Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
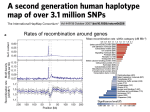
HAPRAP: Haplotype-based iterative method for fine mapping using GWAS summary data Zheng et al., Sept 2016 Questions: (i) “Can we narrow down the list of all SNPs at an associated (GWAS) region/locus to a smaller ‘credible’ set?” (ii) “Are there any other independent signals?” Nice reviews: (i) Strategies for fine-mapping complex traits. Spain and Barrett, 2015, Hum Mol Genet (ii) Fine Mapping Causal Variants with an Approximate Bayesian Method Using Marginal Test Statistics. Chen et al, 2015. Genetics Journal club: 21/09/16 Mesut Erzurumluoglu Population Genetics 101 Linkage disequilibrium (LD) ◦ Non-random association of alleles at two or more loci (if random alleles at two loci coinherited 50% of the time) Haploview software LD example Minor allele: a T Major allele: A T Major allele: B Minor allele: b Observed frequency Haplotypes AB=0.2 D= ? (unstandardized measure of how far the association between two alleles differs from that expected by chance) Ab=0.5 D’ = ? (D standardised to the maximum possible value it can take) aB=0.3 r2 = ? (correlation coefficient) ab=0 Another example Observed Haplotypes AB=0.8 Ab=0 => aB=0 ab=0.2 Alleles A=0.8 a=0.2 B=0.8 b=0.2 => Expected Haplotypes AB=0.64 Ab=0.16 aB=0.16 ab=0.04 D = 0.16 D’ = 1 r2 = 1 Calculations: D = 0.8-(0.8x0.8)=0.8-0.64=0.16 D’ = 0.16/0.16=1 r^2 = (0.16)^2/(0.8x0.2x0.8x0.2)=1 (great for imputation!) Possible explanations: i) Combinations A and b, and a and B are highly disadvantageous to the organism ii) Could be a (small and) highly consanguineous/endogamous population iii) Very small and isolated population LD (2) LD between alleles can be influenced by: ◦ Selection Lack of sunlight ◦ ◦ ◦ ◦ ◦ ◦ White skin and blue eyes Rate of recombination Rate of mutation Genetic drift System of mating Population structure Genetic linkage Haplotype A set of variants that are inherited together – found on the same chromosome ◦ Closer the variants, (usually) smaller the probability of recombination between them Therefore fewer haplotypes are found than maximum possible (as in previous slides, i.e. 3/4) ◦ Higher LD between variants means respective haplotype is inherited more often Introduction to study GWASs provide a powerful approach for identifying variants associated with complex human diseases/traits ◦ However, identifying the ‘causal’ variant(s) is challenging due to LD between SNPs that are close Fine mapping (in a GWAS setting) is the process of narrowing-down a list of associated variants to a ‘credible’ set of most likely causal variants ◦ Prioritizes most-informative variants Many tools/methods out there: Multiple regression, GCTA-COJO, CAVIAR-BF, BIMBAM, PAINTOR, Wakefield 2007 (Bayesian), SSSRAP ◦ Multiple regression is best if individual level (and dense SNP) data is available But this is rarely the case for large GWASs Time consuming Introduction to study (2) Using ‘top SNP’ to represent region is problematic as there may be several causal SNPs Existing state-of-the-art methods (e.g. GCTA-COJO) use r2 between SNPs to represent LD structure ◦ Problematic when there are more than two causal variants in a region as LD information may be lost May introduce constraints on the max/min values for pairwise LD Existing Fine-mapping methods Adapted from: S.L. Spain and J.C. Barrett, Hum Mol Genet, 2015 Existing methods (continued) HAPRAP: approximate conditional analysis using haplotypes GCTA-COJO: approximate conditional analysis using pair-wise LD PAINTOR: integrates association strength with functional genomic annotation data CAVIARBF: Bayesian method with good accuracy FINEMAP: CAVIARBF + shotgun stochastic search algorithm, much faster and allows genome-wide fine mapping RiVIERA: Bayesian method + transcription and cisregulatory element annotations JAM: Bayesian penalized regression with variable selection, designed for the analysis of quantitative traits only Theory Traditional fine-mapping methods, such as conditional analysis, needs genotype and phenotype data for each individual More and more fine mapping methods, such as GCTA-COJO, CAVIAR-BF and FINEMAP, use ‘GWAS summary results + LD reference panel’ to identify causal variants These methods consider pair-wise LD + MAF information to represent LD between SNPs. When considering regions with three or more causal variants, such settings may lose LD information Haplotypes, which represent combinations of co-inherited alleles within the same chromosome, are a more biologically plausible way for representing LD among multiple loci. Fine mapping using haplotypes will pick up the LD information that is not detected using pairwise LD measures Theory HAPlotype Regional Association analysis Program (HAPRAP) ◦ Rationale behind developing HAPRAP: Using haplotypes is biologically a better representation of LD compared to r2 (i.e. pairwise correlation between SNPs) ◦ Iterative method – haplotype effects updated based on haplotype frequencies and observed (single) SNP effects from meta-analyses to estimate joint SNP effect Methods – HAPRAP overview • GWAS summary results • Haplotypes Input HAPRAP • Joint effect analysis • Conditional analysis • Identify possible causal SNPs • Independent effect of each SNP Output Methods i. Extend on a single-SNP based linear regression to multi-locus based regression by: Dichotomising haplotypes into two groups Effect