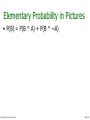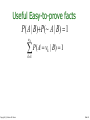Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
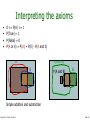
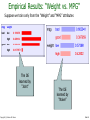
Probabilistic and Bayesian Analytics Andrew W. Moore Professor School of Computer Science Carnegie Mellon University www.cs.cmu.edu/~awm [email protected] Copyright © Andrew W. Moore Slide 1 Probability • The world is a very uncertain place • 30 years of Artificial Intelligence and Database research danced around this fact • And then a few AI researchers decided to use some ideas from the eighteenth century. • We will review the fundamentals of probability. Copyright © Andrew W. Moore Slide 2 Discrete Random Variables. Caso Binario • A is a Boolean-valued random variable if A denotes an event, and there is some degree of uncertainty as to whether A occurs. • Examples • A = The US president in 2023 will be male • A = You wake up tomorrow with a headache • A = You have Ebola Copyright © Andrew W. Moore Slide 3 Probabilidades • Denotamos P(A) , la probabilidad de A, como “la fraccion de todas las ocurrencias en las cuales A es cierta”. • Existen varias maneras de asignar probabilidades pero no hablaremos de eso ahora. Copyright © Andrew W. Moore Slide 4 Diagrama de Venn para visualizar A Espacio muestral de todas las ocurrencias posibles. El area es 1 Copyright © Andrew W. Moore Ocurrencias en las cuales A es cierta P(A) = Area de la parte ovalada Ocurrencias en las cuales A es Falsa Slide 5 The Axioms of Probability • • • • 0 <= P(A) <= 1 P(A es cierta en todas las ocurrencias) = 1 P(en ninguna ocurrencia A es cierta) = 0 P(A or B) = P(A) + P(B) si A y B son disjuntos. Estos axiomas fueron introducidos por la escuela rusa al principio de los 1900: Kolmogorov, Liapunov, Kinthchine, Chebychev Copyright © Andrew W. Moore Slide 6 Interpreting the axioms • • • • 0 <= P(A) <= 1 P(True) = 1 P(False) = 0 P(A or B) = P(A) + P(B) The area of A can’t get any smaller than 0 And a zero area would mean no world could ever have A true Copyright © Andrew W. Moore Slide 7 Interpreting the axioms • • • • 0 <= P(A) <= 1 P(True) = 1 P(False) = 0 P(A or B) = P(A) + P(B) The area of A can’t get any bigger than 1 And an area of 1 would mean all worlds will have A true Copyright © Andrew W. Moore Slide 8 Interpreting the axioms • • • • 0 <= P(A) <= 1 P(True) = 1 P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) A B Copyright © Andrew W. Moore Slide 9 Interpreting the axioms • • • • 0 <= P(A) <= 1 P(True) = 1 P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) A P(A or B) B P(A and B) B Simple addition and subtraction Copyright © Andrew W. Moore Slide 10 Theorems from the Axioms • 0 <= P(A) <= 1, P(True) = 1, P(False) = 0 • P(A or B) = P(A) + P(B) - P(A and B) From these we can prove: P(not A) = P(~A) = 1-P(A) • How? Copyright © Andrew W. Moore Slide 11 Another important theorem • 0 <= P(A) <= 1, P(True) = 1, P(False) = 0 • P(A or B) = P(A) + P(B) - P(A and B) From these we can prove: P(A) = P(A ^ B) + P(A ^ ~B) • How? Copyright © Andrew W. Moore Slide 12 Multivalued Random Variables • Suppose A can take on more than 2 values • A is a random variable with arity k if it can take on exactly one value out of {v1,v2, .. vk } • Thus… P( A vi A v j ) 0 if i j P( A v1 A v2 .... A vk ) 1 Copyright © Andrew W. Moore Slide 13 An easy fact about Multivalued Random Variables: • Using the axioms of probability… 0 <= P(A) <= 1, P(True) = 1, P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) • And assuming that A obeys… P( A vi A v j ) 0 if i j P( A v1 A v2 .... A vk ) 1 • It’s easy to prove that i P( A v1 A v2 ... A vi ) P( A v j ) j 1 