Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data Mining: What is All That Data
Telling Us?
Dave Dickey
NCSU Statistics
What I know
• What “they” can do
• How “they” can do it
What I don’t know
• What is some particular entity doing ?
• How safe is your particular information ?
• Is big brother watching me right now ?
* Data being created at lightning pace
* Moore’s law: (doubling / 2 years –
transistors on integrated circuits)
Internet “hits”
Scanner cards
e-mails
Intercepted messages
Credit scores
Environmental Monitoring
Satellite Images
Weather Data
Health & Birth Records
So we have some data – now
what??
•
•
•
•
•
•
•
Predict defaults, dropouts, etc.
Find buying patterns
Segment your market
Detect SPAM (or others)
Diagnose handwriting
Cluster
ANALYZE IT !!!!
Data Mining - What is it?
•
•
•
•
Large datasets
Fast methods
Not significance testing
Topics
–
–
–
–
–
Trees (recursive splitting)
Nearest Neighbor
Neural Networks
Clustering
Association Analysis
Trees
•
•
•
•
•
•
A “divisive” method (splits)
Start with “root node” – all in one group
Get splitting rules
Response often binary
Result is a “tree”
Example: Framingham Heart Study
Recursive Splitting
x x x x x xx x x x x x x xx x x x x x x x xxx x x
x x xxx D x x x x xxx
x
x xx
x x x
x x x x D x x x x xx x x x D x x x x x x x x
x x x x
x x xx x D x
x x
x x
x xx
x x x
x x x
x x xD x x x
x D xx
x x x x x x xx D xx x x x xx x x
x
xx x
x x x x
x x x x x x x x xxx x x x x x x x x x x x x x x D x x x xx x x D x x x x x x x x x x x x x x x
X x x x x x x x x x x x x x xD x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x x
Dx
x xx xx x xxx xxx xx xx xx xxx x xxx x x x x x xx x
xxx
DD x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x
x x x x x xx x x x x x x xx x x x x x x x xxx x x D x x x x x
x x x x xxx
x
x xx
x x x
x x x x x x x x xx x x x x x x x x x x x
x x x x
x x xx x
x
x x
x x
x xx
x x x
x x x
xx D
x
x x x x x x x x
x
xx
x x x x x x x x
xx x x x xx x x
x
xxx
x
xx x
x x x x
x x x x x x x x xxx x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x
X x xxxDx xx x xxx x xx
xx xx x x xxxx xxx xxx xxx xxx x xxx xx x x x x
xx
x xx xx x xxx xxx xx xx xx xxx x xxx x x x x x xx x
x x xx x x x xx x x x x xxx xx
x xx xxx xxx xx xx xxxx
x xx x x xx xx
x x xxxx x x xx x xxx xx xx xx xx x x xx x xx xx x x x xx x xx xx x x
x x x x x x x x xx x x x x x x x x x x x
x x x x
x x xx x
x
x x
x x
x xx
x x x
x x x
x
x
x xx
x
x x x x x x
x
xx
x x x x x x x x
xx x x x xx x x
x x xx x x x
xx x
x x x x
x x x x x x x x xxx x x x x x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x D
X x xxx x xx x xxx x xx
xx xx x x xxxx xxx xxx xxx xxx x xxx xx x x x x
xx
x xx xx x xxx xxx xx xx xx xxx x xxx x x x x x xx x
xxx
D
D
x x x x x x x x x x x x x xx x x x x x x x x x x x x x x x x x x x x x x x x x x x
Pr{default} =0.007
Pr{default} =0.012
Pr{default} =0.006
X1=Debt
To
Income
Ratio
Pr{default} =0.0001
Pr{default} =0.003
X2 = Age
Some Actual Data
• Framingham Heart
Study
• First Stage Coronary
Heart Disease
– P{CHD} = Function of:
• Age - no drug yet!
• Cholesterol
• Systolic BP
Import
Example of a “tree”
All 1615 patients
Split # 1: Age
Systolic BP
“terminal node”
How to make splits?
• Which variable to use?
• Where to split?
– Cholesterol > ____
– Systolic BP > _____
• Goal: Pure “leaves” or “terminal nodes”
• Ideal split: Everyone with BP>x has problems,
nobody with BP<x has problems
Where to Split?
• Maximize “dependence” statistically
• We use “contingency tables”
Heart Disease
No
Yes
Low
BP
High
BP
Heart Disease
No
Yes
95
5
100
75
25
55
45
100
75
25
DEPENDENT
INDEPENDENT
Measuring Dependence
• Expect 100(150/200)=75 in upper left if
independent (etc. e.g. 100(50/200)=25)
Heart Disease
No
Yes
Low
BP
High
BP
95
(75)
55
(75)
5
(25)
45
(25)
150
50
100
100
200
How far from expectations is “too far” (significant dependence)
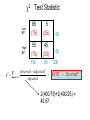
c2 Test Statistic
Low
BP
95
(75)
5
(25)
High
BP
55
(75)
45
(25)
100
150
50
200
100
(observed exp ected ) 2
c allcells
42.67
exp ected
2
- So what?
