Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Ch6 The Standard Deviation as a Ruler
and the Normal Model
The effect of shifting and rescaling
Use shifting and rescaling to
standardize data
The normal model
Shifting and Rescaling Data
• Motivation
There are two major tests of readiness for college, the
ACT and the SAT. ACT scores are reported on a scale from
1 to 36. SAT scores are reported on a scale from 400 to
1600.
There are two students Tonya and Jermaine. Tonya
scores 1320 on the SAT, and Jermaine scores 28 on the
ACT. Assuming that both tests measure the same thing,
who has the better performance?
Shifting and Rescaling Data
• Shifting and Rescaling
Dataset 2: {2 ,3,
4}
+1
Dataset 1 : {1 ,2, 3}
×2
Dataset 3 : {2,4, 6}
Adding or subtracting a
constant to each value in a
dataset is called shifting.
Multiplying or dividing a
constant to each value in a
dataset is called rescaling.
Shifting and Rescaling Data
• Effects of shifting and rescaling on the data set
+1
X2
Type of
Measure
Measures of
location
Measures of
spread
Summary
Statistics
Dataset 2
{2,3,4}
Dataset 1
{1,2,3}
Dataset 3
{2,4,6}
Min
2
1
2
Q1
2
1
2
Median
3
2
4
Q3
4
3
6
Max
4
3
Mean
3
2
4
IQR
2
2
4
SD
1
1
2
+1
×2
6
Shifting and Rescaling Data
• Effects of shifting and rescaling on the data set
1) Shifting will make all the measures of location to be
shifted. However, the measures of spread will not be
shifted.
2) Rescaling will make both the measures of location and
the measure of spread to be rescaled.
Shifting and Rescaling Data
• Example:
For a given data set, we know its mean is 8 and its
standard deviation is 3. Now, if we transform the dataset
by
1) subtracting the mean value 8 from each data value,
and then
2) dividing the results from step 1) by the standard
deviation 3,
what would the mean and the standard deviation of the
new dataset be?
Answer: mean is 0, SD is 1.
(True for all data sets!)
z-score
• The process of the following two steps
step 1: (Shifting) subtract the mean from data values
and,
step 2: (Rescaling) divide the results from step 1 by the
standard deviation
is called standardization in Statistics.
• The standardized value is commonly denoted by letter z,
and it is called z-score.
• Formula for z-score:
x− x
z=
s
z-score
• Example:
Find the z-scores of the values in the following dataset.
{ 1 , 2, 3}
• Solution:
1) mean=2, SD=1
2) Standardization
Data value
Z-score
1
(1-2)/1= -1
2
(2-2)/1= 0
3
(3-2)/1= 1
z-score
• Interpretation of z-score
x− x
z=
s
1) z-score is a ruler by using the standard deviation as
the “unit”
2) z-score provides a measure of the distance between
the data value and the mean in the unit of standard
deviation
In the previous example,
Data
Z-score
Interpretation of z-score
1
(1-2)/1= -1
Data value 1 is 1 SD away below the mean
2
(2-2)/1= 0
Data value 2 is the same as the mean
3
(3-2)/1= 1
Data value 3 is 1 SD away above the mean
z-score
• Application of z-score
For the ACT and SAT test scores
ACT
Mean = 20.8
SD = 4.8
SAT
Mean = 1026
SD = 209
Tonya scores 1320 on the SAT, and Jermaine scores 28 on
the ACT. Assuming that both tests measure the same
thing, who has the better performance?
28 − 20.8
= 1.5
z-score of Jermaine=
4.8
z-score of Tonya = 1320 − 1026 = 1.41
209
Thus, Jermaine did a better job.
Example
Your Statistics teacher has announced that lower of your
two test scores will be dropped. You got a 90 on test 1 and
80 on test 2. You are all set to drop the 80 until she
announces that she grades “on curve”. She stadardized
the scores in order to decide which is the lower one. If the
mean on the first test was 88 with a standard deviaiton of
4 and the mean on the second was 75 with a standard
deviaition of 5, which one will be dropped?
Normal model
Consider the following distributions:
• the actual weight of 100 boxes of raisins labeled as
20oz
• the height of 1,000 college students
• the SAT scores of 5,00 high school graduates
• the ACT scores of 3,000 freshmen
Normal model
Normal model
Normal model
• Statisticians call this type of distribution, which has a
bell curve form, Normal distribution (model).
(1)
(2)
(3)
(2)
(3)
Characteristics:
(1) The Normal distribution
concentrates on and is
symmetric about the center.
(2) It decreases towards both
tails which indicates a small
tendency to generate
extremely small or large values.
(3) Both tails extend to infinity.
