Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Registry of World Record Size Shells wikipedia , lookup
Extensible Storage Engine wikipedia , lookup
Concurrency control wikipedia , lookup
Microsoft Jet Database Engine wikipedia , lookup
Database model wikipedia , lookup
Clusterpoint wikipedia , lookup
ContactPoint wikipedia , lookup
Chapter 13: Query Processing
Database System Concepts, 5th Ed.
©Silberschatz, Korth and Sudarshan
See www.db-book.com for conditions on re-use
Chapter 13: Query Processing
Overview
Measures of Query Cost
Join Operation
Database System Concepts - 5th Edition, Aug 27, 2005.
13.2
©Silberschatz, Korth and Sudarshan
Basic Steps in Query Processing
1. Parsing and translation
2. Optimization
3. Evaluation
Database System Concepts - 5th Edition, Aug 27, 2005.
13.3
©Silberschatz, Korth and Sudarshan
Basic Steps in Query Processing
(Cont.)
Parsing and translation
translate the query into its internal form. This is then translated into
relational algebra.
Parser checks syntax, verifies relations
Evaluation
The query-execution engine takes a query-evaluation plan, executes
that plan, and returns the answers to the query.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.4
©Silberschatz, Korth and Sudarshan
Basic Steps in Query Processing :
Optimization
A relational algebra expression may have many equivalent expressions
E.g., balance2500(balance(account)) is equivalent to
balance(balance2500(account))
Each relational algebra operation can be evaluated using one of several
different algorithms
Correspondingly, a relational-algebra expression can be evaluated in
many ways.
Annotated expression specifying detailed evaluation strategy is called an
evaluation-plan.
E.g., can use an index on balance to find accounts with balance < 2500,
or can perform complete relation scan and discard accounts with
balance 2500
Database System Concepts - 5th Edition, Aug 27, 2005.
13.5
©Silberschatz, Korth and Sudarshan
Evaluation Plan
An evaluation plan defines exactly what algorithm is used for each
operation, and how the execution of the operations is coordinated.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.6
©Silberschatz, Korth and Sudarshan
Basic Steps: Optimization (Cont.)
Query Optimization: Amongst all equivalent evaluation plans choose
the one with lowest cost.
Cost is estimated using statistical information from the
database catalog
e.g. number of tuples in each relation, size of tuples, etc.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.7
©Silberschatz, Korth and Sudarshan
Measures of Query Cost
Cost is generally measured as total elapsed time for answering
query
Many factors contribute to time cost
disk accesses, CPU, or even network communication
Typically disk access is the predominant cost, and is also
relatively easy to estimate. Measured by taking into account
Number of seeks
* average-seek-cost
Number of blocks read
* average-block-read-cost
Number of blocks written * average-block-write-cost
Database System Concepts - 5th Edition, Aug 27, 2005.
13.8
©Silberschatz, Korth and Sudarshan
Measures of Query Cost (Cont.)
For simplicity we just use the number of block transfers from disk as the
cost measures
tT – time to transfer one block
Cost for b block transfers
b * tT
Database System Concepts - 5th Edition, Aug 27, 2005.
13.9
©Silberschatz, Korth and Sudarshan
Join Operation
Several different algorithms to implement joins
1. Nested-loop join
2. Block nested-loop join
3. Indexed nested-loop join
4. Merge-join
5. Hash-join
Choice based on cost estimate
Database System Concepts - 5th Edition, Aug 27, 2005.
13.10
©Silberschatz, Korth and Sudarshan
Join Operation
-
Join Strategies
Consider
deposit(branch-name, account-#, customer-name, balance)
customer(customer-name, c-st, c-city)
Consider deposit
nd
nc
customer
= 10,000
= 200
Simple Iteration (Nested-loop join) :
Assume no indices.
It must examine 10,000 * 200 = 2,000,000 pairs of tuples
Expensive since it examines every pair of tuples in the two relations.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.11
©Silberschatz, Korth and Sudarshan
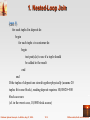
1. Nested-Loop Join
(case 1)
for each tuple d in deposit do
begin
for each tuple c in customer do
begin
test pair(d,c) to see if a tuple should
be added to the result
end
end
If the tuples of deposit are stored together physically (assume 20
tuples fit in one block), reading deposit requires 10,000/20=500
block accesses
(cf. in the worst case, 10,000 block access)
Database System Concepts - 5th Edition, Aug 27, 2005.
