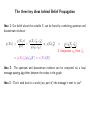Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
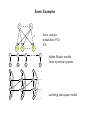
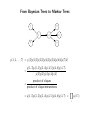
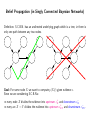
Statistical Approaches to Learning and Discovery Graphical Models Zoubin Ghahramani & Teddy Seidenfeld [email protected] & [email protected] CALD / CS / Statistics / Philosophy Carnegie Mellon University Spring 2002 Some Examples XK X1 Λ Y1 Y2 factor analysis probabilistic PCA ICA YD X1 X2 X3 XT Y1 Y2 Y3 YT hidden Markov models linear dynamical systems U1 U2 U3 S1 S2 S3 X1 X2 X3 Y1 Y2 Y3 switching state-space models Markov Networks (Undirected Graphical Models) B A Examples: Boltzmann Machines Markov Random Fields C D E Semantics: Every node is conditionally independent from its non-neighbors given its neighbors. Conditional Independence: X⊥ ⊥Y |V ⇔ p(X|Y, V ) = p(X|V ) when p(Y, V ) > 0. also X⊥ ⊥Y |V ⇔ p(X, Y |V ) = p(X|V )p(Y |V ). Markov Blanket: V is a Markov Blanket for X iff X⊥ ⊥Y |V for all Y ∈ / V. Markov Boundary: minimal Markov Blanket Clique Potentials and Markov Networks Definition: a clique is a fully connected subgraph (usually maximal). Ci will denote the set of variables in the ith clique. B A C D E 1. Identify cliques of graph G 2. For each clique Ci assign a non-negative function gi(Ci) which measures “compatibility”. Q P Q 3. p(X1, . . . , Xn) = Z1 i gi(Ci) where Z = X1···Xn i gi(Ci) is the normalization The graph G embodies the conditional independencies in p (i.e. G is a Markov Field relative to p): If V lies in all paths between X and Y in G, then X⊥ ⊥Y |V . Hammersley–Clifford Theorem (1971) Theorem: A probability function p formed by a normalized product of positive functions on cliques of G is a Markov Field relative to G. Definition: The graph G is a Markov Field relative to p if it does not imply any conditional independence relationships that are not true in p. (We are usually interested in the minimal such graph.) Proof: We need to show that the neighbors of X, ne(X) are a Markov Blanket for X: Y 1Y 1 Y p(X, Y, . . .) = gi(Ci) = gi(Ci) gj (Cj ) Z i Z i:X∈Ci j:X ∈C / j 1 1 = f1 X, ne(X) f2 ne(X), Y = 0 p(X| ne(X)) p(Y | ne(X)) Z Z This shows that: p(X, Y | ne(X)) = p(X| ne(X)) p(Y | ne(X)) ⇔ X⊥ ⊥Y | ne(X). Problems with Markov Networks Many useful independencies are unrepresented — two variables are connected merely because some other variable depends on them: Rain Sprinkler Rain Ground wet Marginal independence vs. conditional independence. “Explaining Away” Sprinkler Ground wet Bayesian Networks (Directed Graphical Models) B A C D E Semantics: X⊥ ⊥Y |V if V d-separates X from Y . Definition: V d-separates X from Y if along every undirected path between X and Y there is a node W such that either: 1. W has converging arrows along the path (→ W ←) and neither W nor its descendants are in V , or 2. W does not have converging arrows along the path (→ W →) and W ∈ V . The “Bayes-ball” algorithm. Corollary: Markov Blanket parents-of-children(X)}. for X: {parents(X) ∪ children(X) ∪ Bayesian Networks (Directed Graphical Models) B A C D E A Bayesian network corresponds to a factorization of the joint probability distribution: p(A, B, C, D, E) = p(A)p(B)p(C|A, B)p(D|B, C)p(E|C, D) In general: p(X1, . . . , Xn) = n Y i=1 where pa(i) are the parents of node i. p(Xi|Xpa(i)) From Bayesian Trees to Markov Trees 1 5 3 2 4 6 7 p(1, 2, . . . , 7) = p(3)p(1|3)p(2|3)p(4|3)p(5|4)p(6|4)p(7|4) p(1, 3)p(2, 3)p(3, 4)p(4, 5)p(4, 6)p(4, 