Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
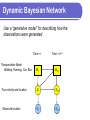
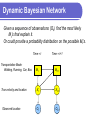
Probabilistic Databases Amol Deshpande, University of Maryland Overview V.S. Subrahmanian Lise Getoor ProbView, PXML, Temporal Probabilistic Databases, Probabilistic Aggregates Statistical Relational Learning, Probabilistic Relational Models, Entity Resolution Amol MauveDB: Statistical Modeling in Databases, Correlated tuples in probabilistic databases Overview of Today’s Presentation Model-based Views/MauveDB [Amol] Statistical Relational Learning [Lise] Representing arbitrarily correlated data and processing queries over it [Prithviraj] Overview of Today’s Presentation Model-based Views/MauveDB [Amol] Goal: Making it easy to continuously apply statistical models to streaming data Current focus on designing declarative interfaces, and on efficient maintenance algorithms Less on the “probabilistic databases” issues Statistical Relational Learning [Lise] Representing arbitrarily correlated data and processing queries over it [Prithviraj] Motivation Unprecedented, and rapidly increasing, Wireless sensor networks instrumentation of our every-day world Huge data volumes generated continuously that must be processed in real-time Typically imprecise, unreliable and incomplete Distributed measurement networks (e.g. GPS) data Measurement noises, low success rates, failures etc… RFID Industrial Monitoring Data Processing Step 1 Process data using a statistical/probabilistic model Regression and interpolation models To eliminate spatial or temporal biases, handle missing data, prediction Filtering techniques (e.g. Kalman Filters), Bayesian Networks To eliminate measurement noise, to infer hidden variables etc Temperature monitoring Regression/interpolation models GPS Data Kalman Filters et A Motivating Example Inferring “transportation mode”/ “activities” [Henry Kautz et al] Using easily obtainable sensor data, e.g. GPS, RFID proximity data Can do much if we can infer these automatically home office Have access to noisy “GPS” data Infer the transportation mode: walking, running, in a car, in a bus Motivating Example Inferring “transportation mode”/ “activities” [Henry Kautz et al] Using easily obtainable sensor data, e.g. GPS, RFID proximity data Can do much if we can infer these automatically home office Preferred end result: Clean path annotated with transportation mode Dynamic Bayesian Network Use a “generative model” for describing how the observations were generated Time = t Transportation Mode: Walking, Running, Car, Bus Mt True velocity and location Xt Need conditional probability distributions e.g. a distribution on (velocity, location) given the transportation mode Prior knowledge or learned from data Observed location Ot Dynamic Bayesian Network Use a “generative model” for describing how the observations were generated Time = t Time = t+1 Transportation Mode: Walking, Running, Car, Bus Mt Mt+1 True velocity and location Xt Xt+1 Ot Ot+1 Observed location Dynamic Bayesian Network Given a sequence of observations (Ot), find the most likely Mt’s that explain it. Or could provide a probability distribution on the possible Mt’s. Time = t Time = t+1 Transportation Mode: Walking, Running, Car, Bus Mt Mt+1 True velocity and location Xt Xt+1 Ot Ot+1 Observed location Statistical Modeling of Sensor Data No support in database systems --> Database ends up being used as a backing store With much replication of functionality Very inefficient, not declarative… How can we push statistical modeling inside a database system ? Abstraction: Model-based Views An abstraction analogous to traditional database views Present the output of the application of model as a database view That the user can query as with normal database views Example DBN View User User Time Location Mode prob John 5pm (x’1, y’1) Walking 0.9 John 5pm (x’1, y’1) Car 0.1 John 5:05pm (x’2, y’2) Walking 0 John 5:05pm (x’2, y’2) Car 1 User Time Location John 5pm (x1, y1) John 5:05pm (x2, y2) User view of the data - Smoothed locations - Inferred variables e.g. select count(*) group by mode sliding window 5 minutes Application of the model/inference is pushed inside the database Opens up many optimization opportunities e.g. can do inference lazily when queried etc Original noisy GPS data Correlations User User Time Location Mode prob John 5pm (x’1, y’1) Walking 0.9 John 5pm (x’1, y’1) Car 0.1 John 5:05pm (x’2, y’2) Walking 0 John 5:05pm (x’2, y’2) Car 1 Strong and complex correlations across tuples - Mutual exclusivity - Temporal correlations MauveDB: Status Written in the Apache Derby Java open source database system Support for Regression- and Interpolation-based views Neither produce probabilistic data SIGMOD 2006 (w/ Sam Madden) Currently building support for views based on Dynamic Bayesian networks [Bhargav] Kalman Filters, HMMs etc Initial focus on the user interfaces and efficient inference Will generate probabilistic data; may not be able to do anything too sophisticated with it Research Challenges/Future Work Generalizing to arbitrary models ? Develop APIs for adding arbitrary models Try to minimize the work of the model developer Probabilistic databases Uncertain data with complex correlation patterns Query processing, query optimization View maintenance in presence of high-rate measurement streams Thanks !! Mauve == Model-based User Views