Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
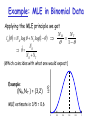
Tutorial #3 by Ma’ayan Fishelson This presentation has been cut and slightly edited from Nir Friedman’s full course of 12 lectures which is available at www.cs.huji.ac.il/~pmai. Changes made by Dan Geiger, Ydo Wexler and Ma’ayan Fishelson. Example: Binomial Experiment Head Tail When tossed, it can land in one of two positions: Head or Tail. We denote by the (unknown) probability P(H). Estimation task: Given a sequence of toss samples x[1], x[2],…,x[M] we want to estimate the probabilities P(H) = and P(T) = 1 - . Statistical Parameter Fitting Consider instances x[1], x[2], …, x[M] such that: – The set of values x can take is known. – Each one is sampled from the same distribution. i.i.d. – Each one is sampled independently of the rest. samples The task is to find the vector of parameters that have generated the given data. This parameter vector can be used to predict future data. The Likelihood Function How good is a particular ? It depends on how likely it is to generate the observed data: LD ( ) P( D | ) P( x[m] | ) m L() The likelihood for the sequence H,T, T, H, H is: LD ( ) (1 ) (1 ) 0 0.2 0.4 0.6 0.8 1 Sufficient Statistics To compute the likelihood in the thumbtack example we only require NH and NT (the number of heads and the number of tails). LD ( ) NH (1 ) NT NH and NT are sufficient statistics for the binomial distribution. Sufficient Statistics A sufficient statistic is a function of the data that summarizes the relevant information for the likelihood. Formally, s(D) is a sufficient statistics if for any two datasets D and D’: s(D) = s(D’ ) LD() = LD’() Datasets Statistics Maximum Likelihood Estimation MLE Principle: Choose parameters that maximize the likelihood function • One of the most commonly used estimators in statistics. • Intuitively appealing. • One usually maximizes the log-likelihood function defined as lD() = logeLD(). Example: MLE in Binomial Data Applying the MLE principle we get NH NT lD N H log NT log 1 1 NH ˆ N H NT Example: (NH,NT ) = (3,2) L() (Which coincides with what one would expect) MLE estimate is 3/5 = 0.6 0 0.2 0.4 0.6 0.8 1 From Binomial to Multinomial • For example, suppose that X can have the values 1,2,…,K (for example, a die has 6 faces). • We want to learn the parameters 1, 2. …, K. Sufficient statistics: N1, N2, …, NK - the number of times each outcome is observed. K Nk Likelihood function: LD ( ) k k 1 Nk ˆ MLE: k N Example: Multinomial • Let x1,x2,…,xn be a protein sequence. • We want to learn the parameters q1, q2,…,q20 corresponding to the frequencies of the 20 amino-acids. • Let N1, N2,…,N20 be the number of times each amino-acid is observed in the sequence. Likelihood function: 20 LD (q ) qk k 1 MLE: Nk qk n Nk Is MLE all we need? • Suppose that after 10 observations, – ML estimate is P(H) = 0.7 for the thumbtack. – Would you bet on heads for the next toss? • Suppose now that after 10 observations, – ML estimate is P(H) = 0.7 for a coin. – Would you place the same bet? Solution: The Bayesian approach that incorporates your subjective prior knowledge. E.g., you may know a priori that some amino acids have high frequencies and some have low frequencies. How would one use this information ? Bayes’ rule Bayes’ rule: P x | y P y P y | x P( x) where, P x P x | y P y y It holds because: Px, y Px | y P y P x P x, y P x | y P y y y Example: Dishonest Casino • • • A casino uses 2 kind of dice: 99% are fair. 1% is loaded: 6 comes up 50% of the times We pick a die at random and roll it 3 times. We get 3 consecutive sixes. What is the probability the die is loaded? Dishonest Casino (2) The solution is based on using Bayes rule and the fact that while P(loaded | 3 sixes) is not known, the other three terms in Bayes rule are known, namely: • P(3 sixes | loaded)=(0.5)3 • P(loaded)=0.01 • P(3 sixes) = P(3 sixes|loaded) P(loaded)+P(3 sixes|fair) P(fair) P(3sixes | loaded ) P(loaded ) P(loaded | 3sixes) P(3sixes) Dishonest Casino (3) P (3sixes | loaded ) P (loaded ) P (loaded | 3sixes) P (3sixes) P (3sixes | loaded ) P (loaded ) P (3sixes | loaded ) P (loaded ) P (3sixes | fair ) P( fair ) 0.53 0.01 3 1 0.5 0.01 0.99 6 3 0.21 Biological Example: Proteins • Extra-cellular proteins have a slightly different amino acid composition than intra-cellular proteins. • From a large enough protein database (SWISS-PROT), we can get the following: qainti p(ai|int) - the frequency of amino acid ai for intra-cellular proteins qaexti p(ai|ext) - the frequency of amino acid ai for extra-cellular proteins p(int) - the probability that any new sequence is intra-cellular p(ext) - the probability that any new sequence is extra-cellular Biological Example: Proteins (2) Q: What is the probability that a given new protein sequence x=x1x2….xn is extra-cellular? • A: Assuming that every sequence is either extra-cellular or intra-cellular (but not both), we can write: p(ext) 1 p(int) . • Thus, px p(ext) px | ext p(int) px | int Biological Example: Proteins (3) • Using conditional probability we get px | ext p(xi | ext) , px | int p( xi | int) i i • By Bayes’ theorem Pext | x p(ext) p( xi | ext) i p(ext) p( xi | ext) p(int) p( xi | int) i i • The probabilities p(int), p(ext) are called the prior probabilities. • The probability P(ext|x) is called the posterior probability.