Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Entity–attribute–value model wikipedia , lookup
Concurrency control wikipedia , lookup
Microsoft SQL Server wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Relational model wikipedia , lookup
Functional Database Model wikipedia , lookup
Healthcare Cost and Utilization Project wikipedia , lookup
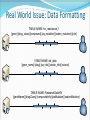
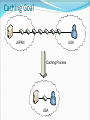
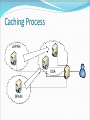
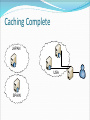
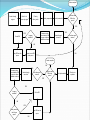
Optimized Data Migration within a System of Linked Medical Research Databases By Jared Christopherson U. of Connecticut Problem to Address Medical research requires connections to multiple hospitals, institutions, or online databases Data must be compiled manually Process is time-consuming General Project Goal Project Goals: Present data as though from a single source Give the researcher flexibility with viewing the data Optimize data flow with site caching Real World Issue: Data Formatting Real World Issue: Data Formatting TABLE NAME: hiv_resistance_1 [gene] [drug_class] [compound] [aa_mutation] [codon_mutation] [cite] TABLE NAME: db_data [gene_name] [drug] [aa_info] [codon_info] [source] TABLE NAME: ResearchDataHIV [geneName] [drugClass] [compoundInfo] [aaMutation] [codonMutation] Solution: Master Template hiv_resistance_1: gene db_data: gene_name Gene ResearchDataHIV: geneName hiv_resistance_1: cite db_data: source Source hiv_resistance_1: codon_mutation db_data: codon_info Codon Mutation ResearchDataHIV: codonMutation Master Template: [Gene] [Source] [Codon Mutation] Master Templates and Display Templates Database Store ID: 1 Stanford Cancer Database 64.434.343.99 Admin/password Master Template - Cancer [Age] [Cancer Type] [Drug Class] Display Template 1 [Age] [Cancer Type] [Drug Class] Display Template 2 ID -> Table Name -> Field Name [Cancer Type] [Drug Class] ID: 2 UConn Database 44.254.292.34 Admin/password Master Template – HIV Resistance [Compound] [Codon] [Result] ID: 3 HIV Research Database 23.32.232.19 Admin/password ID -> Table Name -> Field Name Display Template 1 [Compound] [Result] Display Template 2 [Compound] [Codon] [Result] Basic Functionality Provides a simple search for users Researchers have the option of selecting a pre-set Display Template to only display data relevant to their needs Queries each database individually according to the Master Template Returns results and (optionally) compiles them into a single list Use AJAX to return results for each database Caching and Optimization Goal: researchers should have fastest access possible to the info they seek X-RAY or MRI images could be 2-5Mb in size each What if researchers in the US consistently need access to data on a server in Asia? Local access would be fastest Caching Goal JAPAN USA Caching Process USA Caching and Optimization: Possible Solutions Move everything to a central server Move records around as they are accessed Cache everything Cache databases based on usage Query and Result Set – No Caching JAPAN USA SPAIN Caching Process JAPAN USA SPAIN Caching Complete JAPAN USA SPAIN Region Caching Database Caching Queue – What to cache? For each region, determines the top external servers used based on a percentage of queries Database Caching Queue Need a method to determine the most heavily requested external databases for each region Track statistics: Convert IP address -> region whenever a user performs a search Increment result count for the record that keeps track of the region ID and database ID DB Queue to Cache USA USA DB1 (Japan) – 345 results DB7 (Spain) – 793 results DB16 (USA) – 539 results DB3 (Japan) – 491 results DB7 (Spain) – 49% DB3 (Japan) – 30% DB1 (Japan) – 21% JAPAN JAPAN DB1 (Japan) – 212 results DB7 (Spain) – 343 results DB16 (USA) – 112 results DB3 (Japan) – 312 results DB7 (Spain) – 75% DB16 (USA) – 25% Caching and Optimization: Where to cache data Real-world constraints allow_cache supersite bandwidth cache_size Cache complete NO Iterate through regions Get a list of servers by region Filter by allow_cache Filter by supersite Are there more DBs in the queue? Sort by bandwidth YES YES Compare cache size needed by DB in queue to space available on server Is space available? Cache DB YES Iterate through server list Are there more servers? NO Drop DB from the queue NO Iterate to next DB in the queue Cache complete NO YES Compare cache size needed by DB in queue to space available on server Iterate through server list Are there more DBs in the queue? Are there more servers? YES YES Is space available? Cache DB NO YES Do any servers in the list have space? Drop DB from the queue NO Sort by bandwidth Filter by nonsupersite Caching and Optimization: Script Process Runs at frequency set by admin This process continues for each region with the program assigning data to servers with progressively lower bandwidth and cache_size scores until all the server space from that region is exhausted Caching and Optimization: Script Process At the end, each region should have as many local copies of the most frequently requested databases as possible Cached copies are read-only Further Work and Improvements Allow different types of databases (DAL) Remove overlapping data Script to determine when individual caches need to be updated