allele SNP j ii. Treating each group as a bivariate allele Methods (continued) • For each SNP, haplotypes were split into two groups: 1) HEj is the set of haplotypes containing the effect allele of SNP j; 2) HBj is the set of haplotypes containing the baseline allele of SNP j. • Marginal SNP effect of j = St(Effect of HEj - Effect of HBj) Estimated β in the gth iteration = Sum of differences between the two groups standardised by the haplotype frequencies Methods (continued) Iterative method used to estimate haplotype effects from single SNP based linear regression (GWAS) results: Step (i) Randomly assign an effect to each SNP (seed: between 10 and -10) Step (ii) Parse these effects into haplotype reference and estimate effect for each (haplotype) group Step (iii) Estimate β for each SNP and cross-check against meta-analysis results Step (iv) If different, repeat after adjusting the β of SNP with the greatest deviation – iterate until estimated haplotype effects agree with observed single SNP meta-analysis results Methods - simHAPRAP • • A bootstrap method used to calculate center estimates and standard errors of the joint SNP effects. Simulate a population with genotypes and phenotypes: • Sample size equal to the total number of participants in the meta-analysis • Genotypes from the haplotype reference panel • Phenotypes from a normal distribution with mean equal to zero and SE equal to the observed standard deviation of the phenotype • • Process the simulation 2000 times, derive mean and standard deviation (SD). The SD is the standard error of the joint SNP effect Datasets ALSPAC (n=8363) data used as haplotype reference panel ◦ SHAPE-IT used to phase haplotypes BWHHS cohort data (n=5425) UCLEB (QTc interval, n=7106) GIANT consortium (height, n=253288) ◦ Three regions: ACAN, ADAMTS17, PTCH1 Gall bladder disease (n=15213) 1000 Genomes – simHAPRAP Results – HAPRAP and GCTA-COJO (simulation) Sample size (N) in log10 scale Results – HAPRAP and GCTACOJO (simulation) Results – Real case example: GIANT (height) data • Total of 4195 SNPs in three genes, 782 SNPs for ACAN, 1477 SNPs for ADAMTS17 and 1936 SNPs for PTCH1 • Using 8263 unrelated ALSPAC children as reference panel. • Found two additional SNPs independently associated with height: 1) rs357564: a missense variant in PTCH1 with joint effect of -0.034 2) rs1529889: an intronic variant in ADAMTS17 with joint effect of 0.019 Conclusions HAPRAP uses GWAS summary data to carry out an ‘approximate’ conditional analysis and narrow down list of SNPs to a credible set ◦ Also selects independent SNPs Relatively better accuracy compared to GCTA-COJO when the sample size of the meta-analysis is limited (N ≤5000) Discussion HAPRAP’s advantages over other methods ◦ Biologically makes more sense ◦ Makes better use of summary level data Compared to GCTA-COJO and SSSRAP Especially if there are several causal SNPs at a locus Can handle rare variants better than others Demonstrated using BWHHS data (APOB SNP, MAF=0.18%) ◦ Considers all loci simultaneously rather than pairwise More immune to poor LD estimates due to mismatches between reference panel and meta-analysis samples Discussion (continued) Reference panel was derived from 1000GP (older version) ◦ Would be interesting to see how results would change/improve with the new updated reference panel (McCarthy et al, 2016) HLA regions are being investigated (as an addition in next version) Easily applied to different ethnicities – with a matching reference panel Will be interesting to see whether rs357564 and rs1529889 are true signals Limitations of HAPRAP Assumptions ◦ Haplotypes and frequencies in the reference panel and the meta-analysis set are the same ◦ Additive model Standard error estimation can be time consuming Limited number of SNPs for each analysis (ideally <20 SNPs in a region) Appendices Fine-mapping software download URLs HAPRAP: http://apps.biocompute.org.uk/haprap/ GCTA-COJO: http://cnsgenomics.com/software/gcta/cojo.html PAINTOR: http://bogdan.bioinformatics.ucla.edu/software/paintor/ CAVIARBF: https://bitbucket.org/Wenan/caviarbf JAM: https://github.com/pjnewcombe/R2BGLiMS FINEMAP: http://www.christianbenner.com/ RiVIERA: https://github.com/yueli-compbio/RiVIERA-MT LD-Hub for LD Score Regression The basic idea is that the more genetic variation a marker tags, the higher the probability that it will tag a causal variant. In contrast, linkage disequilibrium score (LD score) should not be correlated with population stratification Univariate analysis 8 6 4 Chi square 6 2 4 0 2 0 Chi square 8 10 10 Bivariate analysis 0 20 40 60 LD Score 80 100 0 20 40 60 LD Score 80 100 LD-Hub: a database of harmonized GWAS summary data GWAS studies that have released all their results 65 studies + (36 consortia) 1000 trait analyses >2 billion SNP-phenotype associations >1.5 million individuals 89 diseases 9 cancers 19 psychiatric/neurological 45 auto./inflammatory 6 cardiovascular 4 diabetic 6 other 154 risk factors Other 75 anthropometric 6 behavioural 24 glycaemic 9 lipids 4 blood pressure 6 hematological 30 other 576 metabolites 151 immune traits GWAS studies that have released subsets of results 2414 GWAS studies† ~80,000 traits ~70,000 SNP-trait associations eQTL/pQTLs 12,000 gene expression 146 protein expression LD-Hub web interface Link to web interface: ldsc.broadinstitute.org/ldhub BioRxiv link: http://biorxiv.org/content/early/2016/05/03/051094