Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
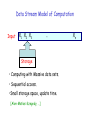
Estimating the Sortedness of a Data Stream Parikshit Gopalan U T Austin T. S. Jayram IBM Almaden Robert Krauthgamer IBM Almaden Ravi Kumar Yahoo! Research Data Stream Model of Computation Input X1 X2 X 3 … Storage • Computing with Massive data sets. • Sequential access. •Small storage space, update time. [Alon-Matias-Szegedy, …] Xn Sorting on Data-Streams Cannot sort efficiently. Can we tell if the data needs to be sorted? [Ergun-Kannan-Kumar-Rubinfeld-Vishwanathan, Ajtai-Jayram-Kumar-Sivakumar, Gupta-Zane, Cormode-Muthukrishnan-Sahinalp, LibenNowell-Vee-Zhu, Ailon-Chazelle-Commandur-Liu] Sorting on Data-Streams • Cannot sort efficiently on a data-stream. • Can we tell if the data needs to be sorted? [Ergun-Kannan-Kumar-Rubinfeld-Vishwanathan, Ajtai-Jayram-Kumar-Sivakumar, Gupta-Zane, Cormode-Muthukrishnan-Sahinalp, LibenNowell-Vee-Zhu, Ailon-Chazelle-Commandur-Liu] • Measuring distance from Sortedness: Kendall Tau distance Spearman Footrule distance Ulam distance Candidate metrics 1. Spearman’s footrule [ℓ1 distance] : 3 5 7 9 10 4 1 2 6 8 e 1 2 3 4 5 6 7 8 9 10 Easy to compute. Candidate metrics 2. Kendall Tau distance [No. of Inversions] Inversions: Positions i < j where (i) > (j) 3 5 7 9 10 4 1 2 6 8 Candidate metrics 2. Kendall Tau distance [No. of Inversions] Inversions: Positions i < j where (i) > (j) 3 5 7 9 10 4 1 2 6 8 Candidate metrics 2. Kendall Tau distance [No. of Inversions] Within a factor-2 of Spearman’s footrule. [DiaconisGraham] An O(log n) space, 1-pass (1 + ) algorithm. [AjtaiJayram-Kumar-Sivakumar] Candidate metrics 3. Ulam distance [Edit Distance]: Ed(): Number of deletions needed to sort. Ulam: Fastest way to sort a bridge hand. Edit Distance and the LIS Ed(): Number of deletions needed to sort. 5 7 8 1 10 4 2 3 6 9 Edit Distance and the LIS Ed(): Number of deletions needed to sort. 5 7 8 1 10 4 2 3 6 9 Delete 5 7 8 10 Insert 1 2 3 4 5 6 7 8 9 10 Edit Distance and the LIS Ed() : Number of deletions needed to sort . LIS() : Length of the longest increasing sequence. Ed() + LIS() = n Studied in statistics, biology, computer science … Both take a global view of the sequence. Hard for models like streaming, sketching, property-testing. 151 … 190 51 … 80 81 … 100 Prior Work • Exact Computation of Ed() and LIS() : – Patience Sorting [Ross,Mallows] Patience Sorting 5 7 8 1 10 4 2 3 6 9 0 5 7 8 Patience Sorting 5 7 8 1 10 4 2 3 6 9 0 1 5 7 8 10 Patience Sorting 5 7 8 1 10 4 2 3 6 9 0 1 4 5 7 8 10 Patience Sorting 5 7 8 1 10 4 2 3 6 9 0 2 1 4 5 7 8 10 Number in place i: Earliest end to IS of length i. Patience Sorting 5 7 8 1 10 4 2 3 6 9 0 2 1 4 3 5 7 8 10 Number in place i: Earliest end to IS of length i. Patience Sorting 5 7 8 1 10 4 2 3 6 9 0 2 1 4 3 6 5 7 8 10 9 Number in place i: Earliest end to IS of length i. Patience Sorting 5 7 8 1 10 4 2 3 6 9 0 0 2 1 4 3 6 5 7 8 10 9 Number in place i: Earliest end to IS of length i. Patience Sorting 5 7 8 1 10 4 2 3 6 9 0 LIS 0 2 1 4 3 6 5 7 8 10 Length of LIS 9 Prior Work • Exact Computation of Ed() and LIS() : – Patience Sorting [Ross,Mallows] – O(n) space, 1-pass streaming algorithm. – (√n) space lower