Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
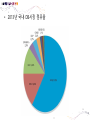
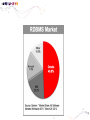
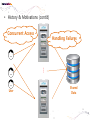
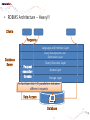
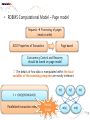
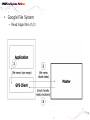
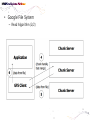
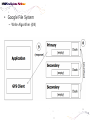
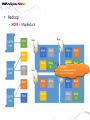
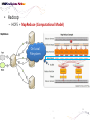
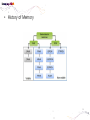
• Data Engineering Lab. has various efforts in the area of both data processing system technologies with modern hardware and bioinformatics based on data mining. • Dataware: Data-centric system over HW and SW. – Storing and processing data using novel memory storage • Tiering Data among DRAM, NVRAM, SSD and HDD – Cooperation between SW and storage: • In-storage processing and migrating recovery to storage SW layer. – Distributed processing on the faster networks: • Data placement and scheduling tasks of Hadoop stack on 10G networks. • Bioinformatics – Systems Biology Studies – Developing Tools for Bio-data Analysis • Our vision is to optimize typical data processing and management technologies for modern hardware and big data management. We also aim to research on various computational methods for omics data analysis and high-throughput biological data analysis. • Data Management Technologies with Modern Hardware • Big Data Management on Modern Hardware • Boosting Hadoop performance using NVRAM and SSD • Distributed graph processing • Optimizing Hadoop on 10G networks • Efficient page layout and file organization • Query processing and index structures • Column data store technologies • Data Processing in Solid State Drives • SSD guaranteeing ACID properties • In-Storage processing: filtering records in SSD Flash SSD RDBMS SQL-on-Hadoop Distributed processing NoSQL Graph parallel computation NVRAM NVMe PRAM NVDIMM PCIe Interface 10G Networks Multi-core CPUs Publications VLDB, ICDE, CIKM, Information Systems, etc. GPU Modern Hardware Projects SKTelecom, LG electronics, KISTI, etc Patents Dataware Technologies 11 applied (4 Int’l) patents 5 issued patents • • • • • • • • • Network Biology Graph Theory Machine Learning Data Integration Microarrays Protein Abundance Literature data Clinical data Somatic mutation data Research Goal Disease Analysis and Functional Genomics by Computational Approach Biological data Publications (~2016) Nucleic Acids Research, Bioinformatics, PLoS One, Information Sciences, ISMB, Informatics Sciences Molecular biosystems, Journal of biomedical Informatics, Computer Methods and Programs in biomedicine, etc. • Analysis and Visualization tools for Various Bio-data • 국내 RDBMS 시장 전망 – 2017년 약 6,000억원 • DB 라이선스 매출 및 유지보수 매출만 포함 6 • 2013년 국내 DB시장 점유율 • 글로벌 DB 시장 규모 – 2017년 500억 달러 (≒ 60조원) • DB 라이선스 매출 및 유지보수 매출만 포함 • History & Motivations – RDBMS • History & Motivations (cont’d) Concurrent Access Handling Failures … … User Shared Data • Transaction – Powerful abstraction concept which forms the “interface contract” between an application program and a transactional server Program Start Begin Transaction Application Lifecycle . . . Commit Transaction Program End Transaction Boundary • Transaction (cont’d) The core requirement on a DBMS is ACID guarantees for set of operations in the same transaction concurrency control component to guarantee the isolation properties of transactions, for both committed and aborted transactions recovery component to guarantee the atomicity and durability of transactions • RDBMS Architecture – Heavy!!! … Clients Requests Language and Interface Layer Database Server Query Decomposition and Optimization Layer Request execution threads Query Execution Layer Access Layer Storage Layer To facilitate disk I/O parallelism between different requests Data Access Database • RDBMS Architecture – How data is stored A page number A disk number + A physical address on disk by looking up an entry in an extent table and adding a relative offset Page Database usually has The minimum unit of data transfer a1)cretain amount of preallocated disk between disk memory space consists of and one main or more 2) The unit of caching in memory extents Each extent is a range of pages that are Slotcontiguous on disk = A page number + A slot number • RDBMS Computational Model – Page model Requests Processing of pages (read or write) ACID Properties of Transaction Page based Concurrency Control and Recovery should be based on page model ※ The details of how data is manipulated within the local variables of the executing programs are mostly irrelevant r(x) t = r(x)r(y)r(z)w(u)w(x) Parallelized transaction execution Partial Order r(y) w(u) r(z) w(x) • Needs for huge data from Google – – – – – – More than 15,000 commodity-class PC's Multiple clusters distributed worldwide Thousands of queries served per second One query reads 100's of MB of data One query consumes 10's of billions of CPU cycles Google stores dozens of copies of the entire Web! Conclusion: Need large, distributed, highly fault tolerant file system Traditional DBMS cannot tolerate • Problems of RDBMS – RDBMS’s clustering Data Copy Cost Transaction Maintain cost Performance does not increase as we expected • Problems of RDBMS – Scale-up vs Scale-out (Cost perspective) 인텔 제온 E52697V3 (하스웰-EP) 인텔(소켓2011-V3) / 테트라데카(14) 코어 / 쓰레드 28개 / 64(32)비트 / 2.6GHz / DDR4 / PCI-Express 40개 레인 \3,400,000 \250,000 인텔 코어i5-6세대 6600 (스카이레이크) 인텔(소켓1151) / DDR4 / DDR3L / 64 비트 / 쿼드 코어 / 쓰레드 4개 / 3.3GHz / 인텔 HD 530 / PCI-Express 16개 레인 • Google File System – Beginning of the big data platforms – Affects to Hadoop – Chunk : Analogous to block, except larger (typically 64MB) • Google File System – Read Algorithm (1/2) • Google File System – Read Algorithm (2/2) • Google File System – Write Algorithm (1/4) • Google File System – Write Algorithm (2/4) • Google File System – Write Algorithm (3/4) • Google File System – Write Algorithm (4/4) • Hadoop – HDFS + MapReduce 128MB file (e.g. /data/hdfs/block1) on Local Filesystem • Hadoop – HDFS + MapReduce (Computational Model) On Local Filesystem • Gartner’s hype cycle 2012 • Gartner’s hype cycle 2013 • Gartner’s hype cycle 2014 • Gartner’s hype cycle 2015 – Big data dropped from cycle, Big data is now into practice • History of Memory • All flash array • All flash array • NVRAM • NVDIMM • Thank you