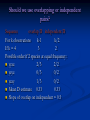
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Butterfly diversity…………………… in rain forest What is ecological diversity? Based on 1) Species richness, i.e. number of species present But also greater if most species have equal numbers than if one or two predominate, so includes 2) Species abundance Relative abundance pi from field samples Two types of display commonly used. (data from an English field study over many years) Rank Order individuals in each species in descending order of rank Species abundance species with 1,2,3,… etc individuals on number of individuals Useful too to have a diversity index N individuals in a community, with S species, each at frequency pi Diversity increases with S But also affected by species composition For given S diversity is: Least when 1 species predominates Greatest when all pi = 1/S So a diversity index has to measure both A well known one is Simpson’s index Based on pi, the probability of picking an individual of species i estimated from frequency Probability of picking two of species i is pi2 Probability of getting two any species = Σpi2. ( = information content of a sample) Gets smaller as diversity goes up Sometimes expressed as 1/Σpi2 or -logΣpi2 which increase with increased diversity Short digression Simpson’s index is 1/Σpi2 or -logΣpi2 Shannon Index, H, is -Σpi.log pi both increase with increased diversity Evenness is defined as nearness of index to maximum Evenness (Simpson) = (-logΣpi2)/logS Evenness (Shannon) = (-Σpi.log pi)/log S Relation of H to Simpson: H = -log/Σpi2 if all pi = 1/S H ≈ 2.5 log (1/Σpi2) if distribution extreme Sampling location, Ecuador San José de Payamino, Orellana Province Arrival at Coca Payamino research site At Payamino site Probably ca 1000 butterfly species No good identification guides Several reasons not to catch and kill them But we might try to measure ecological diversity, which is a useful measure of habitat quality Indexes like Simpson’s Index usually estimated by counting numbers in each species. But Σpi2 (i.e. the probability that two individuals in a pair are the same species)……. can be found directly by observation Field data book: /////////// = a = number of like pairs /////////////// = b = unlike pairs n = a+b = total pairs ////////// = S = species seen -----------------------------------------------------------a/n = fraction of like pairs seen which is an estimate of Σpi2 So sequential estimate is: D = a/n which does not need relative abundance counts, or, if preferred, use 1/D (or –log D) Evenness of D can be measured as E = (1-D)/(1-1/S) If S large this is close to 1-D Data collected from two sides of Payamino river Conclusion from data These estimates show that: 1. repeatable estimates of D can be made (mean SED about the same as standard deviation of D) 2. differences in diversity between sites can be detected (mean D significantly different at the two sites) Some problems of accuracy of D 1. Aggregation, courtship etc. affect estimate, so sampling must be as random as possible 2. Binomial variance of D is ab/n3, larger than large-sample var of Simpson’s index, 2[Σpi3 - (Σpi2)2]/n 3. but data for D are easier to gather and little knowledge of species is needed To test accuracy we could compare relative abundance estimates with sequential estimates made from the same series of observations. and compare results of simulations P1 P2 P3 P4 P5 P6 …… P1 f11 f12 f13 f14 f15 f16 …. P2 f21 f22 f23 f24 f25 f26 …. P3 f31 f32 f33 f34 f35 f36 P4 f41 f42 f43 f44 f45 f46 P5 f51 f52 f53 f54 f55 f56 P6 f61 f62 f63 f64 f65 f66 . . . . . . . (Σf1)2+(Σf2)2+ etc …….... Σfii for frequencies for sequential If some mistakes are made they have similar accuracy Should we use overlapping or independent pairs? Sequence overlap D independent D For k observations k-1 k/2 If k = 4 3 2 Possible order if 2 species at equal frequency: yyzz 2/3 2/2 yzyz 0/3 0/2 yzzy 1/3 0/2 Mean D estimate 0.33 0.33 Slope of overlap on independent = 0.5 Overlapping or independent? So estimates from overlapping data tend to the same mean as independent ones and are more closely grouped Relationship of indexes Indexes are related by Rényi’s equation Na = (Σpia) 1/(1-a) = generalized entropy of order a a Na relates to --------------------------------------------------------------------------------------------------- -inf 0 1 2 +inf 1/pmin S eH 1/D 1/pmax freq(rarest species) number of species Shannon index Simpson index Berger-Parker index Graffiti in Coca Why butterflies? Butterflies are part of the public awareness of ecological richness of the region for both local people and visitors It is worth finding out more about them, including their diversity General conclusions Diversity and evenness can be estimated from sequential observations Repeat trials produce consistent estimates and show a difference between habitats Method is easy to apply and practical when there is little taxonomic expertise Cook LM (2008) Diversity and evenness from sequential sightings. Insect Conservation and Diversity 1, 263-265 Simpson EH (1949) Measurement of diversity. Nature, Lond. 163,388