7) = p(3)p(3)p(4)p(4)p(4) product of cliques = product of clique intersections = g(1, 3)g(2, 3)g(3, 4)g(4, 5)g(4, 6)g(4, 7) = Y i gi(Ci) Belief Propagation (in Singly Connected Bayesian Networks) Definition: S.C.B.N. has an undirected underlying graph which is a tree, ie there is only one path between any two nodes. Goal: For some node X we want to compute p(X|e) given evidence e. Since we are considering S.C.B.N.s: − • every node X divides the evidence into upstream e+ and downstream e X X + • every arc X → Y divides the evidence into upstream eXY and downstream e− XY . The three key ideas behind Belief Propagation Idea 1: Our belief about the variable X can be found by combining upstream and downstream evidence: − p(X, e+ , e p(X, e) + X X) p(X|e) = = ∝ p(X|e X) + − p(e) p(eX , eX ) p(e− |X, e+ ) X | {z X} + X d-separates e− X from eX × − = p(X|e+ )p(e X X |X) = π(X)λ(X) Idea 2: The upstream and downstream evidence can be computed via a local message passing algorithm between the nodes in the graph. Idea 3: “Don’t send back to a node (any part of) the message it sent to you!” Belief Propagation U1 ...... top-down causal support: πX (Ui) = p(Ui|e+ Ui X ) Un X bottom-up diagnostic support: λYj (X) = p(e− XYj |X) Y1 ...... Ym To update the belief about X: 1 BEL(X) = λ(X)π(X) Z Y λ(X) = λYj (X) j π(X) = X U1 ···Un p(X|U1, . . . , Un) Y i πX (Ui) Belief Propagation, cont U1 ...... top-down causal support: πX (Ui) = p(Ui|e+ Ui X ) Un X bottom-up diagnostic support: λYj (X) = p(e− XYj |X) Y1 ...... Ym Bottom-up propagation, X sends to Ui: X Y 1X λX (Ui) = λ(X) p(X|U1, . . . , Un) πX (Uk ) Z X Uk :k6=i k6=i Top-down propagation, X sends to Yj : Y X 1 BEL(X) 1Y πYj (X) = λYk (X) p(X|U1, . . . , Un) πX (Ui) = Z Z λYj (X) i k6=j U1 ···Un Belief Propagation in multiply connected Bayesian Networks The Junction Tree algorithm: Form an undirected graph from your directed graph such that no additional conditional independence relationships have been created (this step is called “moralization”). Lump variables in cliques together and form a tree of cliques—this may require a nasty step called “triangulation”. Do inference in this tree. Cutset Conditioning: or “reasoning by assumptions”. Find a small set of variables which, if they were given (i.e. known) would render the remaining graph singly connected. For each value of these variables run belief propagation on the singly connected network. Average the resulting beliefs with the appropriate weights. Loopy Belief Propagation: just use BP although there are loops. In this case the terms “upstream” and “downstream” are not clearly defined. No guarantee of convergence, but often works well in practice. Learning with Hidden Variables: The EM Algorithm θ1 X1 θ3 θ2 X3 X2 θ4 Y Assume a model parameterised by θ with observable variables Y and hidden variables X Goal: maximise log likelihood of observables. L(θ) = ln p(Y |θ) = ln X p(Y, X|θ) X • E-step: first infer p(X|Y, θold), then • M-step: find θnew using complete data learning The E-step requires solving the inference problem: finding explanations, X, for the data, Y , given the current model, θ (using e.g. BP). Expressive Power of Bayesian and Markov Networks No Bayesian network can represent these and only these independencies No matter how we direct the arrows there will always be two non-adjacent parents sharing a common child =⇒ dependence in Bayesian network but independence in Markov network. No Markov network can represent these and only these independencies