Copyright © Andrew W. Moore Slide 14 An easy fact about Multivalued Random Variables: • Using the axioms of probability… 0 <= P(A) <= 1, P(True) = 1, P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) • And assuming that A obeys… P( A vi A v j ) 0 if i j P( A v1 A v2 ... A vk ) 1 • It’s easy to prove that i P( A v1 A v2 ... A vi ) P( A v j ) j 1 • And thus we can prove k P( A v ) 1 j 1 Copyright © Andrew W. Moore j Slide 15 Another fact about Multivalued Random Variables: • Using the axioms of probability… 0 <= P(A) <= 1, P(True) = 1, P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) • And assuming that A obeys… P( A vi A v j ) 0 if i j P( A v1 A v2 ... A vk ) 1 • It’s easy to prove that i P( B [ A v1 A v2 ... A vi ]) P( B A v j ) j 1 Copyright © Andrew W. Moore Slide 16 Another fact about Multivalued Random Variables: • Using the axioms of probability… 0 <= P(A) <= 1, P(True) = 1, P(False) = 0 P(A or B) = P(A) + P(B) - P(A and B) • And assuming that A obeys… P( A vi A v j ) 0 if i j P( A v1 A v2 ... A vk ) 1 • It’s easy to prove that i P( B [ A v1 A v2 ... A vi ]) P( B A v j ) j 1 • And thus we can prove k P( B) P( B A v j ) j 1 Copyright © Andrew W. Moore Slide 17 Elementary Probability in Pictures • P(~A) + P(A) = 1 Copyright © Andrew W. Moore Slide 18 Elementary Probability in Pictures • P(B) = P(B ^ A) + P(B ^ ~A) Copyright © Andrew W. Moore Slide 19 Elementary Probability in Pictures k P( A v ) 1 j 1 Copyright © Andrew W. Moore j Slide 20 Elementary Probability in Pictures k P( B) P( B A v j ) j 1 Copyright © Andrew W. Moore Slide 21 Conditional Probability • P(A|B) = fraccion de ocurrencias en las cuales B es cierta y en las cuales A es tambien cierta. H = “Have a headache” F = “Coming down with Flu” P(H) = 1/10 P(F) = 1/40 P(H|F) = 1/2 F H Copyright © Andrew W. Moore “Headaches are rare and flu is rarer, but if you’re coming down with ‘flu there’s a 5050 chance you’ll have a headache.” Slide 22 Conditional Probability P(H|F) = fraccion de los que tiene flu que tienen headache F H = #ocurrencias con flu and headache -----------------------------------#ocurrencias with flu H = “Have a headache” F = “Coming down with Flu” = Area of “H and F” region -----------------------------Area of “F” region P(H) = 1/10 P(F) = 1/40 P(H|F) = 1/2 = P(H ^ F) ----------P(F) Copyright © Andrew W. Moore Slide 23 Definition of Conditional Probability P(A ^ B) P(A|B) = ----------P(B) Corollary: The Chain Rule P(A ^ B) = P(A|B) P(B) Copyright © Andrew W. Moore Slide 24 Probabilistic Inference H = “Have a headache” F = “Coming down with Flu” F H P(H) = 1/10 P(F) = 1/40 P(H|F) = 1/2 One day you wake up with a headache. You think: “Drat! 50% of flus are associated with headaches so I must have a 50-50 chance of coming down with flu” Is this reasoning good? Copyright © Andrew W. Moore Slide 25 Probabilistic Inference H = “Have a headache” F = “Coming down with Flu” F H P(H) = 1/10 P(F) = 1/40 P(H|F) = 1/2 P(F ^ H) =P(F)P(H/F)=(1/40)(1/2)=1/80 P(F|H) =P(F^H)/P(H)=(1/80)/(1/10)=1/8=.125 Copyright © Andrew W. Moore Slide 26 Another way to understand the intuition Thanks to Jahanzeb Sherwani for contributing this explanation: Copyright © Andrew W. Moore Slide 27 What we just did… P(A ^ B) P(A|B) P(B) P(B|A) = ----------- = --------------P(A) P(A) This is Bayes Rule. P(B) es llamada la probabilidad apriori, P(A/B) es llamada la veosimiltud, y P(B/A) es la probabilidad posterior Bayes, Thomas (1763) An essay towards solving a problem in the doctrine of chances. Philosophical Transactions of the Royal Society of London, 53:370-418 Copyright © Andrew W. Moore Slide 28 More General Forms of Bayes Rule P( B | A) P( A) P( A |B) P( B | A) P( A) P( B |~ A) P(~ A) P( B | A X ) P( A X ) P( A |B X ) P( B X ) Copyright © Andrew W. Moore Slide 29 More General Forms of Bayes Rule P( A vi |B) P( B | A vi ) P( A vi ) nA P( B | A v ) P( A v ) k 1 Copyright © Andrew W. Moore k k Slide 30 Useful Easy-to-prove facts P( A | B)P(~ A | B) 1 nA P( A v k 1 Copyright © Andrew W. Moore k | B) 1 Slide 31 The Joint Distribution Example: Boolean variables A, B, C Recipe for making a joint distribution of M variables: Copyright © Andrew W. Moore Slide 32 Usando la Regla de Bayes en Juegos $1.00 El sobre “Ganador” tiene un dolar y 4 bolitas (2 rojas y 2 negras). El sobre “Perdedor” tiene 3 bolitas ( una roja y dos negras) y no tiene dinero. Pregunta: Alguien extrae un sobre al azar y te lo ofrece en venta? Cuanto deberias pagar por el sobre? Copyright © Andrew W. Moore Slide 33 Using Bayes Rule to Gamble $1.00 El sobre “Ganador” tiene un dolar y 4 bolitas (2 rojas y 2 negras). El sobre “Perdedor” tiene 3 bolitas ( una roja y dos negras) y no tiene dinero. Pregunta interesante: Antes de decidir, se le permite a Ud. Que vea una bolita extraida del sobre. Suponga que es negra cuanto deberia Ud pagar por el sobre? Suponga que es roja, cuanto deberia Ud. Pagar por el sobre? Copyright © Andrew W. Moore Slide 34 Calculo… $1.00 P(Ganador/Bola negra)=P(Ganador^BN)/P(BN) =P(Ganador)P(BN/Ganador)/P(BN) P(BN)=P(BN^Ganador)+P(BN^Perdedor) =P(Ganador)P(BN/Ganador)/P(BN)+P(Perdedor)P(BN/Perdedor) =(1/2)(2/4)+(1/2)(2/3)=7/12 P(Ganador/Bola negra)=(1/4)/(7/12)=3/7=.43 No pagaria nada por el sobre. Ahora P(Ganador/Bola Roja)=P(Ganador ^ BR)/P(BR) =.40 Copyright © Andrew W. Moore Slide 35 Distribuciones conjuntas Recipe for making a joint distribution of M variables: 1. Make a truth table listing all combinations of values of your variables (if there are M Boolean variables then the table will have 2M rows). Example: Boolean variables A, B, C A B C 0 0 0 0 0 1 0 1 0 0 1 1 1 0 0 1 0 1 1 1 0 1 1 1 A=1 si la persona es varon y 0 si es mujer, B=1 si la persona esta casada y 0 si no esta y C =1 si la persona esta enferma y 0 si no lo esta Copyright © Andrew W. Moore Slide 36 The Joint Distribution Recipe for making a joint distribution of M variables: 1. Make a truth table listing all combinations of values of your variables (if there are M Boolean variables then the table will have 2M rows). 2. For each combination of values, say how probable it is. Copyright © Andrew W. Moore Example: Boolean variables A, B, C A B C Prob 0 0 0 0.30 0 0 1 0.05 0 1 0 0.10 0 1 1 0.05 1 0 0 0.05 1 0 1 0.10 1 1 0 0.25 1 1 1 0.10 Slide 37 The Joint Distribution Recipe for making a joint distribution of M variables: 1. Make a truth table listing all combinations of values of your variables (if there are M Boolean variables then the table will have 2M rows). 2. For each combination of values, say how probable it is. 3. If you subscribe to the axioms of probability, those numbers must sum to 1. A B C Prob 0 0 0 0.30 0 0 1 0.05 0 1 0 0.10 0 1 1 0.05 1 0 0 0.05 1 0 1 0.10 1 1 0 0.25 1 1 1 0.10 A 0.05 0.25 0.30 Copyright © Andrew W. Moore Example: Boolean variables A, B, C B 0.10 0.05 0.10 0.05 C 0.10 Slide 38 Datos para el ejemplo de la JD • The Census dataset: 48842 instances, mix of continuous and discrete features (train=32561, test=16281)45222. if instances with unknown values are removed (train=30162,test=15060) Disponible en: http://ftp.ics.uci.edu/pub/machinelearning-databases Donantes: Ronny Kohavi y Barry Becker (1996). Copyright © Andrew W. Moore Slide 39 Variables en Census • 1-age: continuous. • 2-workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Neverworked. • 3-fnlwgt (final weight) : continuous. • 4-education: Bachelors, Some-college, 