bound. [LibenNowell-Vee-Zhu] • Approximating Ed() and LIS() : – No sub-linear space algorithms, no lower bounds. [Ajtai et al, Cormode et al, LibenNowell et al] • LIS Algorithms parametrized by length of LIS : [LibenNowell-Vee-Zhu, Sun-Woodruff] • Computing Ed() in other models: – Property Testing [Ergun et al, Ailon et al] – Sketching [Charikar-Krauthgamer] Our Results • Approximating Ed() : – An O(log2 n) space, randomized 4-approximation for Ed(). – A O(√n) space, deterministic (1 + ε)-approximation for Ed(). • Approximating the LIS: – A O(√n) space, deterministic (1 + ε)-approximation for LIS(). • Exact Computation of Ed() and LIS(): – An (n) space lower bound for randomized algorithms. – Independently proved by [Sun-Woodruff]. • Lower bounds for approximating the LIS: – Conjecture: Deterministic algorithms require (√n) space for (1 + ε)-approximation Computing the Edit Distance Thm: For any ε > 0,there is a one-pass randomized algorithm using O(ε-2log2 n) space and update time, that gives a (4 + ε) approximation to Ed(). 1. Combinatorial measure that approximates Ulam distance. Builds on [Ergun et al, Ailon et al]. 2. Sampling scheme to compute this measure in one pass. A Voting Scheme [Ergun et al.] Combinatorial measure called Unpopularity. Neighborhoods of (i) : Intervals starting or ending at i. 1 3 7 8 6 5 9 2 A Voting Scheme [Ergun et al.] Combinatorial measure called Unpopularity. Neighborhoods of (i) : Intervals starting or ending at i. Deciding if (i) is unpopular: For every neighborhood of (i) Every number in the neighborhood votes on “Is (i) out of order?” If majority in some neighborhood vote against (i), it is marked unpopular. Let U() denote no. of unpopular numbers. [Ergun et al]: Ed() ≤ U() [Ailon et al]: U() ≤ 2 Ed() A Voting Scheme [Ergun et al.] Can we estimate U() using a streaming algorithm? 4 5 3 7 1 2 A Voting Scheme [Ergun et al.] Can we estimate U() using a streaming algorithm? 4 5 3 7 1 2 Impossible to decide if (i) is unpopular before seeing the entire input. A New Voting Scheme • Neighborhoods of (i) : Intervals ending at i. • If majority in some neighborhood vote against (i), it is marked unpopular. • Unpopularity based only on past, not the future. Thm: Let V() denote no. of unpopular numbers. Then Ed()/2 ≤ V() ≤ 2 Ed() A Voting Scheme • Let Ed() = k. Then V() ≤ 2k. • Fix an optimal Bad set of size k to delete. How many numbers can be Unpopular ? Partition Unpopular into Good and Bad. Good numbers form an increasing sequence. Good never votes against Good. Good + Unpopular ≡ Bad neighborhood ! A Voting Scheme • Let Ed() = k. Then V() ≤ 2k. • Fix an optimal Bad set of size k to delete. Good + Unpopular ≡ Bad neighborhood ! If k numbers are Bad, At most k are Good + Unpopular. Bad numbers might all be Unpopular. Hence V() ≤ 2k. A Voting Scheme • Let Ed() = k. Then V() ≤ 2k. • Bound can be tight. 100 99 98 … 91 1 2 3 … 10 11 12 … 90 100 99 98 … 91 1 2 3 … 10 11 12 … 90 100 99 98 … 91 1 2 3 … 10 11 12 … 90 A Voting Scheme • Let V() = k. Then Ed() ≤ 2k. • Fix the set of k Unpopular elements. Algorithm to produce an increasing sequence: 1. Scan right to left. 2. Delete Unpopular elements + Inversions w.r.t last number in sequence. At least half of deletions are Unpopular numbers. What remains is an increasing sequence. A Voting Scheme • Let V() = k. Then Ed() ≤ 2k. • Bound can be tight. 