Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
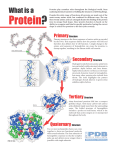
Comparing protein structure and sequence similarities Sumi Singh Sp 2015 Learning goals • To get a good understanding of vector space model. • To be able to compute similarity between documents. • To be able to rank the output documents based on their similarity to query document. Dataset • Proteins are made up of amino acid sequences of various lengths. The average length being 300 amino acid long. There are total 20 possible amino acids. • The representation of proteins is in a specific format called PDB format (discussed later). • PDB stands for protein database and is very large online repository of proteins. Protein Data Bank (PDB) • Protein Data Bank (PDB) is a large online database that keeps various information on proteins including sequence information. • • Web address: http://www.rcsb.org/pdb/home/home.do PDB ID: A 4-character PDB ID is assigned to each new structure at the time of deposition. The IDs are automatically assigned and do not have meaning. However, they serve as the unique, immutable identifier of each entry in the Protein Data Bank. As such, they are used throughout the scientific literature (e.g. in journal articles and in other databases) to refer to entries in the Protein Data Bank. Hence, if the PDB ID of an entry in the Protein Data Bank is known, it is the most direct way to retrieve it from the database. How to get protein file using PDB id? Go to the link below for access details http://www.rcsb.org/pdb/static.do?p=download/http/index.html • • Use the link below with wget to get the uncompressed PDB file for a given protein http://www.rcsb.org/ pdb/files/xxxx.pdb Where xxxx is the 4 character PDB id of a protein. What to extract • Protein is made up of amino acids. There are ONLY 20 possible amino acids. • These amino acids are represented by their three letter abbreviation. • To get the sequence information of a protein, you need to extract the amino acid from the PDB file for each protein. Sequence information-How to extract • For each PDB file corresponding to a given protein, get all the amino acid THREE letter codes from column 18-20 that satisfy the following criteria: – The record name is ATOM (column 1-6) – The atom name if CA ( column 13-16) • There will be several repeating amino acids How to use the extracted information • Save the extracted sequence in a sequence repository, to ensure availability for future matches. • Use vector space model to represent each protein with features as amino acid. • Use a distance/similarity measure to calculate the similarity of an unknown protein with the proteins stored locally. Requirements of submission • A GUI that gives user option to enter a PDB ID. • Checks if the sequence of protein with that ID is in the local directory/repository. • If not get the PDB file for that protein from the online database and extract the sequence information, save it. • Perform the pair wise similarity calculation with the rest of the proteins in the local repository. • Display ranked output with respect to similarity. References • Vector space model: http://nlp.stanford.edu/IR-book/pdf/06vect.pdf • Distance measure: http://nlp.stanford.edu/IR-book/pdf/07system.pdf • PDB format: http://www.wwpdb.org/documentation/fileformat/format33/v3.3.html • Contact: [email protected]