Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
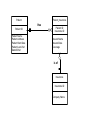
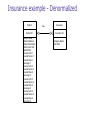
Agenda – 04/18/2006 and 04/20/2006 Identify tasks in physical database design. Define the design goals for physical database design. Discuss relevant tasks in physical database design. Discuss considerations for database performance. 1 What is physical database design? The process of translating a logical description of data into technical specifications for storing and retrieving data. Preparing documentation for actual implementation of tables in a database. 2 Physical vs. logical design A physical design can look exactly like a logical design. Small database: Logical design usually is the same as physical design. Or a physical design can look different than a logical design. Large database: Physical design will probably change entity structure to ensure good performance. Differences between physical and logical design stem from: Goals. Constraints. 3 Design goals for physical database design Provide adequate performance. Ensure database integrity. Provide database security. Anticipate recoverability. 4 Tasks in physical design Convert entities into tables. Identify all necessary data attributes. Determine correct size and data type for each data attribute. Choose an appropriate primary key. Identify foreign keys necessary to sustain relationships. Define necessary constraints. Enhance performance. Identify size and access methods of data. Choose appropriate hardware. Create indices. De-normalize the design as necessary. Create design and procedures for archiving data. 5 employee PK employeeID LastName FirstName Initial Address1 Address2 ZipCode EmployeeType Course PK CourseID is Name Description Faculty PK,FK1 employeeID ContractType TerminalDegree DateEarned Diversity PK,FK1 CourseID YearStart Approval Qualification is instructed by UnivCapstone PK,FK1 CourseID YearStart Approval CourseOffering PK,FK2 PK PK PK CourseID Section# Semester Year FK1 StartTime Room# Duration employeeID Classified PK,FK1 employeeID PositionGrade LastUpdate Administrative PK,FK1 employeeID PaySplit AdminAssignment Questions to answer during physical design for the sample database How should the super-type of EMPLOYEE be related to the required sub-types? Separate tables or the same table? How do you relate a sub-type of a generalization relationship (FACULTY) with a weak entity (COURSE OFFERING)? How will the supertype of COURSE be related to the potential sub-types of the course? Separate tables or the same table? What should you do with the concatenated key in COURSE OFFERING? 7 Name Type Primary Key Foreign Key Other Constraints SSN Char(9) Yes No Not null Name Varchar2(30) No No Not null Address1 Varchar2(30) No No Address2 Varchar2(30) No No City Varchar2(20) No No State Char(2) No No Zip Char(9) No No Birth_date Date No No Emp_type Char(2) No No Ed_level Char(6) No No Grant_type Char(8) No No Fund_Category Number(4) No No Emp_level Char(5) No No Contract_type Char(4) No No Must be f or c Must be ‘A1’ through ‘A7’ Name Type Primary Key Foreign Key Constraints Course_id Char(6) Yes No Not null Name Varchar2(25) No No Not null Description Varchar2(75) No No Min_credits Number(1) No No Must be >= 1 Max_credits Number(1) No No Must be <= 6 Name Type Primary Key Foreign Key Constraints Course_id Char(6) Yes Yes – ref course Not null Course_type Char(6) Yes No Must be ‘d’ or ‘cap’ Start_date Date No No Not null Approval Char(15) No No Not null Qual Varchar2(100) No No Not null Choosing datatypes for attributes A datatype is a name or label for a set of values and some operations which one can perform on that set of values. Examples in SQL: varchar, date, number, integer Concept of “strongly data typed.” Objectives for choosing an appropriate data type: Minimize storage space. Represent all possible values. Improve data integrity. Support all data manipulations. 