Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
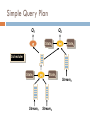
Data Stream load shedding by Sampling (CS2650) Taecheol Oh Introduction Many data stream sources are prone to dramatic spikes in volume An overloaded system will be unable to process all of its input data So, discarding some fraction of the unprocessed data, becomes necessary in order for the system to continue to provide up-to-date query response Sampling Degrade gracefully by providing approximate answers during load spikes With a basic statistics on the distribution of values, guarantee on the accuracy of queries for a given sampling rate Semantic of sample SAMPLE(R,f): produce a uniform random sample of R that contains a f fraction of the tuples in R Sampling with Replacement (WR) Sample fn tuples, uniformly and independently from R Specific tuples could be sampled multiple times Sampling without Replacement (WoR) Sample fn distinct tuples from R Independent Coin Flips (CF) For each tuple in R, choose it for the sample with probability of f, independent of other tuples, B(n,f) Density Preserving Sampling Suppose that we have N values x1, x2, …, xN Partitioned into groups that have sizes n1,n2,…,ng The expected sum of the weights of the sampled points for each group is proportional to the group’s size Experiments STREAM ( Stanford stREam datA Manager ) A general purpose data stream management system Traditional DBMS is for running one time queries over finite stored data sets In applications, data takes the form of continuous data streams rather than finite data sets In the STREAM project, consider data management and query processing in the presence of multiple continuous, rapid, time-varying data streams Abstract Semantics The abstract semantics is based on two data types Steam Stream: an unbounded bag of pairs <s,t> s: and Relations a tuple, t: time stamp, the logical arrival time Relation: a bag of tuples at time t. an instantaneous relation Stream-to-Rlation Streams Relations Rlation-to-Stream Relation-to-Relation Query Execution When a continuous query is registered with the system, generate a query execution plan Plans composed of three main components: Operators Queues (input and inter-operator) State (windows, history) Global scheduler for plan execution Simple Query Plan Q1 Q2 State3 ⋈ State4 Scheduler State1 Stream1 ⋈ State2 Stream2 Stream3 Overview of Approach Unweighted sampling vs Weighted sampling Unweighted sampling Each element is sampled uniformly at random Algorithm i0 While tuples are streaming by and M > 0 do get tuple ti generate random variable X from B(x, 1/n-i) MM–X ii+1 Overview of Approach Weighted sampling Each element is sampled with a probability proportional to its weight Algorithm i 0, W Sum of weights, D 0 While tuples are streaming by and M > 0 do get tuple ti with weight generate random variable X from B(x, weight/W-D) MM–X D D + weight of the tuple ii+1 Overview of Approach Weighted sampling considering the density queue operator Overview of Approach Weighted sampling considering the density queue operator Density measure +1 - - - - - - W, Z, Z, X, Y, X Mapping function Bit map / counter Weighted sampling controller Thanks