Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
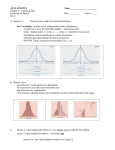
Normal distributions Suppose a region has area A and a subregion has area A1 : If a point is placed at random in the larger region, the probability that the point is in the subregion is p = AA1 : If A = 1 then p = A1 : Suppose a company sells bags of peanuts. A bag is supposed to weight 32 ounces. A quality control expert weighed some bags as they left the production line: The results are as follows: weight 31:3 ∙ x < 31:5 31:5 ∙ x < 31:7 31:7 ∙ x < 31:9 31:9 ∙ x < 32:1 32:1 ∙ x < 32:3 32:3 ∙ x < 32:5 32:5 ∙ x < 32:7 f=no. bags 11 23 36 58 40 20 12 midpt. 31.4 31.6 31.8 32 32.2 32.4 32.6 The mean is approximately 32 s=standard deviation is approximately .3 Given a bag of peanuts at random, what is the probability that its weight is between 31.9 and 32.1? One way of answering: 58/200 by simple counting; there are 200 bags in all and 58 of them have weight between 31.9 and 32.1. Another way: Fit a curve to the data, and ¯nd the ratio of the area under the curve that is inside the strip a < x < b and then divide by the total area under the curve. Use the standard normal curve so that the total area under the curve is 1. Given the mean m and the standard deviation s, the curve that approximates the data is 1 x¡m 2 1 f (x) = p e¡ 2 ( s ) 2¼s2 If that curve gives a good approximation to the data, then the data is called a normal distribution. In that case, the above function is the associated normal function. The actual formula is not important in this course. The point is this: If you have a normal distribution, then with a calculator or computer you can ¯nd the area under the curve between two points a and b. Here is a chart with the relative frequency densities, a smooth curve through the middles of the tops of the rectangles, and the associated normal function. Given a normal distribution, all you need to be given is the mean and the standard deviation. Then you can ¯nd a curve that approximates the data. In the example of the bags of peanuts, we want p(a<x<b). In other words, we want the area under the associated normal function (the yellow curve) between 31.9 and 32.1. If we know that, then we know the percentage of the bags that weigh between 31.9 and 32.1 ounces, and then we would know the number of bags that weigh between 31.9 and 32.1 ounces. In our example, the mean m is approximately 32, the standard deviation s is approximately .3, a=31.9, and b=32.1. With these values of m and s, p(a < x < b) ¼ :26: So approximately 26% of the bags weigh between 31.9 and 32.1 ounces. So we get an answer that :26 £ 200 = 52 of the bags weigh between 31.9 and 32.1 ounces. We don't expect exact agreement with the answer by directly counting. The area under the approximating curve, the associated normal function, is not exactly the same as the area of the rectangles between two points a and b. After all that, we could have stated our problem as follows. A weights of a collection of bags of peanuts are normally distributed, with a mean of 32 ounces and a standard deviation of .3 ounces. What is the probability that a bag chosen at random weights between 31.9 and 32.1 ounces? If there are 200 bags in all, approximately how many bags weigh between 31.9 ounces and 32.1 ounces? This is all the information you need to answer the question. Computing p(a < x < b) using a calculator: The way you do this computation on a calculator depends on which calculator you have. COMPUTING p(a < x < b) WITH THE TI-83: On a TI-83, you push DISTR (¯rst push the 2nd key, release that key and then push the VARS key.) Then highlight normalcdf( and push enter. Now enter lowerbound, upperbound, m, s) so you see normalcdf(31.9,32.1,32,.3) Then push enter to see .2611... which we round to .26. Given m,s,a,x, the notation p(a < x) means b is very large (in¯nity), so use 1E99 for the value of b. If you prefer, you can use a relatively large number such as a + 5 £ s for b. Similarly, p(x < b) means a is negative in¯nity, so you use -1E99 for a, or b ¡ 5 £ s for a, in that case. In my TI-83 manual this is on page 13-30. Your manual might be di®erent. For another example, if you want p(x < 1:25) with m = 0; s = 1; you should check that normalcdf(-1E99,1.25,0,1)=.894350161. Recall that to enter a number in scienti¯c notation, for example, -1E99, ¯rst push the (-) key next to the ENTER key. Then enter 1. Then press 2nd EE so E is pasted to the cursor location. Then enter 99. Now suppose you are given the problem p(x < a) = 0:8 and m = 0; s = 1; and you want to ¯nd what a is. This time you use invNorm(, which is right below normalcdf(. Check that invNorm(.8,0,1)=.8416212335, in other words, a is approximately .84. If you have a di®erent model TI calculator, look up normalcdf in the manual. (Optional for TI 82 users: click here) If you have an HP38G, the function UTPN(mean,variance,x) gives the area of the