Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
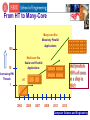
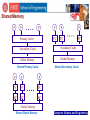
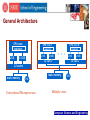
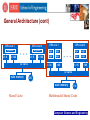
Advanced Computer Architecture CSE 8383 April 17, 2008 Session 11 Computer Science and Engineering Contents 1. Multi-Core Why now? A Paradigm Shift Multi-Core Architecture 2. Case Studies IBM Cell Intel Core 2Duo AMD Computer Science and Engineering The Path to Multi-Core Computer Science and Engineering Background Wafer Thin slice of semiconducting material, such as a silicon crystal, upon which microcircuits are constructed Die Size The die size of the processor refers to its physical surface area size on the wafer. It is typically measured in square millimeters (mm^2). In essence a "die" is really a chip . the smaller the chip, the more of them that can be made from a single wafer. Circuit Size The level of miniaturization of the processor. In order to pack more transistors into the same space, they must be continually made smaller and smaller. Measured in Microns (mm) or Nanometer (nm) Computer Science and Engineering Examples 386C Die Size: 42 mm2 1.0 m technology 275,000 transistors Pentium Die Size: 148 mm2 0.5 m technology 3.2 million transistors 486C Die Size: 90 mm2 0.7 m technology 1.2 million transistors Pentium III Die Size: 106 mm2 0.18m technology 28 million transistors Computer Science and Engineering Pentium III (0.18 m process technology) Source: Fred Pollack, Intel. New Micro-architecture Challenges in the coming Generations of CMOS Process Technologies. Micro32 Computer Science and Engineering Computer Science and Engineering nm Process Technology Technology (nm) 90 65 45 32 22 Integration Capacity (BT) 2 4 8 16 32 Computer Science and Engineering Increasing Die Size Using the same technology Increasing the Die Size 2-3X 1.5-1.7X in Performance. Power is proportional to Die-area * Frequency We cannot produce microprocessors with ever increasing Die size – The constraint is POWER Computer Science and Engineering Reducing circuit Size Reducing circuit size in particular is key to reducing the size of the chip. The first generation Pentium used a 0.8 micron circuit size, and required 296 square millimeters per chip. The second generation chip had the circuit size reduced to 0.6 microns, and the die size dropped by a full 50% to 148 square millimeters. Computer Science and Engineering Shrink transistors by 30% every generation transistor density doubles, oxide thickness shrinks, frequency increases, and threshold voltage decreases. Gate thickness cannot keep on shrinking slowing frequency increase, less threshold voltage reduction. Computer Science and Engineering Processor Evolution Generation i (0.5 mm, for example) Generation i +1 (0.35 mm, for example) • Gate delay reduces by 1/ 2 (frequency up by 2 ) • Number of transistors in a constant area goes up by 2 (Deeper pipelines, ILP, more cashes) • Additional transistors enable an additional 2 increase in performance • Result: 2x performance at roughly equal cost Computer Science and Engineering What happens to power if we hold die size constant at each generation? Allows ~ 100% growth in transistors each generation Source: Fred Pollack, Intel. New Micro-architecture Challenges in the coming Generations of CMOS Process Technologies. Micro32 Computer Science and Engineering What happens to die Size if we hold power constant at each generation? Die size has to reduce ~ 25% in area each generation 50% growth in transistors, which limits PERFORMANCE, Power Density is still a problem Source: Fred Pollack, Intel. New Micro-architecture Challenges in the coming Generations of CMOS Process Technologies. Micro32 Computer Science and Engineering Power Density continues to soar Source: Intel Developer Forum, Spring 2004 Pat Gelsinger (Pentium at 90 W) Computer Science and Engineering Business as Usual won’t work: Power is a Major Barrier As Processor Continue to improve in Performance and Speed, Power consumption and heat dissipation have become major challenges Higher