11th, HS-grad, Profschool, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool. • 5-education-num: continuous. • 6-marital-status: Married-civ-spouse, Divorced, Nevermarried, Separated, Widowed, Married-spouse-absent, Married-AF-spouse. • 7-occupation: • 8-relationship: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried. Copyright © Andrew W. Moore Slide 40 Variables en Census • 9-race: White, Asian-Pac-Islander, AmerIndian-Eskimo, Other, Black. • 10-sex: Female[0], Male[1]. • 11-capital-gain: continuous. • 12-capital-loss: continuous. • 13-hours-per-week: continuous. • 14-native-country: nominal • 15 Salary: >50K (rich)[2], <=50K (poor)[1]. Copyright © Andrew W. Moore Slide 41 Primeros datos de census(train) > traincensus[1:5,] age workcl fwgt educ 1 39 6 77516 13 2 50 2 83311 13 3 38 1 215646 9 4 53 1 234721 7 5 28 1 338409 13 country salary 1 1 1 2 1 1 3 1 1 4 1 1 5 13 1 > Copyright © Andrew W. Moore educn 13 13 9 7 13 marital occup 3 9 4 1 5 3 2 7 4 1 7 3 1 6 1 relat race sex gain loss hpwk 1 1 2174 0 40 1 1 0 0 13 1 1 0 0 40 5 1 0 0 40 5 0 0 0 40 Slide 42 Calculando frecuencias para sexo > countsex=table(traincensus$sex) > probsex=countsex/32561 > countsex 0 1 10771 21790 > probsex 0 1 0.3307945 0.6692055 > Copyright © Andrew W. Moore Slide 43 Calculando las probabilidades conjuntas > jdcensus=traincensus[,c(10,13,15)] > dim(jdcensus) [1] 32561 3 > jdcensus[1:3,] sex hpwk salary 1 1 40 1 2 1 13 1 3 1 40 1 > dim(jdcensus[jdcensus$sex==0 &jdcensus$hpwk<=40.5 &jdcensus$salary==1,])[1] [1] 8220 > dim(jdcensus[jdcensus$sex==0 &jdcensus$hpwk<=40.5 &jdcensus$salary==1,])[1]/dim(jdcensus)[1] [1] 0.2524492 > dim(jdcensus[jdcensus$sex==0 &jdcensus$hpwk<=40.5 &jdcensus$salary==2,])[1]/dim(jdcensus)[1] [1] 0.02484567 Copyright © Andrew W. Moore Slide 44 > dim(jdcensus[jdcensus$sex==0 &jdcensus$hpwk>40.5 &jdcensus$salary==1,])[1]/dim(jdcensus)[1] [1] 0.0421363 > dim(jdcensus[jdcensus$sex==0 &jdcensus$hpwk>40.5 &jdcensus$salary==2,])[1]/dim(jdcensus)[1] [1] 0.01136329 > dim(jdcensus[jdcensus$sex==1 &jdcensus$hpwk<40.5 &jdcensus$salary==1,])[1]/dim(jdcensus)[1] [1] 0.3309174 > dim(jdcensus[jdcensus$sex==1 &jdcensus$hpwk<=40.5 &jdcensus$salary==2,])[1]/dim(jdcensus)[1] [1] 0.09754 > dim(jdcensus[jdcensus$sex==1 &jdcensus$hpwk>40.5 &jdcensus$salary==1,])[1]/dim(jdcensus)[1] [1] 0.1336875 > dim(jdcensus[jdcensus$sex==1 &jdcensus$hpwk>40.5 &jdcensus$salary==2,])[1]/dim(jdcensus)[1] [1] 0.1070606 Copyright © Andrew W. Moore Slide 45 Using the Joint One you have the JD you can ask for the probability of any logical expression involving your attribute Copyright © Andrew W. Moore P( E ) P(row ) rows matching E Slide 46 Using the Joint P(Poor Male) = 0.4654 P( E ) P(row ) rows matching E Copyright © Andrew W. Moore Slide 47 Using the Joint P(Poor) = 0.7604 P( E ) P(row ) rows matching E Copyright © Andrew W. Moore Slide 48 Inference with the Joint P( E1 E2 ) P( E1 | E2 ) P ( E2 ) P(row ) rows matching E1 and E2 P(row ) rows matching E2 Copyright © Andrew W. Moore Slide 49 Inference with the Joint P( E1 E2 ) P( E1 | E2 ) P ( E2 ) P(row ) rows matching E1 and E2 P(row ) rows matching E2 P(Male | Poor) = 0.4654 / 0.7604 = 0.612 Copyright © Andrew W. Moore Slide 50 Inferencia es un asunto importante • Tengo esta evidencia, cual es la probabilidad de que esta conclusion sea cierta? • Tengo la nuca hinchada: Cual es la probabilidad de que tenga meningitis? • Veo luces en mi casa y son las 9pm. Cual es la probabilidad de que mi esposa ya se haya quedado dormida? • Hay bastante aplicaciones de Inferencia Bayesiana en Medicina, Farmacia, Diagnostico de Falla de Maquinas, etc. Copyright © Andrew W. Moore Slide 51 Where do Joint