Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
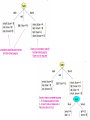
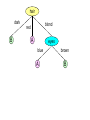
Department of Computer Science Sir Syed University of Engineering & Technology, Karachi-Pakistan. Presentation Title: DATA MINING Submitted By What is data mining ? Data mining consists of five major elements Why Mine Data? Commercial Viewpoint Scientific Viewpoint Some of the techniques used for data mining Data Mining, also known as KnowledgeDiscovery in Databases (KDD), is the process of automatically searching large volumes of data for patterns. It is the process of extraction of knowledge from large datasets. Extremely large datasets. Useful knowledge that can improve processes. Extract, transform, and load transaction data onto the data warehouse system. Store and manage the data in a multidimensional database system. Provide data access to business analysts and information technology professionals. Analyze the data by application software. Present the data in a useful format, such as a graph or table. Lots of data is being collected and warehoused Web data, e-commerce purchases at department/ grocery stores Bank/Credit Card transactions Computers have become cheaper and more powerful Competitive Pressure is Strong Provide better, customized services for an edge (e.g. in Customer Relationship Management) Data collected and stored at enormous speeds (GB/hour). remote sensors on a satellite telescopes scanning the skies microarrays generating gene expression data scientific simulations generating terabytes of data Traditional techniques infeasible for raw data. Data mining may help scientists . in classifying and segmenting data Artificial neural networks - Neural networks are useful for pattern recognition or data classification, through a learning process. Non-linear predictive models that learn through training and resemble biological neural networks in structure. Neural Networks map a set of input-nodes to a set of output-nodes Number of inputs/outputs is variable The Network itself is composed of an arbitrary number of nodes with an arbitrary topology Input 0 Input 1 ... Input n Neural Network Output 0 Output 1 ... Output m Tree-shaped structures that represent sets of decisions. These decisions generate rules for the classification of a dataset. height short tall tall short tall tall tall short hair blond blond red dark dark blond dark blond eyes blue brown blue blue blue blue brown brown class A B A B B A B B hair dark blond red B A eyes blue A brown B A classification technique that classifies each record based on the records most similar to it in an historical database. • Clustering can be considered the most important unsupervised learning technique; so, as every other problem of this kind, it deals with finding a structure in a collection of unlabeled data. • Clustering is “the process of organizing objects into groups whose members are similar in some way”. • A cluster is therefore a collection of objects which are “similar” between them and are “dissimilar” to the objects belonging to other clusters. The greater the similarity (or homogeneity) within a group, and the greater the difference between groups, the “better” or more distinct the clustering. A few good reasons ... Simplifications Pattern detection Basic K-means Algorithm for finding K clusters: 1. Select K points as the initial centroids. 2. Assign all points to the closest centroid. 3. Recompute the centroid of each cluster. 4. Repeat steps 2 and 3 until the centroids don’t change.