern Example: SIMD
• Definition: A single stream of program instructions execute in parallel
for different lanes in a data structure. There is only one program
counter for a SIMD program.
PU Index
Time
PU[1]
PU[2]
PU[3]
Prev Instruction
Prev Instruction
Prev Instruction
Load A[1]
Load A[2]
Load A[n]
Load B[1]
Load B[2]
Add(A[1], B[1])
Add(A[2], B[2])
Add(A[n], B[n])
Store C[1]
Store C[2]
Store C[n]
Next Instruction
Next Instruction
Next Instruction
……………
Load B[n]
SIMD operation of adding vector A and B into C
9
Source: Mattson and Keutzer, UCB CS294
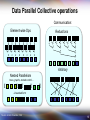
Data Parallel Collective operations
Communication:
Element-wise Ops
Reductions
+ + + + + + + +
+ + + + + + + +
+
+
+
+
+
+
+
Arbitrary
Nested Parallelism
trees, graphs, nested control …
[[
][
][[
][
]]]
Linearized form
Source: Ali Adl-Tabatabai, Intel
10
Outline
• Data parallel algorithms and the SIMD Pattern
• Case studies:
– Matrix multiplication
– Cellular automaton
• Limitations of SIMD data parallel programming
• Beyond SIMD
• Geometric decomposition
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
11
Matrix Multiplication
• Matrices are rectangular arrays of numbers.
• Linear Algebra is the branch of mathematics that deals with
matrices.
• Linear algebra is used for a wide range of applications
including:
–
–
–
–
–
–
–
–
Oil reservoir modeling
Quantum Chemistry
Image processing
Least squares and other statistics calculations
Seismic Signal processing
Financial analytics
Business analytics (operations research)
Graphics
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
12
Introduction to Linear Algebra
• Definition:
– Linear algebra: the branch of mathematics concerned with the study of
vectors, vector spaces, linear maps (also called linear transformations), and
systems of linear equations.
• Example: Consider the following system of linear equations
x + 2y + z = 1
x + 3y + 3z = 2
x + y + 4z = 6
– This system can be represented in terms of vectors and a matrix as
the classic “Ax = b” problem.
1
2
1
x
1
3
3
y
1
1
4
z
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
1
=
2
6
Source: Mattson and Keutzer, UCB CS294
13
Linear transformations
• A matrix, A ∈ RMxP multiplies a vector, x ∈ RP to define a linear
transformation of that vector into RM. By “linear” we mean that
A(βx+y) = βAx + Ay, where β is a scalar.
• Matrix multiplication defines the composition of two linear
transformations on that vector space
for (i=0; i<M; i++){
for (j=0; j<N; j++){
C[i][j] = 0.0;
for(k=0; k<P; k++){
C[i][j] += A[i][k] * B[k][j];
}
}
}
Compute C = A*B where
C ∈ RMxN
A ∈ RMxP
B ∈ RPxN
• Matrix multiplication is the core building block of Linear Algebra
– O(N2) memory accesses; O(N3) compute
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
14
Other key linear algebra operations
• LU Decomposition
– A = LU where L is a lower triangular matrix and U is an
upper triangular matrix.
• Cholesky Decomposition
– A = L*LT, symmetric positive definite A and L is lower
triangular
• QR Decomposition
– A=Q*R, Q is orthogonal and R is upper triangular
• Symmetric Eigenvalue problem
– For symmetric matrix A, find T such that
• T-1 A T = D
where D is a diagonal
• And many more
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
15
Matrix Multiplication (serial)
! three 2D arrays : a,b,c
real, dimension(100,100) :: a,b,c
! loop counters
integer
:: i,j,k
do i=1,100
do j=1,100
c(i,j) = 0.0
do k=1,100
c(i,j) = c(i,j) + a(i,k) * b(k,j)
end do
end do
end do
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
This operation is called a
dot product of the two
vectors a and b to produce
a scalar value for c(i,j)
16
Matrix Multiplication (Simple Data Parallel)
! three 2D arrays : a,b,c
real, dimension(100,100) :: a,b,c
! loop counters
integer :: i,j
Uses fine grained SIMD style
do i=1,100
parallelism to compute the dot-product
do j=1,100
c(i,j) = sum(a(i,:) * b(:,j))
end do
Array slice notation for
end do
the ith row of and the jth
column of b.
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
17
Array slice notation
• Designating different slices of an array.
A(:,:)
A(2,3)
A(3,:)
A(1:3,:)
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
A(:,3)
A(1:3,2:4)
18
Outline
• Data parallel algorithms and the SIMD Pattern
• Case studies:
– Matrix multiplication
– Cellular automaton
• Limitations of SIMD data parallel programming
• Beyond SIMD
• Geometric decomposition
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
19
Cellular Automaton
• An illustration of the Rule 30: 1D cellular
automaton over 200 time steps.