costs: • Thermal Packaging • Fans • Electricity • Air conditioning Computer Science and Engineering A new Paradigm Shift Old Paradigm Performance == improved Frequency, unconstrained power, voltage scaling New Paradigm: Performance == improved IPC, Multi-core, power efficient micro architecture advancement Computer Science and Engineering Multiple CPUs on a Single Chip An attractive option for chip designers because of the availability of cores from earlier processor generations, which, when shrunk down to present-day process technology, are small enough for aggregation into a single die Computer Science and Engineering Multi-core Technology Generation i Generation i Technology Generation i+1 Generation i Generation i • Gate delay does not reduce much • The frequency and performance of each core is the same or a little less than previous generation Computer Science and Engineering From HT to Many-Core Many-core Era Massively Parallel Applications 100 Multi-core Era Scalar and Parallel Applications 10 Increasing HW Threads Intel predicts 100’s of cores on a chip in 2015 HT 1 2003 2005 2007 2009 2011 2013 Computer Science and Engineering Multi-cores are Reality # of Cores Source: Saman Amarasinghe, MIT (6.189 2007, lecture-1) Computer Science and Engineering Multi-Core Architecture Computer Science and Engineering Multi-core Architecture Multiple cores are being integrated on a single chip and made available for general purpose computing Higher levels of integration – multiple processing cores Caches memory controllers some I/O processing) Network on Chip (NoC) Computer Science and Engineering M M M M Interconnection Networks P M P P M P P P M P P Shared memory • One copy of data shared among multiple cores • Synchronization via locking • intel M P Interconnection Networks Distributed memory • Cores access local data • Cores exchange data Computer Science and Engineering Memory Access Alternatives Symmetric Multiprocessors (SMP) Global Memory Message Passing (MP) Distributed Memory Shared address Distributed space address space SMP Symmetric Multiprocessors Distributed Shared Memory (DSM) DMS Distributed Shared Memory MP Message Passing Computer Science and Engineering Network on Chip (NoC) control data Traditional Bus I/O Switch Network Computer Science and Engineering Shared Memory P P P Primary Cache P P P PC PC PC Secondary Cache Secondary Cache Global Memory Global Memory Shared Primary Cache Shared Secondary Cache P P P PC PC PC SC SC SC Global Memory Shared Global Memory Computer Science and Engineering General Architecture CPU core registers L1 I$ CPU core 1 CPU core N registers registers L1 I$ L1 D$ L1 D$ L1 I$ L2 cache L1 D$ L2 cache L2 cache main memory main memory I/O Conventional Microprocessor I/O Multiple cores Computer Science and Engineering General Architecture (cont) CPU core 1 CPU core N registers registers L1 I$ L1 D$ L1 I$ L2 cache L1 D$ CPU core 1 CPU core N regs regs regs regs regs regs regs regs L1 D$ L1 I$ L1 I$ L1 D$ L2 cache main memory I/O main memory Shared Cache I/O Multithreaded Shared Cache Computer Science and Engineering “Case Studies” Computer Science and Engineering Case Study 1: “IBM’s Cell Processor” Computer Science and Engineering Cell Highlights Supercomputer on a chip Multi-core microprocessor(9 cores) >4 Ghz clock frequency 10X performance for many applications Computer Science and Engineering Key Attributes Cell is Multi-core -Contains 64-bit power architecture -Contains 8 synergetic processor elements Cell is a Broadband Architecture -SPE is RISC architecture with SIMD organization and local store -128+ concurrent transactions to memory per processor Cell is a Real-Time Architecture -Resource allocation (for bandwidth measurement) -Locking caching (via replacement management table) Cell is a Security Enabled Architecture -Isolate SPE for flexible security programming Computer Science and Engineering Cell Processor Components Computer Science and Engineering Cell BE Processor Block Diagram Computer Science and Engineering POWER Processing Element (PPE) POWER Processing Unit (PPU) connected to a 512KB