Distributions come from? • Idea One: Expert Humans • Idea Two: Simpler probabilistic facts and some algebra Example: Suppose you knew P(A) = 0.7 P(C|A^B) = 0.1 P(C|A^~B) = 0.8 P(B|A) = 0.2 P(C|~A^B) = 0.3 P(B|~A) = 0.1 P(C|~A^~B) = 0.1 Then you can automatically compute the JD using the chain rule P(A=x ^ B=y ^ C=z) = P(C=z|A=x^ B=y) P(B=y|A=x) P(A=x) Copyright © Andrew W. Moore In another lecture: Bayes Nets, a systematic way to do this. Slide 52 Where do Joint Distributions come from? • Idea Three: Learn them from data! Prepare to see one of the most impressive learning algorithms you’ll come across in the entire course…. Copyright © Andrew W. Moore Slide 53 Learning a joint distribution Build a JD table for your attributes in which the probabilities are unspecified The fill in each row with records matching row ˆ P(row ) total number of records A B C Prob 0 0 0 ? 0 0 1 ? A B C Prob 0 1 0 ? 0 0 0 0.30 0 1 1 ? 0 0 1 0.05 1 0 0 ? 0 1 0 0.10 1 0 1 ? 0 1 1 0.05 1 1 0 ? 1 0 0 0.05 1 1 1 ? 1 0 1 0.10 1 1 0 0.25 1 1 1 0.10 Fraction of all records in which A and B are True but C is False Copyright © Andrew W. Moore Slide 54 Example of Learning a Joint • This Joint was obtained by learning from three attributes in the UCI “Adult” Census Database [Kohavi 1995] Copyright © Andrew W. Moore Slide 55 Where are we? • We have recalled the fundamentals of probability • We have become content with what JDs are and how to use them • And we even know how to learn JDs from data. Copyright © Andrew W. Moore Slide 56 Density Estimation • Our Joint Distribution learner is our first example of something called Density Estimation • A Density Estimator learns a mapping from a set of attributes to a Probability Input Attributes Copyright © Andrew W. Moore Density Estimator Probability Slide 57 Density Estimation • Comparado con los otros dos modelos principales: Input Attributes Classifier Prediction of categorical output Input Attributes Density Estimator Probability Input Attributes Regressor Prediction of real-valued output Copyright © Andrew W. Moore Slide 58 Evaluacion de la estimacion de densidad Test-set criterion for estimating performance on future data* * See the Decision Tree or Cross Validation lecture for more detail Input Attributes Classifier Prediction of categorical output Test set Accuracy Input Attributes Density Estimator Probability ? Input Attributes Regressor Prediction of real-valued output Test set Accuracy Copyright © Andrew W. Moore Slide 59 Evaluating a density estimator • Given a record x, a density estimator M can tell you how likely the record is: Pˆ ( x|M ) • Given a dataset with R records, a density estimator can tell you how likely the dataset is: (Under the assumption that all records were independently generated from the Density Estimator’s JD) R Pˆ (dataset |M ) Pˆ (x1 x 2 x R|M ) Pˆ (x k|M ) k 1 Copyright © Andrew W. Moore Slide 60 The Auto-mpg dataset Donor: Quinlan,R. (1993) Number of Instances: 398 minus 6 missing=392 (training: 196 test: 196): Number of Attributes: 9 including the class attribute7. Attribute Information: 1. mpg: continuous (discretizado bad<=25,good>25) 2. cylinders: multi-valued discrete 3. displacement: continuous (discretizado low<=200, high>200) 4. horsepower: continuous ((discretizado low<=90, high>90) 5. weight: continuous (discretizado low<=3000, high>3000) 6. acceleration: continuous (discretizado low<=15, high>15) 7. model year: multi-valued discrete (discretizado 70-74,75-77,78-82 8. origin: multi-valued discrete 9. car name: string (unique for each instance) Note: horsepower has 6 missing values Copyright © Andrew W. Moore Slide 61 The auto-mpg dataset 18.0 8 307.0 130.0 3504. 