Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
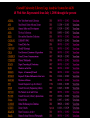
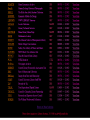
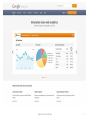
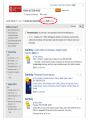
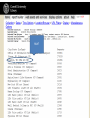
There are interesting reports in the CUL bibliomining system (logs.library.cornell.edu) Adam Chandler Electronic Resources User Experience Librarian Library Technical Services CUL Reference & Outreach Forum Cornell University Library October 9, 2012 http://logs.library.cornell.edu logs.library.cornell.edu 2 What is it? logs.library.cornell.edu 3 logs.library.cornell.edu 4 logs.library.cornell.edu 5 Why bother? Just use Google Analytics logs.library.cornell.edu 6 logs.library.cornell.edu 7 Why not Google Analytics? Because logs.library.cornell.edu … 1. 2. 3. 4. 5. Uses Cornell single sign for security and convenience gives us the freedom to export and use the data anyway we want for our special reporting needs requires no changes to our websites. Google Analytics requires a section of Javascript code that sends information about each request to Google where it is recorded. Repeated privacy violations from commercial sites such as Facebook are driving some users towards widgets such as ghostery (http://news.ghostery.com/) that block javascript based web tracking. our flexible design allows us to store logs which cannot easily be tracked with javascript: examples: PURL, checkip, flickr Patron Privacy logs.library.cornell.edu 8 'bibliomining' Nicholson, S. (2003) The Bibliomining Process: Data Warehousing and Data Mining for Library Decision-Making. Information Technology and Libraries 22 (4) logs.library.cornell.edu 9 “The term 'bibliomining' was first used by Nicholson and Stanton (2003) in discussing data mining for libraries. In the research literature, most works that contain the terms 'library' and 'data mining' are not talking about traditional library data, but rather using library in the context of software libraries, as data mining is the application of techniques from a large library of tools… The term pays homage to bibliometrics, which is the science of pattern discovery in scientific communication.” logs.library.cornell.edu 10 logs.library.cornell.edu 11 logs.library.cornell.edu 12 “The bibliomining process consists of · determining areas of focus; · identifying internal and external data sources; · collecting, cleaning, and anonymizing the data into a data warehouse; · selecting appropriate analysis tools; · discovery of patterns through data mining and creation of reports with traditional analytical tools; and · analyzing and implementing the results.” logs.library.cornell.edu 13 Nicholson, S. (2003) The Bibliomining Process: Data Warehousing and Data Mining for Library Decision-Making. Information Technology and Libraries 22 (4) logs.library.cornell.edu 14 Apache Log logs.library.cornell.edu 16 Apache Log logs.library.cornell.edu 17 CUL Logs IP Address Groups CU (Weill) CU (Qatar) Ithaca not CU CU Lib (Public) CU (Campus) CU Lib (Staff) NY not Ithaca USA not NY Overseas logs.library.cornell.edu 18 logs.library.cornell.edu 19 E-usage Analysis Task Force This group is called together for a 4 month project to survey all existing data sources and questions they could answer by themselves or in some combination about the use of CUL’s digital services and electronic and print collections. The nature of the work is a broad survey, rather than detailed analysis of any one specific area. The priority of the group is creating an inventory of electronic resource usage streams (80% of effort), but print usage data should also be summarized (20% of effort) so as to provide a comprehensive picture across CUL. logs.library.cornell.edu 20 E-usage Analysis Task Force The goal is to better equip CUL to assess our investment in eresources and e-services, such as : • What does our data tell about disciplinary use, strengths and weaknesses? (The ability to add demographic understanding of the use of our resources) • How do we tell we are making the right types of investments in collections? (The ability to have cost per use data on the title level for, e.g., collection development or cancellation projects) • How do we tell we are making the right types of investment in digital services in support of electronic and other resources? logs.library.cornell.edu 21 E-usage Analysis Task Force The goal is to better equip CUL to assess our investment in eresources and e-services, such as : • What does our data tell about disciplinary use, strengths and weaknesses? (The ability to add demographic understanding of the use of our resources) • How do we tell we are making the right types of investments in collections? (The ability to have cost per use data on the title level for, e.g., collection development or cancellation projects) • How do we tell we are making the right types of investment in digital services in support of electronic and other resources? logs.library.cornell.edu 22 E-usage Analysis Task Force The goal is to better equip CUL to assess our investment in eresources and e-services, such as : • What does our data tell about disciplinary use, strengths and weaknesses? (The ability to add demographic understanding of the use of our resources) • How do we tell we are making the right types of investments in collections? (The ability to have cost per use data on the title level for, e.g., collection development or cancellation projects) • How do we tell we are making the right types of investment in digital services in support of electronic and other resources? logs.library.cornell.edu 23 E-usage Analysis Task Force Xin Li, Dean Krafft, and John Saylor will serve as sponsors and resource to the team to support their work. Membership: • Adam Chandler (E-Resources User Experience Librarian – Chair) • Rich Entlich (Collection Development) • Zsuzsa Koltay (Assessment & Communication) • Mary Beth Martini-Lyons (IT and Usability) • Liisa Mobley (LTS). Report due January 31, 2013 logs.library.cornell.edu 24 Some interesting reports from logs.library.cornell.edu logs.library.cornell.edu 25 CUL’s DLXS digital collections logs.library.cornell.edu 26 logs.library.cornell.edu 27 logs.library.cornell.edu 28 Library website search boxes logs.library.cornell.edu 29 logs.library.cornell.edu 30 logs.library.cornell.edu 31 logs.library.cornell.edu 32 logs.library.cornell.edu 33 OpenURL Sources logs.library.cornell.edu 34 logs.library.cornell.edu 35 Licensed E-Resources via Checkip logs.library.cornell.edu 36 logs.library.cornell.edu 37 logs.library.cornell.edu 38 logs.library.cornell.edu 39 logs.library.cornell.edu 40 Huh? logs.library.cornell.edu 41 Huh? “The process is cyclical in nature: as patterns are discovered, more questions will be raised which will start the process again. As additional areas of the library are explored, the data warehouse will become more complete, which will make the exploration of other issues much easier.” – Scott Nicholson logs.library.cornell.edu 42 logs.library.cornell.edu logs.library.cornell.edu 43