13.12
©Silberschatz, Korth and Sudarshan
1. Nested-Loop Join (Cont.)
As for the customer, 200/20 = 10 accesses per tuple of deposit if it is stored together
physically.
Thus 10 * 10,000 = 100,000 block accesses to customer are needed to process the
query.
∴ total : 100,500 block accesses
Database System Concepts - 5th Edition, Aug 27, 2005.
13.13
©Silberschatz, Korth and Sudarshan
1. Nested-Loop Join (Cont.)
(case 2)
Assume that customer in the outer loop and deposit in the inner loop.
100,000 accesses to deposit (200 * (10,000/20) = 100,000) + 10
accesses to read the customer (200/20 = 10)
∴ total 100,010 block accesses
Thus the choice of inner and outer loop relations can have a
dramatic effect on the cost of evaluating queries.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.14
©Silberschatz, Korth and Sudarshan
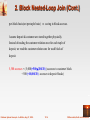
2. Block Nested-Loop Join
Variant of nested-loop join in which every block of inner relation is paired
with every block of outer relation.
Block-Oriented Iteration :
for each block Bd of deposit do
begin
for each block Bc of customer do
begin
for each tuple d in Bd do
begin
for each tuple c in Bc do
begin
test pair(d,c) to see if a tuple
should be added to the result
end
end
end
end
Database System Concepts - 5th Edition, Aug 27, 2005.
13.15
©Silberschatz, Korth and Sudarshan
2. Block Nested-Loop Join (Cont.)
per-block basis(not per-tuple basis) saving in block accesses.
Assume deposit & customer are stored together physically.
Instead of reading the customer relation once for each tuple of
deposit, we read the customer relation one for each block of
deposit.
5,500 accesses = ( 5,000(=500(200/20) ) accesses to customer block
+ 500(=10,000/20) accesses to deposit blocks)
Database System Concepts - 5th Edition, Aug 27, 2005.
13.16
©Silberschatz, Korth and Sudarshan
2. Block Nested-Loop Join (Cont.)
Think customer : outer loop
deposit : inner loop
(10 (10,000/20) = 10 500
= 5,000 access to deposit + 10 (200/20 = 10) accesses to customer)
= 5,000+10 =5,010 accesses.
A major advantage to use of the smaller relation(customer) in
the inner loop is that it may be possible to store the entire
relation in main memory temporarily.
If customer fit in M.M, 500 block access to read deposit + 10
blocks to read customer
510 accesses
Database System Concepts - 5th Edition, Aug 27, 2005.
13.17
©Silberschatz, Korth and Sudarshan
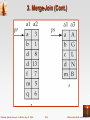
3. Merge-Join
Merge-Join :
Assume that both relations are in sorted order on the join
attributes and are stored together physically
deposit
customer 510 block accesses
Merge-Join allows us to compute the join by reading each block
exactly once.
500 block accesses to read deposit (10,000/20 = 500)
+ 10 block accesses to read customer (200/20 = 10)
510 block accesses
Database System Concepts - 5th Edition, Aug 27, 2005.
13.18
©Silberschatz, Korth and Sudarshan
3. Merge-Join (Cont.)
Algorithms :
- A group of tuples of one relation with the same value on the join
attributes is read.
- The corresponding tuples of the other relation are read.
- Since the relations are in sorted order, tuples with the same value on the
join attributes are in consecutive order. This allows us to read each tuple
only once.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.19
©Silberschatz, Korth and Sudarshan
3. Merge-Join (Cont.)
Database System Concepts - 5th Edition, Aug 27, 2005.
13.20
©Silberschatz, Korth and Sudarshan
4. Indexed nested-loop join
Simple iteration (Nested-loop join)
deposit
customer 10,000 X 200 = 2,000,000
block accesses (no physical clustering of tuples)
Merge-join requires sorted order.