12.0 70 1 "chevrolet chevelle malibu" 15.0 8 350.0 165.0 3693. 11.5 70 1 "buick skylark 320" 18.0 8 318.0 150.0 3436. 11.0 70 1 "plymouth satellite" 16.0 8 304.0 150.0 3433. 12.0 70 1 "amc rebel sst" 17.0 8 302.0 140.0 3449. 10.5 70 1 "ford torino" ………………………………………………………………….. 27.0 4 140.0 86.00 2790. 15.6 82 1 "ford mustang gl" 44.0 4 97.00 52.00 2130. 24.6 82 2 "vw pickup" 32.0 4 135.0 84.00 2295. 11.6 82 1 "dodge rampage" 28.0 4 120.0 79.00 2625. 18.6 82 1 "ford ranger" 31.0 4 119.0 82.00 2720. 19.4 82 1 "chevy s-10" Copyright © Andrew W. Moore Slide 62 A subset of auto-mpg levelmpg modelyear maker [1,] "bad" "70-74" "america" [2,] "bad" "70-74" "america" [3,] "bad" "70-74" "america" [4,] "bad" "70-74" "america" [5,] "bad" "70-74" "america" [6,] "bad" "70-74" "america“ ……………………………………………… …………………………………………….. [7,] "good" "78-82" "america" [8,] "good" "78-82" "europe" [9,] "good" "78-82" "america" [10,] "good" "78-82" "america" [11,] "good" "78-82" "america" Copyright © Andrew W. Moore Slide 63 Mpg: Train test and test set indices_samples=sample(1:392,196) mpgtrain=smallmpg[indices_samples,] dim(mpgtrain) [1] 196 3 mpgtest=smallmpg[-indices_samples,] #computing the first joint probability a1=dim(mpgtrain[mpgtrain[,1]=="bad" & mpgtrain[,2]=="70-74" & mpgtrain[,3]=="america",])[1]/192 Copyright © Andrew W. Moore Slide 64 The joint density estimate levelmpg modelyear maker probability bad 70-74 America 0.2397959 bad 70-74 Asia 0.01530612 Bad 70-74 Europe 0.03061224 Bad 75-77 America 0.2091837 Bad 75-77 Asia 0.01020408 Bad 75-77 Europe 0.04591837 Bad 78-82 America 0.04591837 Bad 78-82 Asia Bad 78-82 Europe 0 Good 70-74 America 0.02040816 Good 70-74 Asia 0.01530612 Good 70-74 Europe 0.03061224 Good 75-77 America 0.04081633 Good 75-77 Asia 0.04081633 Good 75-77 Europe 0.02551020 Good 78-82 America 0.1071429 Good 78-82 Asia 0.07142857 Good 78-82 Europe 0.04591837 Copyright © Andrew W. Moore 0.005102041 Slide 65 196 Pˆ (mpgtest |M ) Pˆ (x1 x 2 x196|M ) Pˆ (x k|M ) (in this case) 1.45 10-222 k 1 This probability has been computed considering that any joint probability is at least greater than 1/1020=10-20 Copyright © Andrew W. Moore Slide 66 A small dataset: Miles Per Gallon 192 Training Set Records mpg modelyear maker good bad bad bad bad bad bad bad : : : bad good bad good bad good good bad good bad 75to78 70to74 75to78 70to74 70to74 70to74 70to74 75to78 : : : 70to74 79to83 75to78 79to83 75to78 79to83 79to83 70to74 75to78 75to78 asia america europe america america asia asia america : : : america america america america america america america america europe europe From the UCI repository (thanks to Ross Quinlan) Copyright © Andrew W. Moore Slide 67 A small dataset: Miles Per Gallon 192 Training Set Records Copyright © Andrew W. Moore mpg modelyear maker good bad bad bad bad bad bad bad : : : bad good bad good bad good good bad good bad 75to78 70to74 75to78 70to74 70to74 70to74 70to74 75to78 : : : 70to74 79to83 75to78 79to83 75to78 79to83 79to83 70to74 75to78 75to78 asia america europe america america asia asia america : : : america america america america america america america america europe europe Slide 68 A small dataset: Miles Per Gallon 192 Training Set Records mpg modelyear maker good bad bad bad bad bad bad bad : : : bad good bad good bad good good bad good bad 75to78 70to74 75to78 70to74 70to74 70to74 70to74 75to78 : : : 70to74 79to83 75to78 79to83 75to78 79to83 79to83 70to74 75to78 75to78 asia america europe america america asia asia america : : : america 1 america america america america america america america europe europe 196 Pˆ (dataset /|M ) Pˆ (x x 2 x196|M ) Pˆ (x k|M ) (in this case) 3.4 10 k 1 -203 Dataset puede ser mpgtrain