Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Practical Graph Mining with R
Graph-based Proximity Measures
Nagiza F. Samatova
William Hendrix
John Jenkins
Kanchana Padmanabhan
Arpan Chakraborty
Department of Computer Science
North Carolina State University
Outline
• Defining Proximity Measures
• Neumann Kernels
• Shared Nearest Neighbor
2
Similarity and Dissimilarity
• Similarity
–
–
–
–
Numerical measure of how alike two data objects are.
Is higher when objects are more alike.
Often falls in the range [0,1]:
Examples: Cosine, Jaccard, Tanimoto,
• Dissimilarity
–
–
–
–
Numerical measure of how different two data objects are
Lower when objects are more alike
Minimum dissimilarity is often 0
Upper limit varies
• Proximity refers to a similarity or dissimilarity
Src: “Introduction to Data Mining” by Vipin Kumar et al
3
Distance Metric
•
Distance d (p, q) between two points p and q is a
dissimilarity measure if it satisfies:
1. Positive definiteness:
d (p, q) 0 for all p and q and
d (p, q) = 0 only if p = q.
2. Symmetry: d (p, q) = d (q, p) for all p and q.
3. Triangle Inequality:
d (p, r) d (p, q) + d (q, r) for all points p, q, and r.
•
Examples:
–
–
–
Euclidean distance
Minkowski distance
Mahalanobis distance
Src: “Introduction to Data Mining” by Vipin Kumar et al
4
Is this a distance metric?
p ( p1 , p2 ,...., pd )
d ( p, q) max( p j , q j )
d
and q (q1 , q2 ,...., qd )
d
Not: Positive definite
1 j d
Not: Symmetric
d ( p, q) max( p j q j )
1 j d
d ( p, q )
Not: Triangle Inequality
d
2
(
p
q
)
j j
j 1
d ( p, q) min | p j q j |
1 j d
Distance Metric
5
Distance: Euclidean, Minkowski, Mahalanobis
p ( p1 , p2 ,...., pd )
d ( p, q )
( p
j 1
j
and q (q1 , q2 ,...., qd )
Minkowski
Euclidean
d
d
qj )
2
d
r
d r ( p, q ) | p j q j |
j 1
d
Mahalanobis
1
r
d ( p, q) ( p q)1 ( p q)T
r 1:
City block distance
Manhattan distance
L1 -norm
r 2:
Euclidean, L2 -norm
6
Euclidean Distance
d ( p, q )
d
2
(
p
q
)
j j
j 1
Standardization is necessary, if scales differ.
p ( p1 , p2 ,...., pd )
Mean of attributes
1 d
p pk
d k 1
d
Ex:
p (age, salary )
Standard deviation of attributes
1 d
2
sp
(
p
p
)
k
d 1 k 1
Standardized/Normalized Vector
pnew
pd p
p1 p p2 p
p p
(
,
,...,
)
sp
sp
sp
sp
d
pnew 0
s pnew 1
7
Distance Matrix
d ( p, q )
d
2
(
p
q
)
j j
j 1
• P = as.matrix (read.table(file=“points.dat”));
• D = dist (P[, 2;3], method = "euclidean");
• L1 = dist (P[, 2;3], method = “minkowski", p=1);
• help (dist)
3
Input Data Table: P
point
p1
p2
p3
p4
p1
2
p3
p4
1
p2
0
0
1
2
3
4
5
6
x
0
2
3
5
y
2
0
1
1
File name: points.dat
Output Distance Matrix: D
p1
p1
p2
p3
p4
0
2.828
3.162
5.099
Src: “Introduction to Data Mining” by Vipin Kumar et al
p2
2.828
0
1.414
3.162
p3
3.162
1.414
0
2
p4
5.099
3.162
2
0
8
Covariance of Two Vectors, cov(p,q)
p ( p1 , p2 ,...., pd )
d
and q (q1 , q2 ,...., qd )
One definition:
cov( p, q) s pq
d
Mean of attributes
1 d
( pk p )(qk q )
d 1 k 1
1 d
p pk
d k 1
Or a better definition:
cov( p, q) E[( p E ( p))(q E (q))T ]
E is the Expected values of a random variable.
9
Covariance, or Dispersion Matrix,
N points in d-dimensional space:
P1 ( p11 , p12 ,...., p1d )
d
.....
PN ( pN 1 , pN 2 ,...., pNd )
d
The covariance, or dispersion matrix:
cov( P1 , P1 ) cov( P1 , P2 )
cov( P , P ) cov( P , P )
2
1
2
2
( P1 , P2 ,..., PN )
...