Block-oriented iteration requires that tuples of each relation be stored
physically together.
But there are no restrictions on the simple iteration (nested-loop join).
Database System Concepts - 5th Edition, Aug 27, 2005.
13.21
©Silberschatz, Korth and Sudarshan
4. Indexed nested-loop join
If an index exists on customer for customer-name, then 10,000
block accesses to read deposit + 10,000 3 block accesses
( 2 for index block, 1 to read the customer tuple itself)
40,000 block accesses
Given a tuple d in deposit, it is no longer necessary to read the
entire customer relation. Instead, the index is used to look up
tuples in customer for which the customer-name value is
d[customer-name]. Only one tuples in customer table for which
d[c-name] = c[c-name] since c-name is a primary key for
customer.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.22
©Silberschatz, Korth and Sudarshan
5. Hash-Join
Hash Join :
A hash function h is used to hash tuples of both relations on the
basis of join attributes.
Let d be a tuple in deposit, c be a tuple in customer.
If h(c) ≠ h(d), then c & d must have different values for
customer-name. If h(c) = h(d), check.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.23
©Silberschatz, Korth and Sudarshan
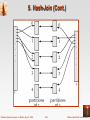
5. Hash-Join (Cont.)
h: customer-name
{ 0, 1, 2, .... , Max }
H c 0 , H c1 ,..., H c max
denote buckets of pointers to customer.
H d 0 , H d 1 ,..., H d max
denote buckets of pointers to deposit.
rd : the set of deposit tuples that hash to bucket i.
rc - the set of customer tuples that hash to bucket i.
rd
rc
Total 510(for hashing) + 510(perform rd
rc) = 1,020 block
accesses. Assume that deposit and customer tuples are stored
together physically, respectively.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.24
©Silberschatz, Korth and Sudarshan
5. Hash-Join (Cont.)
Database System Concepts - 5th Edition, Aug 27, 2005.
13.25
©Silberschatz, Korth and Sudarshan
Three-Way Join
Consider
branch(branch-name, assets, b-city)
deposit(branch-name, account-#, customer-name, balance)
customer(customer-name, c-st, c-city)
Consider
branch
Where
ndeposit
ncustomer
n branch
deposit
customer
= 10,000
= 200
= 50
Consider a choice of which join to compute first.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.26
©Silberschatz, Korth and Sudarshan
Three-Way Join
It is associative :
Estimation of the size of a natural join
Let r1 ( R1 ) and r2 (R2 ) be relations
① If
R1 R2
② If
R1 R2
then
is a key for
R1 ,
then the number of tuples is
(a tuple of
r2
the number of tuples in
will join with exactly one tuple from
r1 )
r2 .
Ex)
Database System Concepts - 5th Edition, Aug 27, 2005.
13.27
©Silberschatz, Korth and Sudarshan
Three-Way Join
Strategy 1.
① deposit
customer first
since c-name is a key for customer, at most 10,000 tuples.
② build an index an branch for b-name.
compute branch
(deposit
For each t ∈ deposit
customer)
customer, look up the tuple in
branch with a branch-name value of t[branch-name].
Since b-name is a key for branch, examine only one branch
tuples for each of 10,000 tuples in (deposit
customer).
※ If R1 ∩ R2 is a key for R1,
the # of tuple in r1
Database System Concepts - 5th Edition, Aug 27, 2005.
r2 ≤ the # of tuples in r2.
13.28
©Silberschatz, Korth and Sudarshan
Three-Way Join
Strategy 2.
50 * 10,000 * 200 possibilities, without constructing indices at all.
Strategy 3.
build two indices :
on branch for b-name.
on customer for c-name.
Consider each t ∈ deposit, look up the corresponding tuple in customer
and the corresponding tuple in branch.
Thus, we examine each tuple of deposit exactly once.
Database System Concepts - 5th Edition, Aug 27, 2005.
13.29
©Silberschatz, Korth and Sudarshan
End of Chapter 13
Database System Concepts, 5th Ed.
©Silberschatz, Korth and Sudarshan
See www.db-book.com for conditions on re-use