Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
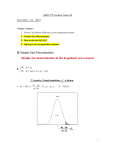
Enabling Knowledge Discovery in a Virtual Universe Harnessing the Power of Parallel Grid Resources for Astrophysical Data Analysis Jeffrey P. Gardner Andrew Connolly Cameron McBride Pittsburgh Supercomputing Center University of Pittsburgh Carnegie Mellon University How to turn simulation output into scientific knowledge Using 300 processors: (circa 1995) Step 1: Run simulation (happy scientist) Step 2: Analyze simulation on workstation Step 3: Extract meaningful scientific knowledge How to turn simulation output into scientific knowledge Using 1000 processors: (circa 2000) Step 1: Run simulation (happy scientist) Step 2: Analyze simulation on server (in serial) Step 3: Extract meaningful scientific knowledge How to turn simulation output into scientific knowledge Using 4000+ processors: (circa 2006) (unhappy scientist) X Step 1: Run simulation Step 2: Analyze simulation on ??? Mining the Universe can be (Computationally) Expensive The size of simulations is no longer limited by computational power It is limited by the parallelizability of data analysis tools This situation, will only get worse in the future. How to turn simulation output into scientific knowledge Using 100,000 processors?: (circa 2012) X Step 1: Run simulation Step 2: Analyze simulation on ??? By 2012, we will have machines that will have many hundreds of thousands of cores! The Challenge of Data Analysis in a Multiprocessor Universe Parallel programs are difficult to write! Parallel programs are expensive to write! Lengthy development time Parallel world is dominated by simulations: Steep learning curve to learn parallel programming Code is often reused for many years by many people Therefore, you can afford to invest lots of time writing the code. Example: GASOLINE (a cosmology N-body code) Required 10 FTE-years of development The Challenge of Data Analysis in a Multiprocessor Universe Data Analysis does not work this way: Rapidly changing scientific inqueries Less code reuse Simulation groups do not even write their analysis code in parallel! Data Mining paradigm mandates rapid software development! How to turn observational data into scientific knowledge (happy astronomer) Step 1: Collect data Step 2: Analyze data on workstation Step 3: Extract meaningful scientific knowledge The Era of Massive Sky Surveys Paradigm shift in astronomy: Sky Surveys Available data is growing at a much faster rate than computational power. Good News for “Data Parallel” Operations Data Parallel (or “Embarrassingly Parallel”): Example: 1,000,000 QSO spectra Each spectrum takes ~1 hour to reduce Each spectrum is computationally independent from the others There are many workflow management tools that will distribute your computations across many machines. Tightly-Coupled Parallelism (what this talk is about) Data and computational domains overlap Computational elements must communicate with one another Examples: Group finding N-Point correlation functions New object classification Density estimation The Challenge of Astrophysics Data Analysis in a Multiprocessor Universe Build a library that is: Sophisticated enough to take care of all of the nasty parallel bits for you. Flexible enough to be used for your own particular astrophysics data analysis application. Scalable: scales well to thousands of processors. The Challenge of Astrophysics Data Analysis in a Multiprocessor Universe Astrophysics uses dynamic, irregular data structures: Astronomy deals with point-like data in an N-dimensional parameter space Most efficient methods on these kind of data use spacepartitioning trees. The most common data structure is a kd-tree. Challenges for scalable parallel application development: Things that make parallel programs difficult to write Thread orchestration Data management Things that inhibit scalability: Granularity (synchronization) Load balancing Data locality Overview of existing paradigms: GSA There are existing globally shared address space (GSA) compilers and libraries: Co-Array Fortran UPC ZPL Global Arrays The Good: These are quite simple to use. The Good: Can manage data locality well. The Bad: Existing GSA approaches tend not to scale very well because of fine granularity. The Ugly: None of these support irregular data structures. Overview of existing paradigms: GSA There are other GSA approaches that do lend themselves to irregular data structures: e.g. Linda (tuple-space) The Good: Almost universally flexible The Bad: These tend not to scale even worse than the previous GSA approaches. Granularity is too fine Challenges for scalable parallel application development: Things that make parallel programs difficult to write GSA Thread orchestration Data management Things that inhibit scalability: Granularity Load balancing Data locality Overview of existing paradigms: RMI “Remote Method Invocation” rmi_broadcast(…, (*myFunction)); Computational Agenda Proc. 0 Master Thread RMI layer Proc. 1 Proc. 3 Proc. 2 RMI layer RMI Layer RMI Layer RMI Layer myFunction() myFunction() myFunction() myFunction() myFunction() is coarsely grained Challenges for scalable parallel application development: Things that make parallel programs difficult to write RMI Thread orchestration Data management Things that inhibit scalability: Granularity Load balancing Data locality N tropy: A Library for Rapid Development of kd-tree Applications No existing paradigm gives us everything we need. Can we combine existing paradigms beneath a simple, yet flexible API? N tropy: A Library for Rapid Development of kd-tree Applications Use RMI for orchestration Use GSA for data management A Simple N tropy Example: N-body Gravity Calculation Cosmological “N-Body” simulation •100,000,000 particles •1 TB of RAM Proc 0 Proc 1 Proc 2 Proc 3 Proc 4 Proc 5 Proc 6 Proc 7 Proc 8 100 million light years A Simple N tropy Example: N-body Gravity Calculation Computational Agenda ntropy_Dynamic(…, (*myGravityFunc)); Master Thread N tropy master layer Proc. 0 Proc. 1 Proc. 2 Proc. 3 N tropy thread N tropy thread N tropy thread N tropy thread myGravityFunc() myGravityFunc() myGravityFunc() myGravityFunc() service layer service layer service layer P1 P2 … service layer … Pn Particles on which to calculate gravitational force A Simple N tropy Example: N-body Gravity Calculation Cosmological “N-Body” simulation •100,000,000 particles •1 TB of RAM To resolve the gravitational force on any single particle requires the entire dataset Proc 0 Proc 1 Proc 2 Proc 3 Proc 4 Proc 5 Proc 6 Proc 7 Proc 8 100 million light years A Simple N tropy Example: N-body Gravity Calculation Proc. 0 Proc. 1 Proc. 2 Proc. 3 N tropy thread N tropy thread N tropy thread N tropy thread myGravityFunc() myGravityFunc() myGravityFunc() myGravityFunc() N tropy GSA layer N tropy GSA layer N tropy GSA layer service layer service layer service layer 0 1 8 2 3 5 4 6 9 7 10 12 11 13 14 service layer N tropy GSA layer N tropy Performance Features GSA allows performance features to be provided “under the hood”: Interprocessor data caching < 1 in 100,000 off-PE requests actually result in communication. RMI allows further performance features Dynamic load balacing Workload can be dynamically reallocated as computation progresses. N tropy Performance 10 million particles Spatial 3-Point 3->4 Mpc Interprocessor data cache, Load balancing Interprocessor data cache, No load balancing No interprocessor data cache, No load balancing Why does the data cache make such a huge difference? 0 Proc. 0 1 8 myGravityFunc() 2 3 5 4 6 9 7 10 12 11 13 14 N tropy “Meaningful” Benchmarks The purpose of this library is to minimize development time! Development time for: 1. Parallel N-point correlation function calculator 2. 2 years -> 3 months Parallel Friends-of-Friends group finder 8 months -> 3 weeks Conclusions Most approaches for parallel application development rely on a single paradigm Inhibits scalability Inhibits generality Almost all current HPC programs are written in MPI (“paradigm-less”): MPI is a “lowest common denominator” upon which any paradigm can be imposed. Conclusions Many “real-world” problems, especially those involving irregular data structures, demand a combination of paradigms N tropy provides: Remote Method Invocation (RMI) Globally Share Addressing (GSA) Conclusions Tools that selectively deploy several parallel paradigms (rather than just one) may be what are needed to parallelize applications that use irregular/adaptive/dynamic data structures. More Information: Go to Wikipedia and seach “Ntropy”