Normal model
• Characterization of Normal distributions
A normal distribution is determined by its center and
the spread.
Notation
Measure of Center
Mean
µ
Measure of spread
Standard deviation
σ
Each pair (µ,σ) determines a specific Normal
distribution.
We call (µ,σ) the parameters of a Normal distribution.
We denote the Normal distribution as N(µ,σ).
For example, N(2,5) represents the Normal
distribution with mean µ=2 and σ=5.
Normal model
• Interpretations of N(µ,σ)
Normal model
• Standard Normal distribution
Consider X~N(2,5)
X −µ X −2
Recall: z-scores Z =
have mean 0
=
σ
5
and SD 1.
After shifting and rescaling the shape of the
distribution is still a bell curve.
Therefore, we can conclude Z~N(0,1).
In generally, for any N(µ,σ) ,
Z=
X −µ
σ
~ N (0,1)
We call N(0,1) the standard Normal distribution.
Normal model
• Interpretations of N(µ,σ)
Mean µ locates at the center of the bell curve, i.e.,
the bell curve is symmetric about the mean µ.
The standard deviation σ indicates the spread in the
following way:
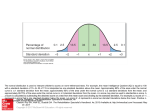
68%
95%
99.7%
µ − 3σ
µ µ +σ
σ
σ
2σ
2σ
µ − 2σ µ − σ
3σ
µ + 3σ
µ + 2σ
This is called the 68-95-99.7 Rule.
3σ
Normal model
• The 68-95-99.7 Rule.
Normal model
• Practice
Suppose data X~N(4,2),
1) Within which range would you expect to find the
central 68% of data?
2) Within which range would you expect to find the
central 95% of data?
3) Within which range would you expect to find the
central 99.7% of data?
Normal model
• Applications of the Normal distribution
Type I: Find the percentage under the normal curve
given the cut values
?
-1
0
Type II: Find the cut values (called percentiles) which
form the given percentage under the Normal curve
.90
0
?
Normal model
• Type I: Find the Percentage under the Normal Curve
Example: Suppose the data X~N(0,1). Then what
percent of data lie below -1?
68%
(by 68-95-99.7 Rule)
16%
?
-1
-1
+1
0
Normal model
• Type I: Find the Percentage under the Normal Curve
Example: Suppose the data X~N(0,1). Then what
percent of data lie below 1?
68%
16%
(by 68-95-99.7 Rule)
?
-1
? = 84%
+1
0
1
Normal model
• Type I: Find the Percentage under the Normal Curve
Example: Suppose the data X~N(0,1). Then what
percent of data lie below -0.71?
?
-0.71
0
Normal model
• Type I: Find the Percentage under the Normal Curve
Example: Suppose the data X~N(0,1). Then what
percent of data lie below -0.71?
We need to look up the standard normal table.
The table (table Z) is on page A-95 of the textbook.
Normal model
• The standard normal table
Normal model
• The standard normal table
Percentage (area)
to the left of the
cutoff value
The area on the left of -3.31
is 0.0005
Normal model
• The standard normal table
Find the percentage (area) to the left of -0.71
z
.00
.01
.02
− 0.8
.2119
.2090
.2061
− 0.7
.2420
.2389
.2358
− 0.6
.2743
.2709
.2676
Normal model
• Type I: Find the Percentage under the Normal Curve
Example: Suppose the data X~N(0,1). Then what
percent of data lie below -0.71?
.2389
-0.71
0
Normal model
• Type I: Find the Percentage under the Normal Curve
Example: Suppose the data X~N(0,1). Then what
percent of data lie above -0.71?
1−.2389 =
.2389
.7611
-0.71
0
Normal model
• Type I: Find the Percentage under the Normal Curve
Practice: Suppose the data X~N(0,1).
1) What percent of data lie below 0.8?
2) What percent of data lie above -1.2?
3) What percent of data lie between -1.2 and 0.8?
?
-1.2
0
0.8
Normal model
•
Type I: Find the Percentage under the Normal Curve -by TI 83/84
»
»
»
»
Press “2nd”, then press “vars”
Choose “2”, normal cdf
Press “Enter”
Lower: Write the lower limit. If you will calculate the area below a value leave
the value -1E99. If you will calculate the area between two values enter the
lower limit.
Press “Enter”
Upper: Write the upper limit for the area you wish to calculate.
Press “Enter”
µ = enter the mean of Normal distribution. If you work on z values enter zero.
If mean is not zero, enter that value.
Press “Enter”
σ = enter the standard deviation of Normal distribution. If you work on z
values enter 1. If standard deviation is not 1, enter that value.