10 Choosing an appropriate primary key General rules: Must be a unique value for each row in the table. Cannot be null. Should be static over the life of the row. Physical primary key design heuristics: Should be a single attribute. Should be numeric. Should not be “intelligent.” Should be able to be an “enterprise key.” 11 Overview of Database Performance Key metrics for database performance Minimize response time to access data in a database. Minimize response time to change contents in a database. Most concerned with balancing disk access and memory capacity. Application buffers: DBMS Buffers: Logical records (LRs) Logical records (LRs) inside of physical records (PRs) LR1 read PR 1 LR2 Operating system: Physical records (PRs) on disk read LR1 LR2 PR1 LR3 write write PR2 LR4 LR3 PR2 LR4 12 Input data relevant to performance Table profile Number of tables Number of rows in a table Number of attributes in a table Application profile Number of screens Number of reports Frequency of screen/reports Number of intended joins Types of queries Expected response time 13 Improving performance With optimizing use of existing resources. With better or more resources. With indexes. With denormalization. With procedures to archive data. 14 Cluster files to better use memory and disk access time Application buffers: DBMS Buffers: Logical records (LRs) Logical records (LRs) inside of physical records (PRs) LR1 read PR 1 LR2 Operating system: Physical records (PRs) on disk read LR1 LR2 PR1 LR3 write write PR2 LR4 LR3 PR2 LR4 CREATE CLUSTER ordering (CLUSTERKEY CHAR(6)) CREATE TABLE (customer_id Address CLUSTER ordering tbl_customer CHAR(6) NOT NULL, VARCHARs(25)) (customer_id); CREATE TABLE (order_id Customer_id Order_date CLUSTER ordering tbl_order CHAR(6) NOT NULL, CHAR(6) NOT NULL, date) (customer_id); Add or change resources to improve performance. Will help a little: more processor power. Will help more: more memory. Will really help: Faster, more efficient disk. RAID: Redundant arrays of inexpensive (or independent) disks. A set of multiple physical disk drives that appear to the designer and user as a single storage unit. Segments of data, called stripes, cut across all of the disk drives. Access can occur concurrently. www.acnc.com/04_01_00.html www.raidweb.com/whatis.html Different types of RAID are available. RAID-0 through RAID-7, RAID-10, 53, 0+1. RAID Example Improving performance with indexes Indexes are probably the single most important tool for improving the performance of a database. Can add an index to a database with a simple SQL command: Create index index_name on table (column_name); Understanding what happens when an index is created requires a basic understanding of indexing and file organization. 19 File organization and access concepts File organization. The physical arrangement of data in a file into records and pages on secondary storage. File organization dictates the physical placement of records. File access methods. The steps involved in retrieving records from a file. File access methods dictate how data can be retrieved from secondary storage. Options include: Sequential access from beginning. Sequential access from pre-defined point. Backwards from end. Backwards from pre-defined point. Direct. (not really direct – has to go through a series of indices) 20 General file organization options Sequential file organization. Records are stored one after another. Referred to as a “heap” or “pile.” Indexed file organization. Records are stored either ordered or not as in sequential organization. Additional structure, index, is built based on pre-determined keys for the records. 21 What is an index? An additional physical file. An index is a sorted list of pointers stored along with the actual data. Benefit: Indexes provide faster direct data access. Drawbacks: Indexes create slower data updates. Indexes require periodic reorganization. 22 What types of indices are used? Indexes are frequently stored in a structure called a B+-tree. Other types of indices are: Bitmap index. Identifies the value of a given column in a given row as being “true/on” or “false/off”. Join index. Creates an index for multiple tables that are commonly joined together for pre-defined queries. 23 Clustered vs. non-clustered indices Clustered index. Declaration means actual table data will be ordered by the clustered index. Can only have one clustered index per table. Greatly improves access time for tables frequently accessed by clustered index. Decreases update performance if data is volatile. Not available on all DBMS’s. Non-clustered index. Usually the default indexing structure. Does not change the order of the table data. Functions as a “secondary” index. 24 Rules of thumb for applying indexes Use on larger tables. Use when a relatively small percentage of the table will be accessed. Index the primary key of each table. Index frequently used search attributes. Index attributes in SQL “ORDER BY” and “GROUP BY” commands. Use indexes heavily for non-volatile databases; limit the use of indexes for volatile databases. Avoid indexing attributes that consist of long character strings. 