o mpgtest Copyright © Andrew W. Moore Slide 69 Log Probabilities Since probabilities of datasets get so small we usually use log probabilities R R k 1 k 1 log Pˆ (dataset |M ) log Pˆ (x k|M ) log Pˆ (x k|M ) Copyright © Andrew W. Moore Slide 70 A small dataset: Miles Per Gallon 192 Training Set Records mpg modelyear maker good bad bad bad bad bad bad bad : : : bad good bad good bad good good bad good bad 75to78 70to74 75to78 70to74 70to74 70to74 70to74 75to78 : : : 70to74 79to83 75to78 79to83 75to78 79to83 79to83 70to74 75to78 75to78 asia america europe america america asia asia america : : : america america america america america america america america europe europe R R k 1 k 1 log Pˆ (dataset |M ) log Pˆ (x k|M ) log Pˆ (x k|M ) (in this case) 466.19 In our case= -510.79 Copyright © Andrew W. Moore Slide 71 Resumen: The Good News • Hemos visto una manera de aprender un estimador de densidad a partir de datos. • Estimadores de densidad pueden ser usados para • Ordenar los records segun la probabilidad, y detectar asi casos anomalos (“outliers”). • Para hacer inferencia: calcular P(E1|E2) • Para calcular clasificadores Bayesianos (se vera mas tarde). Copyright © Andrew W. Moore Slide 72 Summary: The Bad News • Density estimation by directly learning the joint is trivial, mindless and dangerous Copyright © Andrew W. Moore Slide 73 Using a test set An independent test set with 196 cars has a worse log likelihood (actually it’s a billion quintillion quintillion quintillion quintillion times less likely) ….Density estimators can overfit. And the full joint density estimator is the overfittiest of them all! Copyright © Andrew W. Moore Slide 74 Overfitting Density Estimators If this ever happens, it means there are certain combinations that we learn are impossible R R k 1 k 1 log Pˆ ( testset |M ) log Pˆ (x k|M ) log Pˆ (x k|M ) if for any k Pˆ (x k|M ) 0 Copyright © Andrew W. Moore Slide 75 Using a test set The only reason that our test set didn’t score -infinity is that my code is hard-wired to always predict a probability of at least one in 1020 We need Density Estimators that are less prone to overfitting Copyright © Andrew W. Moore Slide 76 Naïve Density Estimation El problema con el estimador de densidad conjunto es que simplemente refleja la muestra de entrenamiento. Necesitamos algo que generalize en forma mas util. El modelo naïve model generaliza mas eficientemente: Asume que cada atributo esta distribuido independientemente uno del otro. Copyright © Andrew W. Moore Slide 77 A note about independence • Assume A and B are Boolean Random Variables. Then “A and B are independent” if and only if P(A|B) = P(A) • “A and B are independent” is often notated as AB Copyright © Andrew W. Moore Slide 78 Independence Theorems • Assume P(A|B) = P(A) • Then P(A^B) = P(A/B)=P(A^B)/P(B) Por Independencia, P(A)=P(A^B)/P(B) = P(A) P(B) Copyright © Andrew W. Moore • Assume P(A|B) = P(A) • Then P(B|A) = P(A^B)/P(A) • Por el resultado anterior • P(B/A)=P(A)P(B)/P(A) = P(B) Slide 79 Independence Theorems • • • • • • • Assume P(A|B) = P(A) Then P(~A|B) = P(~A^B)/P(B)= [P(B)-P(A^B)]/P(B) 1-P(A^B)/P(B)= 1-P(A), por Indep. P(~A) = P(~A) Copyright © Andrew W. Moore • • • • • • Assume P(A|B) = P(A) Then P(A|~B) = P(A^~B)/P(~B) [P(A)-P(A^B)]/1-P(B) P(A)-P(A)P(B)/1-P(B) P(A)[1-P(B)]/1-P(B) = P(A) Slide 80 Multivalued Independence For multivalued Random Variables A and B, AB if and only if u, v : P( A u | B v) P( A u ) from which you can then prove things like… u, v : P( A u B v) P( A u ) P( B v) u, v : P( B v | A u ) P( B v) Copyright © Andrew W. Moore Slide 81 Independently Distributed Data • Let x[i] denote the i’th field of record x. • The