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
20
Initialize the cellular automaton
integer :: time = 0, finished = 100
integer :: cells(NUMCELLS), next(NUMCELLS)
integer :: left(NUMCELLS), right(NUMCELLS)
! ... initialization of all elements to zero,
! except for center cell
cells = 0
cells(NUMCELLS/2) = 1
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
21
Cellular automaton Time loop for 1D rule 30
do while (time < finished)
Circular shift of
! ... make working copies
array by 1 in each
next = cells
direction.
right = cshift(cells, 1)
left = cshift(cells, -1)
! ... apply rules
where (left == 1 .and. cells == 1 .and. right == 1) next = 0
where (left == 1 .and. cells == 1 .and. right == 0) next = 0
where (left == 1 .and. cells == 0 .and. right == 1) next = 0
where (left == 1 .and. cells == 0 .and. right == 0) next = 1
where (left == 0 .and. cells == 1 .and. right == 1) next = 1
where (left == 0 .and. cells == 1 .and. right == 0) next = 1
where (left == 0 .and. cells == 0 .and. right == 1) next = 1
where (left == 0 .and. cells == 0 .and. right == 0) next = 0
! ... obtain results from working copy
cells = next
time = time + 1
end do
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Check each
element of the
three arrays in
parallel, and
update the next
state of the array
based on the Rule
30 transition rules.
22
Outline
• Data parallel algorithms and the SIMD Pattern
• Case studies:
– Matrix multiplication
– Cellular automaton
• Beyond SIMD
• Geometric decomposition
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
23
Limitations of SIMD
• SIMD parallelism for data parallel algorithms is powerful
– Sequential, deterministic semantics for expressing parallel
algorithms.
• Writing the parallel program is easier
• Debugging is vastly simplified since a good supporting SIMD programming
environment is deterministic
• … but Strict SIMD parallelism is very limited
– Even naturally “data parallel’ algorithms where a single stream of
instructions operate on multiple data elements, the model breaks
down at boundaries
• Solution:
– Keep a single program text but let the instructions vary slightly
based on the ID of each processing element … i.e. the SPMD or
Single Program multiple data model
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
24
Data-par SPMD style
• SPMD approach for data parallel algorithms:
– Define an abstract index space that appropriately spans the
problem domain.
– Data structures in the problem are aligned to this index space.
– Tasks (e.g. work-items in OpenCL or “threads” in CUDA) operate
on these data structures for each point in the index space.
• This approach was popularized for graphics applications
where the index space mapped onto the pixels in an
image. More recently, It’s been extended to General
Purpose GPU (GPGPU) programming.
Note: This is basically a fine grained extreme form of the SPMD
pattern.
25
The BIG idea behind OpenCL
•OpenCL execution model … execute a kernel at each point in a
problem domain.
–E.g., process a 1024 x 1024 image with one kernel
invocation per pixel or 1024 x 1024 = 1,048,576
kernel executions
Traditional loops
void
trad_mul(int n,
const float *a,
const float *b,
float *c)
{
int i;
for (i=0; i<n; i++)
c[i] = a[i] * b[i];
}
Data Parallel OpenCL
kernel void
dp_mul(global const float *a,
global const float *b,
global float *c)
{
int id = get_global_id(0);
c[id] = a[id] * b[id];
} // execute over “n” work-items
Source: Khronos Group , GDC’2010 OpenCL overview
OpenCL:
An N-dimension domain of work-items
•Define an N-dimensioned index space that is “best” for
your algorithm
– Global Dimensions: 1024 x 1024 (whole problem space)
– Local Dimensions: 128 x 128
(work group … executes together)
1024
1024
Synchronization between work-items
possible only within workgroups:
barriers and memory fences
Cannot synchronize outside
of a workgroup
Source: Khronos Group , GDC’2010 OpenCL overview
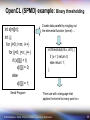
OpenCL (SPMD) example: Binary thresholding
int x[m][n];
int i,j;
for (i=0; i<m; i++)
for (j=0; j<n; j++)
if (x[i][j] < t)
x[i][j] = 0;
else
x[i][j] = 1;
Serial Program
Create data parallel by singling out
the elemental function (kernel) …
int threshold(int x, int t) {
if (x < t) return 0;
else return 1;
}
Then use with a language that
applies the kernel to every point in x
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
28
Binary Threshold (OpenCL Kernel)
• OpenCL Host
program (not shown)
– sets up the platform,
– defines the data (2D
array X),
– loads data onto the
compute device
– Launches the kernel for
each point in x
– Collects results back
from compute device
__kernel threshold(
__global int* x,
const
int t)
{
int i_id = get_global_id(0);
int j_id = get_global_id(1) ;
if (x[i_id][j_id] < t)
x[i_id][j_id] = 0;
else
x[i_id][j_id] = 1;
}
OpenCL kernel function
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
29
Using task parallelism (OpenMP) to express data
parallelism
for i=1:n
x(i) = a(i) * b(i);
x = a * b;
#pragma omp parallel for private(i)
for (i=0; i<n; i++)
x[i] = a[i] * b[i];
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Serial Vector
multiplication
Expressed with a data
parallel array notation
Mapping loop
iterations (tasks) onto
threads using
OpenMP
30
Outline
• Data parallel algorithms and the SIMD Pattern
• Case studies:
– Matrix Multiplication
– Cellular Automaton
• Beyond SIMD
• Geometric decomposition
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
31
Geometric Decomposition Pattern
• Name
– Geometric decomposition
• Problem
– How can an algorithm be organized around a data structures that
has been decomposed into concurrently updatable chunks?