L2 cache. Responsible for running the OS and coordinating the SPEs. Key design goals: maximize the performance/power ratio as well as the performance/area ratio. Dual-issue, in-order processor with dual-thread support Utilizes delayed-execution pipelines and allows limited outof-order execution of load instructions. Computer Science and Engineering Synergistic Processing Elements (SPE) Dual-issue, in-order machine with a large 128-entry, 128-bit register file used for both floating-point and integer operations Modular design consisting of a Synergistic Processing Unit (SPU) and a Memory Flow Controller (MFC). Compute engine with SIMD support and 256KB of dedicated local storage. The MFC contains a DMA controller with an associated MMU and an Atomic Unit to handle synch operations with other SPUs and the PPU. Computer Science and Engineering SPE (cont.) They operate directly on instructions and data from its dedicated local store. They rely on a channel interface to access the main memory and other local stores. The channel interface, which is in the MFC, runs independently of the SPU and is capable of translating addresses and doing DMA transfers while the SPU continues with the program execution. SIMD support can perform operations on 16 8bit, 8 16-bit, 4 32-bit integers, or 4 singleprecision floating-point numbers per cycle. At 3.2GHz, each SPU is capable of performing up to 51.2 billion 8-bit integer operations or 25.6GFLOPs in single precision. Computer Science and Engineering Four levels of Parallelism Blade level 2 cell processors per blade Chip level 9 cores Instruction level Dual issue pipelines on each SPE Register level Native SIMD on SPE and PPE VMX Computer Science and Engineering Cell Chip Floor plan Computer Science and Engineering Element Interconnect Bus (EIB) Implemented as a ring Interconnect 12 elements: 1 PPE with 51.2GB/s aggregate bandwidth 8 SPEs: each with 51.2GB/s aggregate bandwidth MIC: 25.6GB/s of memory bandwidth 2 IOIF: 35GB/s(out), 25GB/s(in) of I/O bandwidth Support two transfer modes DMA between SPEs MMIO/DMA between PPE and system memory Source: Ainsworth & Pinkston, On Characterizing Performance of the Cell Broad band Engine Element Interconnect Bus, 1st International Symp. on NOCS 2007 Computer Science and Engineering Element Interconnect Bus (EIB) An EIB consists of the following: 1. Four 16 byte-wide rings (two in each direction) 1.1 Each ring capable of handling up to 3 concurrent non-overlapping transfers 1.2 Supports up to 12 data transfers at a time 2. A shared command bus 2.1 Distributes commands 2.2 Sets up end to end transactions 2.3 Handles coherency 3. A central data arbiter to connect the 12 Cell elements 3.1 Implemented in a star-like structure 3.2 It controls access to the EIB data rings on a per transaction basis Source: Ainsworth & Pinkston, On Characterizing Performance of the Cell Broad band Engine Element Interconnect Bus, 1st International Symp. on NOCS 2007 Computer Science and Engineering Element Interconnect Bus (EIB) Computer Science and Engineering Cell Manufacturing Parameters About 234 million transistors (compared with 125 million for Pentium 4) that runs at more than 4.0 GHz As compared to conventional processors, Cell is fairly large, with a die size of 221 square millimeters The introductory design is fabricated using a 90 nm Silicon on insulator (SOL) process In March 2007 IBM announced that the 65 nm version of Cell BE (Broadband Engine) is in production Computer Science and Engineering Cell Power Consumption Each SPE consumes about 1 W when clocked at 2 GHz, 2 W at 3 GHz, and 4 W at 4 GHz Including the eight SPEs, the PPE, and other logic, the CELL processor will dissipate close to 15W at 2 GHz, 30W at 3 GHz, and approximately 60W 4 GHz Computer Science and Engineering Cell Power Management Dynamic Power Management (DPM) Five Power Management States One linear sensor Ten digital thermal sensors Computer Science and Engineering Case Study 2: “Intel’s Core 2 Duo ” Computer Science and Engineering Intel Core 2 Duo Highlights Multi-core microprocessor(2 cores) It has a range of 