...
cov( PN , P1 ) cov( PN , P2 )
... cov( P1 , PN )
... cov( P2 , PN )
...
...
... cov( PN , PN )
The inverse, Σ-1, is concentration matrix or precision matrix
10
Common Properties of a Similarity
• Similarities, also have some well known
properties.
– s(p, q) = 1 (or maximum similarity) only if p = q.
– s(p, q) = s(q, p) for all p and q. (Symmetry)
where s(p, q) is the similarity between points
(data objects), p and q.
Src: “Introduction to Data Mining” by Vipin Kumar et al
11
Similarity Between Binary Vectors
• Suppose p and q have only binary attributes
• Compute similarities using the following quantities
– M01 = the number of attributes where p was 0 and q was 1
– M10 = the number of attributes where p was 1 and q was 0
– M00 = the number of attributes where p was 0 and q was 0
– M11 = the number of attributes where p was 1 and q was 1
• Simple Matching and Jaccard Coefficients:
SMC = number of matches / number of attributes
= (M11 + M00) / (M01 + M10 + M11 + M00)
J = number of 11 matches / number of not-both-zero
attributes values
= (M11) / (M01 + M10 + M11)
Src: “Introduction to Data Mining” by Vipin Kumar et al
12
SMC versus Jaccard: Example
p= 1000000000
q= 0000001001
M01 = 2 (the number of attributes where p was 0 and q was 1)
M10 = 1 (the number of attributes where p was 1 and q was 0)
M00 = 7 (the number of attributes where p was 0 and q was 0)
M11 = 0 (the number of attributes where p was 1 and q was 1)
SMC = (M11 + M00)/(M01 + M10 + M11 + M00)
= (0+7) / (2+1+0+7) = 0.7
J = (M11) / (M01 + M10 + M11) = 0 / (2 + 1 + 0) = 0
13
Cosine Similarity
• If d1 and d2 are two document vectors, then
cos( d1, d2 ) = (d1 d2) / ||d1|| ||d2|| , where:
indicates vector dot product and
|| d || is the length of vector d.
• Example:
d1 = 3 2 0 5 0 0 0 2 0 0
d2 = 1 0 0 0 0 0 0 1 0 2
cos( d1, d2 ) = .3150
d1 d2= 3*1 + 2*0 + 0*0 + 5*0 + 0*0 + 0*0 + 0*0 + 2*1 + 0*0 + 0*2 = 5
||d1|| = (3*3+2*2+0*0+5*5+0*0+0*0+0*0+2*2+0*0+0*0)0.5 = (42) 0.5 = 6.481
||d2|| = (1*1+0*0+0*0+0*0+0*0+0*0+0*0+1*1+0*0+2*2) 0.5 = (6) 0.5 = 2.245
Src: “Introduction to Data Mining” by Vipin Kumar et al
14
Extended Jaccard Coefficient (Tanimoto)
• Variation of Jaccard for continuous or count
attributes
– Reduces to Jaccard for binary attributes
Src: “Introduction to Data Mining” by Vipin Kumar et al
15
Correlation (Pearson Correlation)
• Correlation measures the linear relationship
between objects
• To compute correlation, we standardize data
objects, p and q, and then take their dot product
pk ( pk mean( p)) / std ( p)
qk (qk mean(q)) / std (q)
correlation( p, q) p q
Src: “Introduction to Data Mining” by Vipin Kumar et al
16
Visually Evaluating Correlation
Scatter plots showing the
similarity from –1 to 1.
Src: “Introduction to Data Mining” by Vipin Kumar et al
17
General Approach for Combining Similarities
•
Sometimes attributes are of many different
types, but an overall similarity is needed.
Src: “Introduction to Data Mining” by Vipin Kumar et al
18
Using Weights to Combine Similarities
• May not want to treat all attributes the same.
– Use weights wk which are between 0 and 1 and sum to 1.
Src: “Introduction to Data Mining” by Vipin Kumar et al
19
Graph-Based Proximity Measures
In order to apply graphbased data mining
techniques, such as
classification and clustering,
it is necessary to define
proximity measures between
data represented in graph
form.