2(400/75)+2(400/25) =
42.67
Use Probability!
“P-value”
“Significance Level” (0.05)
Measuring “Worth” of a Split
• P-value is probability of c2 as great as that
observed if independence is true.
• (Pr {c2>42.67} is 0.000000000064
• P-values all too small to understand.
• Logworth = -log10(p-value) = 10.19
• Best Chi-square max logworth.
Logworth for Age Splits
Age 47 maximizes logworth
How to make splits?
• Which variable to use?
• Where to split?
– Cholesterol > ____
– Systolic BP > _____
• Idea – Pick BP cutoff to minimize p-value
for c2
• What does “signifiance” mean now?
Multiple testing
• 50 different BPs in data, 49 ways to split
• Sunday football highlights always look
good!
• If he shoots enough baskets, even 95%
free throw shooter will miss.
• Tried 49 splits, each has 5% chance of
declaring significance even if there’s no
relationship.
Multiple testing
a=
Pr{ falsely reject hypothesis 2}
a=
Pr{ falsely reject hypothesis 1}
Pr{ falsely reject one or the other} < 2a
Desired: 0.05 probabilty or less
Solution: use a = 0.05/2
Or – compare 2a to 0.05
Multiple testing
• 50 different BPs in data, m=49 ways to split
• Multiply p-value by 49
• Stop splitting if minimum p-value is large
(logworth is small).
• For m splits, logworth becomes
-log10(m*p-value)
Other Split Evaluations
• Gini Diversity Index
– { E E E E G E G G L G}
– Pick 2, Pr{different} =
• 1-Pr{EE}-Pr{GG}-Pr{LL}
• 1- [ 10 + 6 + 0]/45 =29/45=0.64
– {EEGLGEEGLL}
• 1-[6+3+3]/45 = 33/45 = 0.73
• MORE DIVERSE, LESS PURE
• Shannon Entropy
– Larger more diverse (less pure)
–
-Si pi log2(pi)
{0.5, 0.4, 0.1} 1.36
{0.4, 0.2, 0.3} 1.51
(more diverse)
Goals
• Split if diversity in parent “node” > summed
diversities in child nodes
• Observations should be
– Homogeneous (not diverse) within leaves
– Different between leaves
– Leaves should be diverse
• Framingham tree used Gini for splits
Cross validation
• Traditional stats – small dataset, need all
observations to estimate parameters of
interest.
• Data mining – loads of data, can afford
“holdout sample”
• Variation: n-fold cross validation
– Randomly divide data into n sets
– Estimate on n-1, validate on 1
– Repeat n times, using each set as holdout.
Pruning
• Grow bushy tree on the “fit data”
• Classify holdout data
• Likely farthest out branches do not improve,
possibly hurt fit on holdout data
• Prune non-helpful branches.
• What is “helpful”? What is good discriminator
criterion?
Goals
• Want diversity in parent “node”
> summed diversities in child nodes
• Goal is to reduce diversity within leaves
• Goal is to maximize differences between leaves
• Use same evaluation criteria as for splits
• Costs (profits) may enter the picture for splitting or
evaluation.
Accounting for Costs
• Pardon me (sir, ma’am) can you spare some
change?
• Say “sir” to male +$2.00
• Say “ma’am” to female +$5.00
• Say “sir” to female -$1.00 (balm for slapped
face)
• Say “ma’am” to male -$10.00 (nose splint)
Including Probabilities
Leaf has Pr(M)=.7, Pr(F)=.3.
You say:
M
F
True
Gender
M
0.7 (2)
0.7 (-10)
0.3 (5)
F
Expected profit is 2(0.7)-1(0.3) = $1.10 if I say “sir”
Expected profit is -7+1.5 = -$5.50 (a loss) if I say “Ma’am”
Weight leaf profits by leaf size (# obsns.) and sum
Prune (and split) to maximize profits.
Additional Ideas
• Forests – Draw samples with replacement
(bootstrap) and grow multiple trees.
• Random Forests – Randomly sample the
“features” (predictors) and build multiple
trees.
• Classify new point in each tree then
average the probabilities, or take a
plurality vote from the trees
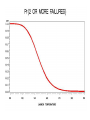
* Lift Chart
- Go from leaf of most to least response.
- Lift is cumulative proportion responding.
Regression Trees
• Continuous response (not just class)
• Predicted response constant in regions
Predict 80
Predict 50
X2
{47, 51, 57, 45}
50 = mean
Predict
130
Predict 100
X1
Predict
20
•
•
•
•
Predict Pi in cell i (it’s cell mean)
Yij jth response in cell i.
Split to minimize Si Sj (Yij-Pi)2
[sum of squared deviations from cell mean]
Predict 50
{-3, 1, 7, -5}
SSq=9+1+49+25
= 84
Predict 100
Predict 80
Predict
130
Predict
20
• Predict Pi in cell i.
• Yij jth response in cell i.