25 Issues in indexing Indexes affect table maintenance performance. Each time an add or delete is performed, the index must be updated along with the data. Depending on the size of the database, these index updates can be extremely time-consuming. Imagine the problems with having an index declared for every attribute. Solutions: Remove indexes prior to batch updates. Recreate indexes after the batch update is finished. Consider using a batch procedure to create indexes after a table has been updated, and before queries are run. 26 Improving performance with denormalization Modify the degree of normalization. Recognize that joins require much time when used in queries. More joins = more time. Combine entities with 1:1 relationship into a single entity. Combine entities with 1:m relationship into a single entity. Usually done with brief repeating groups. 27 Example for denormalization Example: A patient can have up to 4 insurance companies. Patient is a strong entity. Insurance company is a strong entity. Normally, the repeating group of insurance companies would be in a separate intersection entity relating a patient to one or more insurance companies. Diagram on next page 28 Patient Patient_Insurance Has Patient ID Patient Name Patient Address Patient Start Date Patient Last Visit DateOfVisit Patient ID Insurance ID Insured Name Insured Date Coverage is of Insurance Insurance ID Company Name Insurance example - Denormalized Patient Patient ID Patient Name Patient Address Patient Start Date Patient Last Visit DateOfVisit Insurance ID 1 Insured Name 1 Insured Date 1 Coverage 1 Insurance ID 2 Insured Name 2 Insured Date 2 Coverage 2 Insurance ID 3 Insured Name 3 Insured Date 3 Coverage 3 Insurance ID 4 Insured Name 4 Insured Date 4 Coverage 4 has Insurance Insurance ID Company Name Date Start Issues in denormalization Can be risky. Introduces potential for data redundancy. Can result in data anomalies. Should be documented. This documentation must be maintained as an “audit path” to the actual implementation of the database. Logical data model details fully normalized database with an ERD. Physical data model will show denormalized database with an ERD. Include in the documentation the reasons for denormalization. 31 Improving performance with derived data Derived or calculated data is usually not included in a database. Not ever included on a logical data model. Examples of derived data include: extended price, total amount, total pay, etc. Problems with including derived data in a database: What happens when the underlying data is changed? How do you ensure that the derived data will also be changed? For example, let’s say that the total of an order is kept in the database. What happens when an item quantity changes, or an item price changes? The order total, if stored, must also be changed to reflect those changes in the underlying data. 32 When to include derived data Sometimes it is a good idea to include derived data in the physical database design: Use when aggregate values are regularly retrieved. Use when aggregate values are costly to calculate. Permit updating only of source data. Do not put derived rows in same table as table containing source data. Examples of derived data frequently stored on databases: Student class standing. Order and invoice total. Credit card balance. Checking account balance. 33 Organization must manage data resources Types of data used by an organization: Current transaction data. Historical data for decision making. Audit data for accounting and/or governmental regulations. Data differentiation: external vs. internal All must be designed, implemented and maintained. Must have procedures for extracting, transforming and loading (ETL) data as necessary. 34 Archive data for audit purposes Not all data must be stored on a directly accessible data storage device (disk). Examples of archived data: Checking transactions. Tax data. Accounting audit trail. Can store data on tape or other cheaper, less accessible media. Must have procedures for extracting, transforming and loading (ETL) data as necessary. Archive database design is usually a copy of the transaction database design. 35 Use a data warehouse A Data warehouse differs from a transaction database. Used to support decision making. Contains aggregated data. Is frequently denormalized to improve performance. Contains data in a format specific to answering queries. Data warehouse is separate from transaction database. A data warehouse is built from data stored in the transaction database. Different design. May use a data warehouse and a transaction database concurrently to answer queries. 36