Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
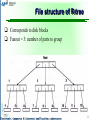
Special Topics in Computer Science Advanced Topics in Information Retrieval Lecture 6 (book chapter 12): Multimedia IR: Indexing and Searching Alexander Gelbukh www.Gelbukh.com Previous Chapter: Conclusions Basically, images are handled as text described them Namely, feature vectors (or feature hierarchies) Context can be used when available to determine features Also, queries by example are common From the point of view of DBMS, integration with IR and multimedia-specific techniques is needed Object-oriented technology is adequate 2 Previous Chapter: Research topics How similarity function can be defined? What features of images (video, sound) there are? How to better specify the importance of individual features? (Give me similar houses: similar = size? color? strructure? Architectural style?) How to determine the objects in an image? Integration with DBMSs and SQL for fast access and rich semantics Integration with XML Ranking: by similarity, taking into account history, profile 3 The problem Data examples: 2D/3D color/grayscale images: e.g., brain scans, scientific databases of vector fields (2D) video, (1D) voice/music; (1D) time series: e.g., financial/marketing time series; DNA/genomic databases Query examples: find photographs with the same color distribution as this find companies whose stock prices move as this one find brain scans with a texture of a tumor Applications: search; data mining 4 Solution Reduce the problem to search for multi-dimensional points (feature vectors, but vector space is not used) Define a distance measure for time series: e.g., Euclidean distance between vectors for images: e.g., color distribution (Euclidean distance); another approach: mathematical morphology Other features as vectors For search within distance, the vectors are organized in R-trees Clustering plays important role 5 Types of queries All within given distance Find all images that are within 0.05 distance from this one Nearest-neighbor Find 5 stocks most similar to IBM All pairs within given distance Further: clustering Whole object vs. sub-pattern match Find parts of image that are... E.g., in 512 512 brain scans, find pieces similar to the given 16 16 typical X-ray of a tumor Like passage retrieval for text documents 6 Neighbor and pairs types of queries The objects are organized in R-trees For neighbor queries: branch-and-bound algorithm For pairs: recently discovered algorithms These types of queries are not discussed here 7 Desiderata for a method Fast No sequential search with all objects Correct 100% recall Precision is less important, though kept low. False alarms are easy to discard manually Little space overhead Dynamic easy to insert, delete, update 8 Types of methods Linear quadtrees Complexity = hypersurface of the query region Grows exponentially with dimensionality grid-files Complexity grows exponentially with dimensionality R-trees methods, such as R*-trees Most used due to lower complexity 9 R-tree Objects and parts of images represented as Minimal Bounding Rectangle (MBR) Can overlap for different objects Larger objects contain smaller objects MBRs are nested MBRs are arranged into a tree In storage, an index of disk blocks is maintained Disk blocks are fetched at once at hardware level For better insertion/deletion, tight MBRs are needed Good clustering is needed 10 File structure of R-tree Corresponds to disk blocks Fanout = 3: number of parts to group 11 R-tree R-tree 12 Search in R-tree Range queries: find objects within distance from query object = Find MBRs that intersect with query’s MBR Determine MBR of the query Descend the tree Discarding all MBRs that do not intersect with the query’s MBR Many variations of R-tree method have been proposed 13 Indexing Only consider here whole match queries Given collection of objects and distance function Find objects within given distance from given object Q Problems: 1. Slow comparison of two objects 2. Huge database GEMINI approach GEneric Multimedia object INdexIng Attempts to solve both problems 14 GEMINI indexing Quick-and-dirty test to quickly discard bad objects Uses clusters to avoid sequential search Quick test Single-valued feature, e.g., average for series. Averages differ much objects differ much Not vice-versa. False alarms are OK Several features, but fewer than all data. E.g., deviation for series 15 Algorithm Map the actual objects into f-dimensional feature space Use clusters (e.g., R-trees) to search Retrieve objects, compute the actual distances, and discard false alarms 16 17 Feature selection Features should reflect distances Allow no misses (100% recall) features should make things look closer Lower Bound lemma: If distance in feature space actual distance then 100% recall (we speak about whole-match queries) Holds for distance search, nearest-neighbor, pair search 18 Algorithm (more detail) Determine distance Choose features Prove that distance in feature space for actual objects Use quick method (R-tree) to search in feature space For found objects, compute the actual distances (this can be expensive) Discard false alarms objects with greater actual distances, even if in feature space the distance is OK Example: similar averages, but different series 19 Discussion The method does NOT improve quality Provides SAME quality as sequential search, but faster Distance definition requires domain/application expert How much do the two images differ? What is important/unimportant for the specific application? Feature selection requires a good knowledge engineer Choose the most characteristic feature: discriminative If needed, choose the second best, etc. Good features should be orthogonal: combination adds info 20 Example: Time series In yearly stock movements, find ones similar to IBM Distance: Euclidean (365-D vectors); others exist Features: First feature is average. If needed, Discrete Fourier Transform (DFT) coefficients Or, Discrete Cosine Transform, waivelet Transform, etc. Lower-bound lemma: Parseval theorem: DFT preserves distances (DCT, WT too) First several coefficients give distance Transforms “concentrate energy” in the first coefficients Thus, the more realistic prediction of distance 21 Time series: Applications Such feature selection is effective for many skewed spectrum distributions Colored noises: the energy decreases as F–b b = 0: white spectrum: unpredictable. Method useless. b = 1: pink noise: works of art b = 2: brown noise: stock movements b > 2: black noise: river levels, rainfall patterns The greater b the better the first coefficients of the transform predict the actual distance Some other n-D signals show similar properties JPEG compression ignores higher coefficients 22 Time series: Performance Fewer features more false alarms time lost More features more complex computation Optimal number of features proves to be about 1..3 for skewed enough distributions JPEG compression shows that photographs have it 23 Time series: Sub-pattern search Use sliding window Encode each window with few features 24 Example: Color images Give me images with a texture of tumor like this one Give me images with blue at top and red at bottom Handles color, texture, shape, position, dominant edges 25 Color images: Color representation Compute color histogram Distance: use color similarity matrix Very expensive computationally: cross-talk between features (compare all to all features) 26 27 Color images: Feature mapping The GEMINI question again: What single feature is the most representative? Take average R, G, B Lower-bound? Yes: Quadratic Distance Bounding theorem 28 Automatic feature selection Features can be selected automatically In texts: Latent semantic indexing (LSI) Many methods Principle components analysis (= LSI), ... In fact, they can reduce features, but not define them Of colors, one can select characteristic combinations But not classify into faces and flowers So description of the objects is still on human researchers 29 Research topics Object detection (pattern and image recognition) Automatic feature selection Spatial indexing data structures (more than 1D) New types of data. What features to select? How to determine them? Mixed-type data (e.g., webpages, or images with sound and description) What clustering/IR methods are better suited for what features? (What features for what methods?) Similar methods in data mining, ... 30 Conclusions How to accelerate search? Same results as sequential Ideas: Quick-and-dirty rejection of bad objects, 100% recall Fast data structure for search (based on clustering) Careful check of all found candidates Solution: mapping into fewer-D feature space Condition: lower-bounding of the distance Assumption: skewed spectrum distribution Few coefficients concentrate energy, rest are less important 31 Thank you! Till Tuesday 11, 6 pm 32