11 … 50 91 92 93 … 100 1 2 3 … 10 51 … 90 11 … 50 91 92 93 … 100 1 2 3 … 10 51 … 90 11 … 50 91 92 93 … 100 1 2 3 … 10 51 … 90 A New Voting Scheme • Neighborhoods of (i) : Intervals ending at i. • If majority in some neighborhood vote against (i), it is marked unpopular. • Unpopularity based only on past, not the future. Thm: Let V() denote no. of unpopular numbers. Then Ed()/2 ≤ V() ≤ 2 Ed() Can we estimate V() efficiently? Outline of Sampling Scheme Taking a vote in one neighborhood: – Take O(log n) samples, take the (approx) majority. Reservoir Sampling [Vitter]. 1 3 7 8 6 5 9 2 Computing V() : Need O(log n) samples from every neighborhood. 1 3 7 8 6 5 9 2 Outline of Sampling Scheme Computing V() : Need O(log n) samples from every neighborhood. 1 3 7 8 6 5 9 2 Key observation: Don’t need samples across intervals to be independent! Roughly O(log2 n) samples suffice. Deterministic Algorithm for LIS Thm: For any ε > 0,there is a one-pass deterministic algorithm using O(n/ε)1/2 space and update time, that gives a (1 - ε) approximation to LIS(). Based on multiplayer communication protocol for LIS: 10 51 … 19 32 … 80 15 … 50 • Algorithm simulates protocol for √n players. Two-Player Protocol for LIS 1000 5123 … 1319 n/2 Patience Sorting 6 24 … 1000 k Multiples of εk 6…1000 1/ε 3245 4582 … 8021 Approximating the LIS Consider k-player communication protocol for LIS: 10 51 … 19 32 … 80 15 … 50 • As k increases, maximum message size increases. Conjecture: For some ε0 > 0, every 1-pass deterministic algorithm that gives a (1 + ε0) approximation to LIS() requires (√n) space. Proving the conjecture requires analyzing k ≥ √n Lower Bounds for approximating the LIS Conjecture: For some ε0 > 0, every 1-pass deterministic algorithm that gives a (1 + ε0) approximation to LIS() requires (√n) space. Candidate Hard Instances? 1.8 2.9 3.7 4.9 1.6 2.8 3.5 4.6 1.3 2.5 3.3 4.5 1 2 3.2 4.2 Lower Bounds for approximating the LIS Conjecture: For some ε0 > 0, every 1-pass deterministic algorithm that gives a (1 + ε0) approximation to LIS() requires (√n) space. Candidate Hard Instances? Yes No 1.8 2.9 3.7 4.9 1.7 2.8 3.4 4.8 1.6 2.8 3.5 4.6 1.6 2.6 3.5 4.6 1.3 2.5 3.3 4.5 1.3 2.5 3.6 4.5 1.1 2.1 1 2 3.2 4.2 3.9 4.2 Lower Bounds for approximating the LIS Conjecture: For some ε0 > 0, every 1-pass deterministic algorithm that gives a (1 + ε0) approximation to LIS() requires (√n) space. Candidate Hard Instances? Yes No 1.8 2.9 3.7 4.9 1.7 2.8 3.4 4.8 1.6 2.8 3.5 4.6 1.6 2.6 3.5 4.6 1.3 2.5 3.3 4.5 1.3 2.5 3.6 4.5 1.1 2.1 1 2 3.2 4.2 3.9 4.2 Lower Bounds for approximating the LIS Conjecture: For some ε0 > 0, every 1-pass deterministic algorithm that gives a (1 + ε0) approximation to LIS() requires (√n) space. Candidate Hard Instances? Yes No 1.8 2.9 3.7 4.9 1.7 2.8 3.4 4.8 1.6 2.8 3.5 4.6 1.6 2.6 3.5 4.6 1.3 2.5 3.3 4.5 1.3 2.5 3.6 4.5 1.1 2.1 3.9 4.2 1 2 3.2 4.2 Open Problems Estimate the Edit distance between two permutations. Tight bounds for approximation: Show (√n) lower bound for deterministic algorithms. Randomized algorithm for LIS ?