Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
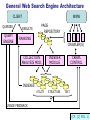
Web Search – Summer Term 2006 VI. Web Search Ranking (c) Wolfgang Hürst, Albert-Ludwigs-University Personalized and Topic-Sensitive PageRank Uniform distribution (1-d) to model jumps to random web pages is not realistic (bookmarks, known URLs, ...) Idea: Use jump probability for personalization, i.e. - Instead of identity matrix: Weighting based on personal preferences (e.g. bookmarks) - Problem: Pre-calculation impossible (personal data!) and online calculation to expensive Another characteristic of PageRank: query independent - Might be critical if page with high PageRank accidentally gets selected as relevant - Idea: Create a topic-sensitive PageRank Topic-Sensitive PageRank Basic idea: 1. Identify topic that might be interesting for the user (e.g. via classification of the query, eval. of context, ...) 2. Use pre-calculated, topic-sensitive PageRank Similarities to personalization but - Fixed, pre-specified topics (can be pre-calculated!) - Depending on the actual situation (more flexible) Topic specific PageRank rankjd: Normally: Identity matrix (aij = 1 or 1/N) Now: Topics c1, ..., cn, e.g. the 16 top-level categories from the Open directory project Topic dependent weighting (1/|Ti|) Advantage: Can be calculated in advance SOURCE: [5] Topic-Sensitive PageRank (cont.) Question: Which one to select during run time? Idea: Automatic classification of the topic based on the query q given by the user Extension: Consider context q' of query q, e.g. - surrounding text if query was entered via highlighting - based on the history (if available) etc. Calculation (e.g.) using a unigram language model: SOURCE: [5] Topic-Sensitive PageRank (cont.) Alternative approach: Use probabilities, i.e. - Weighted summation of all topic specific PageRanks for one document - Weights: Depending on the probability of a particular topic being relevant given the query q - Definition: Query-Sensitive Importance Score sqd In practice: Usually just take the three topic-sensitive PageRanks with highest probability Disadvantages: - Fixed set of topics - Depends on training set SOURCE: [5] References - Indexing [1] A. ARASU, J. CHO, H. GARCIA-MOLINA, A. PAEPCKE, S. RAGHAVAN: "SEARCHING THE WEB", ACM TRANSACTIONS ON INTERNET TECHNOLOGY, VOL 1/1, AUG. 2001 Chapter 5 (Ranking and Link Analysis) [2] S. BRIN, L. PAGE: "THE ANATOMY OF A LARGE-SCALE HYPERTEXTUAL WEB SEARCH ENGINE", WWW 1998 Chapter 2 and 4.5.1 [3] BORDER, KUMAR, MAGHOUL, RAGHAVAN, RAJAGOPALAN, STATA, TOMKINS, WIENER: "GRAPH STRUCTURE IN THE WEB", WWW 2000 [4] PAGE, BRIN, MOTWANI, WINOGRAD: "THE PAGERANK CITATION RANKING: BRINGING ORDER TO THE WEB", STANFORD TECHNICAL REPORT [5] HAVELIWALA: "TOPIC-SENSITIVE PAGERANK", WWW 2002 General Web Search Engine Architecture CLIENT QUERIES QUERY ENGINE WWW RESULTS PAGE REPOSITORY RANKING CRAWLER(S) COLLECTION ANALYSIS MOD. INDEXER MODULE CRAWL CONTROL INDEXES UTILITY STRUCTURE TEXT USAGE FEEDBACK (CF. [1] FIG. 1)