Within-graph
proximity measures:
Hyperlink-Induced
Topic Search (HITS)
The Neumann
Kernel
Shared Nearest
Neighbor (SNN)
√
Outline
• Defining Proximity Measures
• Neumann Kernels
• Shared Nearest Neighbor
21
Neumann Kernels: Agenda
Neumann
Kernel
Introduction
Co-citation and
Bibliographic
Coupling
Document and
Term
Correlation
Diffusion/Decay
factors
Relationship to
HITS
Strengths and
Weaknesses
Neumann Kernels (NK)
Generalization of HITS
Input: Undirected or Directed
Graph
Output: Within Graph
Proximity Measure
Importance
Relatedness
von Neumann
NK: Citation graph
n1
n2
n3
n4
n5
n6
n7
n8
• Input: Graph
– n1…n8 vertices (articles)
– Graph is directed
– Edges indicate a citation
• Citation Matrix C can be formed
– If an edge between two vertices exists then the
matrix cell = 1 else = 0
NK: Co-citation graph
n1
n5
n2
n6
n3
n4
n7
n8
• Co-citation graph: A graph which has two nodes
connected if they appear simultaneously in the reference
list of a third node in citation graph.
• In above graph n1 and n2 are connected because
both are referenced by same node n5 in citation
graph
• CC=CTC
NK: Bibliographic Coupling Graph
n1
n5
n2
n6
n3
n4
n7
n8
Bibliographic coupling graph: A graph which has two nodes
connected if they share one or more bibliographic references.
In above graph n5 and n6 are connected because both are
referencing same node n2 in citation graph
CC=C CT
NK: Document and Term Correlation
Term-document matrix: A matrix in which the rows represent
terms, columns represent documents, and entries represent a function
of their relationship
(e.g. frequency of the given term in the document).
Example:
D1: “I like this book”
D2: “We wrote this book”
Term-Document Matrix X
NK: Document and Term Correlation (2)
Document correlation matrix: A matrix in which the rows and
the columns represent documents, and entries represent the semantic
similarity between two documents.
Example:
D1: “I like this book”
D2: “We wrote this book”
Document Correlation matrix K = (XTX)
NK: Document and Term Correlation (3)
Term Correlation Matrix:- A matrix in which the rows and the columns represent
terms, and entries represent the semantic similarity between two terms.
Example:
D1: “I like this book”
D2: “We wrote this book”
Term Correlation Matrix T = (XXT)
Neumann Kernel Block Diagram
.
Input:
Graph
Output: Two matrices of dimensions n x n called K γ and Tγ
Diffusion/Decay Factor: A tunable parameter that controls the
balance between relatedness and importance
NK: Diffusion Factor - Equation & Effect
Neumann Kernel defines two matrices incorporating a
diffusion factor:
Simplifies with our
definitions of K and T
When
When
NK: Diffusion Factor - Terminology
Indegree = The indegree, δ-(v), of vertex v
is the number of edges leading to vertex v.
δ- (B)=1
Outdegree = The outdegree, δ+(v), of
vertex v is the number of edges leading
away from vertex v.
δ+(A)=3
Maximal indegree= The maximal
indegree, Δ-, of the graph is the maximum
of all indegree counts of all vertices of
graph.
Δ-(G)= 2
Maximal outdegree= The maximal
outdegree, Δ+, of the graph is the maximum
of all outdegree counts of all vertices of
graph.
Δ+(G)= 3
A
B
C
D
NK: Diffusion Factor - Algorithm
NK: Choice of Diffusion Factor and its effects
on the Neumann Algorithm
• Neumann Kernel outputs relatedness between
documents and between terms when g = γ
• Similarly when γ is larger, then the Kernel
output matches with HITS
Comparing NK, HITS, and
Co-citation Bibliographic Coupling
n1
n2
n3
n4
n5
n6
n7
n8
HITS. authority ranking for above graph
n3 > n 4 > n 2 > n 1 > n 5 = n 6 = n 7 = n 8
Calculation of Neumann Kenel for gamma=0.207 which is
maximum possible value of gamma for this case gives following
ranking
n3 > n 4 > n 2 > n 1 > n 5 = n 6 = n 7 = n 8
For higher values of gamma Neumann Kernel converges to HITS
Strengths and Weaknesses
Strengths
Weaknesses
Generalization
of HITS
Topic Drift
Merges
relatedness
and
importance
No penalty for
loops in
adjacency
matrix
Useful in many
graph
applications
Outline
• Defining Proximity Measures
• Neumann Kernels
• Shared Nearest Neighbor
37
Shared Nearest Neighbor (SNN)
• An indirect approach
to similarity
• Uses a dynamic
method of a kNearest Neighbor
graph to determine
the similarity
between the nodes
• If two vertices have
more than k
neighbors in common
then they can be
considered similar to
one another even if a
direct link does not
exist
SNN - Agenda
Understanding Proximity
Proximity Graphs
Shared Nearest Neighbor Graph
SNN Algorithm
Time Complexity
R Code Example
Outlier/Anomally Detection
Strengths
Weaknesses
SNN – Understanding Proximity
What makes a node a
neighbor to another
node is based off of the
definition of proximity
Definition: the
closeness between
a set of objects
Proximity can
measure the extent
to which the two
nodes belong to
the same cluster.