independently distributed assumption says that for any i,v, u1 u2… ui-1 ui+1… uM P( x[i ] v | x[1] u1 , x[2] u2 , x[i 1] ui 1 , x[i 1] ui 1 , x[ M ] u M ) P( x[i ] v) • Or in other words, x[i] is independent of {x[1],x[2],..x[i-1], x[i+1],…x[M]} • This is often written as x[i ] {x[1], x[2], x[i 1], x[i 1], x[ M ]} Copyright © Andrew W. Moore Slide 82 Back to Naïve Density Estimation • • • Let x[i] denote the i’th field of record x: Naïve DE assumes x[i] is independent of {x[1],x[2],..x[i-1], x[i+1],…x[M]} Example: • Suppose that each record is generated by randomly shaking a green dice and a red dice • Dataset 1: A = red value, B = green value • Dataset 2: A = red value, B = sum of values • Dataset 3: A = sum of values, B = difference of values • Which of these datasets violates the naïve assumption? Copyright © Andrew W. Moore Slide 83 Using the Naïve Distribution • Once you have a Naïve Distribution you can easily compute any row of the joint distribution. • Suppose A, B, C and D are independently distributed. What is P(A^~B^C^~D)? Copyright © Andrew W. Moore Slide 84 Using the Naïve Distribution • Once you have a Naïve Distribution you can easily compute any row of the joint distribution. • Suppose A, B, C and D are independently distributed. What is P(A^~B^C^~D)? = P(A|~B^C^~D) P(~B^C^~D) = P(A) P(~B^C^~D) = P(A) P(~B|C^~D) P(C^~D) = P(A) P(~B) P(C^~D) = P(A) P(~B) P(C|~D) P(~D) = P(A) P(~B) P(C) P(~D) Copyright © Andrew W. Moore Slide 85 Naïve Distribution General Case • Suppose x[1], x[2], … x[M] are independently distributed. M P( x[1] u1 , x[2] u2 , x[ M ] u M ) P( x[k ] uk ) k 1 • So if we have a Naïve Distribution we can construct any row of the implied Joint Distribution on demand. • So we can do any inference • But how do we learn a Naïve Density Estimator? Copyright © Andrew W. Moore Slide 86 Learning a Naïve Density Estimator # records in which x[i ] u ˆ P( x[i ] u ) total number of records Another trivial learning algorithm! Copyright © Andrew W. Moore Slide 87 Conparacion Joint DE Naïve DE Can model anything Can model only very boring distributions Puede modelar una copia No lo puede hacer ruidosa de la muestra original Given 100 records and more than 6 Given 100 records and 10,000 Boolean attributes will screw up multivalued attributes will be fine badly Copyright © Andrew W. Moore Slide 88 Empirical Results: “MPG” The “MPG” dataset consists of 392 records and 8 attributes A tiny part of the DE learned by “Joint” The DE learned by “Naive” Copyright © Andrew W. Moore Slide 89 Empirical Results: “MPG” The “MPG” dataset consists of 392 records and 8 attributes A tiny part of the DE learned by “Joint” The DE learned by “Naive” Copyright © Andrew W. Moore Slide 90 Empirical Results: “Weight vs. MPG” Suppose we train only from the “Weight” and “MPG” attributes The DE learned by “Joint” Copyright © Andrew W. Moore The DE learned by “Naive” Slide 91 Empirical Results: “Weight vs. MPG” Suppose we train only from the “Weight” and “MPG” attributes The DE learned by “Joint” Copyright © Andrew W. Moore The DE learned by “Naive” Slide 92 “Weight vs. MPG”: The best that Naïve can do The DE learned by “Joint” Copyright © Andrew W. Moore The DE learned by “Naive” Slide 93 Reminder: The Good News • Tenemos dos maneras de aprender un estimador de densidad a partir de datos. • *In otras clases veremos estimadores de densidad mas complicados. (Mixture Models, Bayesian Networks, Density Trees, Kernel Densities and many more) • Los estimadores de densidad pueden ser usados para: • Deteccion de anomalias (“outliers”). • Para ser inferencias: Calcular P(E1|E2) • Para calcular clasificadores bayesianos. Copyright © Andrew W. Moore Slide 94