1.5 to 3 Ghz clock frequency 2X performance for many applications Dedicated level 1 cache and shared level 2 cache Its shared L2 cache comes in two flavors: 2MB and 4MB, depending on the model It supports 64bit architecture Computer Science and Engineering Intel Core 2 Duo Block Diagram Dedicated L1$ Shared L2$ The two cores exchange data implicitly through the shared level 2 cache Computer Science and Engineering Intel Core 2 Duo Architecture Reduced front-side bus traffic: effective data sharing between cores allows data requests to be resolved at the shared cache level instead of going all the way to the system memory One Copy needed to be retrieved Core 1 had to retrieve the data from Core 2 by going all the way through the FSB and Main Memory Computer Science and Engineering Intel’s Core 2 Duo Manufacturing Parameters About 291 million transistors Compared to Cell’s 221 square millimeters, Core 2 Duo has a smaller die size between 143 and 107 square millimeters depending on the model. The current Intel process technology for the Dual core ranges between 65 nm and 45nm (2007) with an estimate of 155 million transistors . Computer Science and Engineering Intel Core 2 Duo Power Consumption Power consumption in Core 2 Duo ranges 65w-130w depending on the model. Assuming you have 75 w processor model (Conroe is 65W) it will cost you $4 to keep your computer up for the whole month Computer Science and Engineering Intel Core 2 Duo Power Management It uses 65 nm technology instead of the previous 90nm technology (Less voltage requirements) Aggressive clock gating Enhanced Speed-Step Low VCC Arrays Blocks controlled via sleep transistors Low leakage transistors Computer Science and Engineering Case Study 3: “AMD’s Quad-Core Processor (Barcelona) ” Computer Science and Engineering AMD Quad-Core Highlights Designed to enable simultaneous 32- and 64-bit computing Minimizes the cost of transition and maximizes current investments Integrated DDR2 Memory Controller Increases application performance by dramatically reducing memory latency Scales memory bandwidth and performance to match compute needs HyperTranspor Technology Provides up to 24.0GB/s peak bandwidth per processor, reducing I/O bottlenecks Computer Science and Engineering AMD Quad-Core Block Diagram Dedicated L1$ and L2$ Shared L3$ Computer Science and Engineering AMD Quad-Core Architecture It has a crossbar switch instead of the usual bus used in dual core processors It lowers the probability of having memory access collisions L3$ to alleviate the memory access latency since we have a greater possibility of accessing the memory due to the high number of cores Computer Science and Engineering AMD Quad-Core Architecture (cont) Cache Hierarchy : Dedicated L1 cache 2 way associative 8 banks (each 16B wide). Dedicated L2 cache 16 way associative victim cache, exclusive w.r.t L1 Shared L3 cache 32 way associative Fills from L3 leave likely shared lines in L3 Victim cache, partially exclusive w.r.t. L2 Sharing aware replacement policy Replacement policies: L1,L2: pseudo LRU L3:Sharing aware pseudo LRU Computer Science and Engineering AMD Quad-Core Manufacturing Parameters The current AMD process technology for Quad-Core is 65nm It is comprised of approximately 463M transistors (about 119M less than Intel’s quad-core Kentsfield) It has a die size of 285 square millimeters (Compared to Cell’s 221 square millimeters) Computer Science and Engineering AMD Quad-Core Power Consumption Power consumption in AMD Quad-Core ranges 68-95w( compared to 65w-130w of Intel’s Core 2 Duo) depending on the model. AMD CoolCore Technology Reduces processor energy consumption by turning off unused parts of the processor. For example, the memory controller can turn off the write logic when reading from memory, helping reduce system power Power can be switched on or off within a single clock cycle, saving energy with no impact to performance Computer Science and Engineering AMD Quad-Core Power Management Native quad-core technology enables enhanced power management across all four cores Computer Science and Engineering