tail, that is, the area under the curve from x to in¯nity. For example, if the mean=0 and the standard deviation=1, since the variance =(standard deviation)2 ; then the variance is 1 in this case. Suppose x = 1.87. Then p(x > 1:87) = UTPN(0; 1; 1:87) = :0307419::: You get the function UTPN by pushing math, then scrolling down to Prob., then over and scroll down to UTPN. You might notice it is faster to push math, then scroll up once to Prob., then over and up twice to UTPN. Suppose you want p(0:75 < x < 1:25) with mean=0 and standard deviation=1. The area under the curve is the area from 0.75 minus the area from 1.25 to in¯nity, so p(0:75 < x < 1:25)=UTPN(0,1,.75)-UTPN(0,1,1.25)=.1209775781... Now suppose the mean is 68 and the standard deviation is 4. We want p(73 < x): The variance =16, so we want UTPN(68,16,73)=.1056... If you are given a value for p and want a, for example, if you have the equation p(a < x) = :1056 and you are given m=68, standard deviation=4, you could plot the function f(x)=UTPN(68,16,x) and use trace to ¯nd where f(x)=.1056 approximately and you will quickly ¯nd x is approximately 73, so that is your value of a. You need to remember that the HP38G uses UTPN(mean, variance, x) so you need to use the variance, not the standard deviation, as your second variable. If you are already familiar with the HP38G, you can add f(x)=UTPN(68,16,x) as one function, f(x)=.1056 as another function, making sure there are check marks by those two functions, then make reasonable choices for the x range, say x=68 and x=100. Choose the y range with 0 and 1 for the limits. After plotting, go to the menu, then fcn menu, then choose intersection. You calculator will ¯nd the value of a, where those two functions intersect, automatically for you. Computing p(a < x < b) using Excel: The Excel function normdist(b,m,s,true) gives the area under the curve from negative in¯nity to b. The Excel function normdist(a,m,s,true) gives the area under the curve from negative in¯nity to a. Therefore The Excel function normdist(b,m,s,true) - normdist(a,m,s,true) gives the area under the curve from a to b. For example, suppose a=15.9,b=16.1, m=16, s=0.3. Click on a cell, for example a1. Then enter =normdist(16.1,16,.3,true), or if you forget what the function is, click on the paste function (f*), statistical, then normdist, then OK. Enter the point x, the mean, the standard deviation, and choose true under the choice cumulative (this means you are ¯nding an area). Next, click on a cell below, for example a2. Then enter =normdist(15.9,16,.3,true). Then in the cell below that, for example a3, enter=a1-a2. If you prefer, you can simply type in at a cell the following: =normdist(16.1,16,.3,true)-normdist(15.9,16,.3,true) The answer is approximately 0.26, which is close to 58/200. We don't expect exact agreement since the data is not exactly a normal distribution (it should be bell-shaped and be symmetric about the mean) and the areas under the approximating rectangles are not the same as the area under the curve that tries to ¯t the data. Another example: Suppose you want to ¯nd the area under the curve from negative in¯nity to 1.25 for the standard normal distribution (m=0,s=1). We need p(x < 1:25) with m = 0; x = 1: Using Excel, we enter =normdist(1.25,0,1,true) in a cell and get 0.89435 for an answer. Now suppose we are given a probability, for example suppose we are given p=0.8 with m=0 and s=1. In other words, we are given p(x < b) = 0:8 but we are not given b. To ¯nd b, we enter =norminv(.8,0,1) in a cell, and we get 0.841621 for an answer. This is the value of b. Another example: The heights of city with a population of 200,000 people are assumed to be normally distributed, with a mean height of 70 inches and the standard deviation is 3 inches. 1. What percentage of the city is taller than 72 inches? 2. What percentage of the city is between 68 and 72 inches tall? 3. How many people are between 68 and 72 inches tall? Answers: 1. With m=70 and s=3, we need p(72 < x) ¼ :25 so about 25 % of the population is taller than 72 inches. 2. With m=70 and s=3, we need p(68 < x < 72) ¼ :495 ¼ :5 so about 50 % of the population is between 68 and 72 inches tall. 3. About 100,000 people are between 68 and 72 inches tall. One more example problem: The scores on an exam are assumed to be normally distributed. The mean was 72 and the standard deviation was 14. Tony had a score of 86. Was Tony in the top 10 percent? What score would someone need to be in the top 10 percent? Answer: With m=72 and s=14, p(86 < x) ¼ :16 so Tony was in the top 16 percent but not in the top 10 percent. In order to ¯nd the cuto®, we want to ¯nd the value of b for p(x < b) = :9 Use your calculator or Excel, and you should get 89.94 approximately. The details of how you get this number vary, depending on which calculator you use. If you use Excel, you would enter =norminv(.9,72,14) in a cell and get 89.94171112.