Proximity is a
subtle notion
whose definition
can depend on a
specific application
SNN - Proximity Graphs
• A graph obtained by connecting two points,
in a set of points, by an edge if the two
points, in some sense, are close to each
other
SNN – Proximity Graphs
(continued)
1
2
3
4
5
1
6
5
LINEAR
Various Types of
Proximity Graphs
2
4
7
6
RADIAL
2
1
5
3
CYCLIC
3
4
SNN – Proximity Graphs
(continued)
GABRIEL GRAPH
Other types of
proximity
graphs.
NEAREST NEIGHBOR
GRAPH
(Voronoi diagram)
MINIMUM SPANNING
TREE
RELATIVE NEIGHBOR
GRAPH
SNN – Proximity Graphs (continued)
Represents neighbor relationships
between objects
Can estimate the likelihood that a
link will exist in the future, or is
missing in the data for some reason
Using a proximity graph increases
the scale range over which good
segmentations are possible
Can be formulated with respect to
many metrics
SNN – Kth Nearest Neighbor (k-NN)
Graph
Forms the basis for the
Shared Nearest
Neighbor (SNN)
within-graph proximity
measure
Has applications in
cluster analysis and
outlier detection
SNN – Shared Nearest Neighbor Graph
• An SNN graph is a
special type of KNN
graph.
• If an edge exists between
two vertices, then they
both belong to each
other’s k-neighborhood
In the figure to the left, each of the two
black vertices, i and j, have eight nearest
neighbors, including each other. Four of
those nearest neighbors are shared which
are shown in red. Thus, the two black
vertices are similar when parameter k=4
for SNN graph.
SNN – The Algorithm
Input: G: an undirected graph
Input: k: a natural number (number of shared neighbors)
for i = 1 to N(G) do
for j = i+1 to N(G) do
if j < = N(G) then
counter = 0
end if
for m = 1 to N(G) do
if vertex i and vertex j both have an edge with vertex m
then
counter ++
end if
end for
if counter k then
Connect an edge between vertex i and vertex j in SNN
graph.
end if
end for
end for
return SNN graph
SNN – Time Complexity
The number of vertices of graph G can be
defined as n
for i = 1
to n
for j = 1
to n
for k = 1
to n
“for loops” i and
k iterate once for
each vertex in
graph G (n
times)
“for loop” j
iterates at
most n -1
times (O(n))
Cumulatively
this results in
a total
running time
of:
O(n3)
SNN – R Code Example
•
•
•
•
•
•
•
•
library(“igraph”)
library(“ProximityMeasure”)
data =
c(
0, 1, 0, 0, 1, 0,
1, 0, 1, 1, 1, 0,
0, 1, 0, 1, 0, 0,
0, 1, 1, 0, 1, 1,
1, 1, 0, 1, 0, 0,
0, 0, 0, 1, 0, 0)
mat = matrix(data,6,6)
G = graph.adjacency(mat,mode=c("directed"),
weighted=NULL)
V(G)$label<-c(‘A’,’B’,’C’,’D’,’E’,’F’)
tkplot(G)
SNN(mat, 2)
[0] A -- D
[1] B -- D
[2] B -- E
[3] C -- E
A
E
B
D
C
F
SNN – Outlier/Anomaly Detection
Outlier/Anomaly
Outlier/Anomaly
• something that
deviates from what is
standard, normal, or
expected
Outlier/Anomaly
Detection
• detecting patterns in
a given data set that
do not conform to an
established normal
behavior
3.5
3
2.5
2
1.5
1
0.5
0
0
1
2
3
SNN - Strengths
Ability to handle noise
and outliers
Ability to handle clusters
of different sizes and
shapes
Very good at handling
clusters of varying
densities
SNN - Weaknesses
Does not take into account
the weight of the link
between the nodes in a
nearest neighbor graph
A low similarity amongst
nodes of the same cluster in
a graph can cause it to find
nearest neighbors that are
not in the same cluster
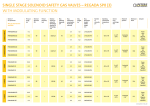
Time Complexity Comparison
Run Time
HITS
Nuemann Kernel
Shared Nearest
Neighbor
O(k*n2.376)
O(n2.376)
O(n3)
Conclusion:
Nuemann Kernel <= HITS < SNN