• Context
– Consider a class of problems built around a core data structure
that can be decomposed into chunks that can be updated
concurrently.
– Updates of chunks in two phases: (1) local update computation
and (2) input from a subset of neighboring chunks.
• Forces
– Standard tradeoff … small chunks to increase load balancing
options vs. large chunks to reduce scheduling overhead.
– Performance sensitive to locality of data to UEs that will use it.
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
32
Geometric Decomposition Pattern: solution
• Solution involves the following steps:
– Decompose data … structured or unstructured. Manage granularity
to balance load.
– Implicit methods, linear algebra:
• See the linear algebra dwarf (I won’t repeat that content here)
– Explicit methods (image processing)
• Define Exchange operations to share data needed for local
update.
• Define a local update operation.
• Manage dual … data distribution and task scheduling
– Frequently uses ghost cells to hold all the data required for
a local update
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
33
2u 0
Geometric decomposition example:
solving partial differential equations
• Laplace’s equation:
– u is a potential field (gravitational, electrostatic, etc.)
in free space (no sinks, no sources)
• Poisson’s equation:
– u is a potential field with sources of sinks (f(x,y,z)).
• Diffusion problems:
– E.g. u is non-steady-state temperature or
concentration of a diffusing substance … α2 is the
diffusion constant.
• Wave equation:
– u is displacement from equilibrium for oscillatory
medium or field … ν is speed of propagation
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
2u 0
2u f ( x, y, z )
1 u
u 2
t
2
2
1
u
2
u 2 2
t
Source: Mattson and Keutzer, UCB CS294
34
Boundary and Initial Conditions
• A given problem is defined by the PDE and
the key constraints:
– Initial conditions: starting point for
propagation problems
– Boundary conditions: specified on
domain boundaries to provide the interior
solution in computational domain
R
R
s
n
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
35
Solving PDEs
• In simplest cases, they can be solved analytically.
• For “interesting” problems they must be solved numerically.
• Numerical solution consists of the following steps:
– Define the problem:
• Define the domain
• Define functions to compute values within the domain
• Define Boundary conditions.
– Discretize the domain … turn the continuous problem into a
discrete problem … i.e. superimpose a mesh over the domain and
find values at points on the mesh
– Define methods to update values at a mesh point based on other
values in the mesh.
– Propagate a solution as dynamic variables (often time) evolves.
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
36
Example: finite difference methods
• Solve the heat diffusion equation in 1 D:
– u(x,t) describes the temperature field
– We set the heat diffusion constant to one
– Boundary conditions, constant u at endpoints.
•
map onto a mesh with stepsize h and k
• Central difference approximation for spatial
derivative (at fixed time)
• Time derivative at t = tn+1
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
2u
u
x 2
t
xi x0 + ih
ti t0 + ik
u j +1 2u j + u j 1
2u
2
x
h2
du
u n +1 u n
dt
k
Source: Mattson and Keutzer, UCB CS294
37
Example: Explicit finite differences
• Combining time derivative expression using spatial derivative at t = tn
u nj +1 u nj
k
u nj+1 2u nj + u nj1
h2
• Solve for u at time n+1 and step j
u nj+1 (1 2r )u nj + ru nj1 + ru nj+1
rk
h2
• The solution at t = tn+1 is determined explicitly from the solution at t = tn
(assume u[t][0] = u[t][N] = Constant for all t).
for(int t=0; t<K-1; t++)
for (int x=1; x<N-1; x++)
u[t+1][x] = (1-2*r)*u[t][x] + r*u[t][x-1] + r*u[t][x+1];
• Explicit methods are easy to compute … each point updated based on
nearest neighbors. Converges for r<1/2.
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
38
Explicit methods: A Stencil problem in 2D
• Stencil methods: replace each Grid point with linear combination of
neighbors.
• Stencil methods extensively used in image processing as well.
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
39
Geometric Decomposition Pattern: solution
• Example: finite difference solver with a 5 point
stencil
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
40
Geometric Decomposition Pattern: solution
Decompose into “chunks”
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
41
Geometric Decomposition Pattern: solution
Add ghost cells (1/2
width of stencil)
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
42
Geometric Decomposition Pattern: solution
Update values in ghost cells,
Stencil has everything it
needs to update local values.
Parallel computation in
phases:
•Update ghost cells
•Move stencil over local
block
•Go to next iteration
© 2009 Matthew J. Sottile, Timothy G. Mattson, and Craig E Rasmussen
Source: Mattson and Keutzer, UCB CS294
43