Press”Enter”
Then you will have the window with the entry “normalcdf(lower, upper, 0, 1)”
Press “Enter”
»
»
»
»
»
»
»
»
»
Normal model
• Type I: Find the Percentage under the Normal Curve -by TI
83/84
Practice: Suppose the data X~N(0,1).
1) What percent of data lie below 0.8?
normalcdf(-1E99, 0.8,0,1)
2) What percent of data lie above -1.2?
1-normalcdf(-1E99, -1.2,0,1)
or
normalcdf(-1E99, 1.2,0,1)
since normal distribution is symmetric
3) What percent of data lie between -1.2 and 0.8?
normalcdf(-1.2, 0.8,0,1)
Normal model
• Type II: Find the Normal Percentiles
Example:
Suppose the data X~N(0,1). Then how small must a
value be so that it is in the lower 10%?
.10
?
0
Normal model
• The standard normal table
Find the value so that the percentage (area) to the left of
this value is 10%
z
.07
.08
.09
−1.3
.0853
.0838
.0823
−1.2
.1020
.1003
.0985
−1.1
.1210
.1190
.1170
Normal model
• Type II: Find the Normal Percentiles
Example:
Suppose the data X~N(0,1). Then how small must a value
be so that it is in the lower 10%?
.10
-1.28
0
Practice:
How large must a value be to place in the top 10%?
Normal model
•
•
»
»
»
»
»
»
»
»
»
»
»
Type II: Find the Normal Percentiles
By TI83/84
Press “2nd”, then press “vars”
Choose “3”, invNorm
Press “Enter”
Area: Write the area.
Press “Enter”
µ = enter the mean of Normal distribution. If you work on z
values enter zero. If mean is not zero, enter that value.
Press “Enter”
σ = enter the standard deviation of Normal distribution. If you
work on z values enter 1. If standard deviation is not 1, enter
the value.
Press “Enter”
Then you will have the window with the entry “invNorm(area,
µ,σ )”
Press “Enter”
Normal model
• Type II: Find the Normal Percentiles
Example:
Suppose the data X~N(0,1). Then how small must a value
be so that it is in the lower 10%?
.10
-1.28
Practice:
0
How large must a value be to place in the top 10%?
invNorm(10,0,1)
Normal model
• From standard Normal N(0,1) to general Normal N(µ,σ)
1) Type I: Find the Percentage under the Normal Curve
i. Standardize Z = X − µ
σ
ii.
Find the percentage from N(0,1)
2) Type II: Find the Normal Percentiles
i. Find the cutoff value z from N(0,1)
ii. Convert
X = µ +σ ⋅Z
Normal model
• From standard Normal N(0,1) to general Normal N(µ,σ)
Example:
Companies that design furniture for elementary school
classrooms produce a variety of sizes for kids of different
ages. Suppose the heights of kindergarten children can be
described by a Normal model with a mean of 38.2 inches
and standard deviation of 1.8 inches.
1) What percent of kindergarten kids should the
company expect to be less than 3 feet tall?
2) At least how tall are the biggest 10% of
kindergarteners?
3) In what height interval should the company expect
to find the middle 80% of kindergarteners?
What Can Go Wrong?
Don’t use a Normal model
when the distribution is not
unimodal and symmetric.
Copyright © 2009 Pearson Education, Inc.
What Can Go Wrong? (cont.)
Don’t use the mean and standard deviation when
outliers are present—the mean and standard
deviation can both be distorted by outliers.
Don’t round your results in the middle of a
calculation.
Don’t worry about minor differences in results.
Copyright © 2009 Pearson Education, Inc.
What have we learned?
The story data can tell may be easier to
understand after shifting or rescaling the data.
Shifting data by adding or subtracting the same
amount from each value affects measures of
center and position but not measures of
spread.
Rescaling data by multiplying or dividing every
value by a constant changes all the summary
statistics—center, position, and spread.
Copyright © 2009 Pearson Education, Inc.
What have we learned? (cont.)
We’ve learned the power of standardizing data.
Standardizing uses the SD as a ruler to
measure distance from the mean (z-scores).
With z-scores, we can compare values from
different distributions or values based on
different units.
z-scores can identify unusual or surprising
values among data.
Copyright © 2009 Pearson Education, Inc.
What have we learned? (cont.)
We’ve learned that the 68-95-99.7 Rule can be a
useful rule of thumb for understanding
distributions:
For data that are unimodal and symmetric,
about 68% fall within 1 SD of the mean, 95%
fall within 2 SDs of the mean, and 99.7% fall
within 3 SDs of the mean.
Copyright © 2009 Pearson Education, Inc.
Suggested exercises from the textbook:
Chapter 6: 1, 3, 5, 7, 9, 15, 19, 21, 24, 27, 29, 33, 40,
42, 43, 45, 47, 51