• Split to minimize Si Sj (Yij-Pi)2
Logistic Regression
• Logistic – another classifier
• Older – “tried & true” method
• Predict probability of response from input
variables (“Features”)
• Need to insure 0 < probability < 1
Example:
Shuttle Missions
•
•
•
•
•
O-rings failed in Challenger disaster
Low temperature
Prior flights “erosion” and “blowby” in O-rings
Feature: Temperature at liftoff
Target: problem (1) - erosion or blowby vs. no
problem (0)
•
•
•
•
•
We can easily “fit” lines
Lines exceed 1 ,
fall below 0
Model L as linear in temperature
L = a+b(temp)
Convert: p = eL/(1+eL) =
ea+b(temp)/ (1+ea+b(temp))
Convert
Example: Ignition
• Flame exposure time = X
• Ignited Y=1, did not ignite Y=0
– Y=0, X= 3, 5, 9 10 ,
13,
16
– Y=1, X =
11, 12 14, 15, 17, 25, 30
•
•
•
•
Probability of our data is “Q”
Q=(1-p)(1-p)(1-p)(1-p)pp(1-p)pp(1-p)ppp
P’s all different p=f(exposure)
Find a,b to maximize Q(a,b)
Likelihood function (Q)
-2.6
0.23
IGNITION DATA
The LOGISTIC Procedure
Analysis of Maximum Likelihood Estimates
Parameter
Intercept
TIME
DF
1
1
Estimate
-2.5879
0.2346
Standard
Error
1.8469
0.1502
Wald
Chi-Square
1.9633
2.4388
Pr > ChiSq
0.1612
0.1184
Association of Predicted Probabilities and Observed Responses
Percent Concordant
Percent Discordant
Percent Tied
Pairs
79.2
20.8
0.0
48
Somers' D
Gamma
Tau-a
c
0.583
0.583
0.308
0.792
4 right,
1 wrong
5 right,
4 wrong
Example: Framingham
• X=age
• Y=1 if heart trouble, 0 otherwise
Framingham
The LOGISTIC Procedure
Analysis of Maximum Likelihood Estimates
Parameter
DF
Intercept
age
1
1
Standard
Wald
Estimate
Error Chi-Square
-5.4639
0.0630
0.5563
0.0110
96.4711
32.6152
Pr>ChiSq
<.0001
<.0001
Neural Networks
• Very flexible functions
• “Hidden Layers”
• “Multilayer Perceptron”
output
inputs
Logistic function of
Logistic functions
Of data
Arrows represent linear
combinations of “basis
functions,” e.g. logistics
b1
Example:
Y = a + b1 p1 + b2 p2 + b3 p3
Y = 4 + p1+ 2 p2 - 4 p3
• Should always use holdout sample
• Perturb coefficients to optimize fit (fit data)
• Eliminate unnecessary arrows using holdout data.
Terms
•
•
•
•
•
•
•
Train: estimate coefficients
Bias: intercept a in Neural Nets
Weights: coefficients b
Radial Basis Function: Normal density
Score: Predict (usually Y from new Xs)
Activation Function: transformation to target
Supervised Learning: Training data has
response.
Hidden Layer
L1 = -1.87 - .27*Age – 0.20*SBP22
H11=exp(L1)/(1+exp(L1))
L2 = -20.76 -21.38*H11
Pr{first_chd} = exp(L2)/(1+exp(L2))
“Activation Function”
Unsupervised Learning
• We have the “features” (predictors)
• We do NOT have the response even on a
training data set (UNsupervised)
• Clustering
– Agglomerative
• Start with each point separated
– Divisive
• Start with all points in one cluster then spilt
Clustering – political (hypothetical)
•
•
•
•
•
300 people: “mark line to indicate concern”:
<-5> ---------0-------------- <+5>
X1: economy
X2: war in Iraq
X3: health care
• 1st person (2.2 -3.1 0.9)
• 2nd person (-1.6 1 0.6)
• Etc.
Clusters as Created
As Clustered
Association Analysis
• Market basket analysis
– What they’re doing when they scan your “VIP”
card at the grocery
– People who buy diapers tend to also buy
_________ (beer?)
– Just a matter of accounting but with new
terminology (of course )
– Examples from SAS Appl. DM Techniques, by
Sue Walsh:
Termnilogy
• Baskets: ABC
•
•
•
•
•
ACD
BCD
ADE
Rule
Support
Confidence
X=>Y Pr{X and Y} Pr{Y|X}
A => D
2/5
2/3
C => A
2/5
2/4
B&C => D
1/5
1/3
BCE
Don’t be Fooled!
• Lift = Confidence /Expected Confidence if Independent
Checking->
Saving V
No
(1500)
Yes
(8500)
(10000)
No
500
3500
4000
Yes
1000
5000
6000
SVG=>CHKG Expect 8500/10000 = 85% if independent
Observed Confidence is 5000/6000 = 83%
Lift = 83/85 < 1.
Savings account holders actually LESS likely than others to
have checking account !!!
Summary
• Data mining – a set of fast stat methods for
large data sets
• Some new ideas, many old or extensions of old
• Some methods:
– Decision Trees
– Nearest Neighbor
– Neural Nets
– Clustering
– Association