Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
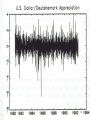
Volatility Chapter 10 1 Motivation: • Until the early 80s econometrics had focused almost solely on modeling the means of series, i.e. their actual values. Recently however we have focused increasingly on the importance of volatility, its determinates and its effects on mean values. Definition of Volatility • Suppose that Si is the value of a variable on day i. The volatility per day is the standard deviation of ln(Si /Si-1) • Normally days when markets are closed are ignored in volatility calculations • The volatility per year is 252 times the daily volatility • Variance rate is the square of volatility 3 Standard Approach to Estimating Volatility • Define sn as the volatility per day between day n-1 and day n, as estimated at end of day n-1 • Define Si as the value of market variable at end of day i • Define ui= ln(Si/Si-1) 及以下公式 m 1 2 n2 ( u u ) m 1 i 1 n i 1 m u un i m i 1 4 Simplifications Usually Made in Risk Management • Define ui as (Si−Si-1)/Si-1 • Assume that the mean value of ui is zero daily - short near 0 • Replace m-1 by m (high frequent) 1 m 2 2 This gives s n = å un-i m i=1 5 Implied Volatilities • Of the variables needed to price an option the one that cannot be observed directly is volatility • We can therefore imply volatilities from market prices and vice versa 6 VIX Index: A Measure of the Implied Volatility of the S&P 500 7 Linear Regression –the Workhorse of Financial Modeling • General form for the linear regression of Yt on X1t , X 2 t ,..., X kt is Yt 1 β 0 β1X1t β 2 X 2 t ... β k X kt ε t 1 ε t ~ N(0, σ ) 2 • Variance of the error term is constant over time. This property is called conditional homoscedasticity Distinction between the Conditional and Unconditional Variance • The unconditional variance is just the standard measure of the variance var(x) =E(x -E(x))2 • The conditional variance is the measure of our uncertainty about a variable given a model and an information set . cond var(x) =E(x-E(x| ))2 this is the true measure of uncertainty Modeling conditional means and variances •If is N(0, 1), and Y = a + b, othen the mean is E(Y) = a oVar(Y ) = b2. •To model the conditional mean of Yt given X t (X1t , X 2 t ,..., X kt ) owrite Yt as the conditional mean plus white noise Yt E t 1[Yt | X t 1 ] σε t 10 Variation in the Conditional Variance •To allow a non-constant conditional variance in the model, multiply the white noise term by the conditional standard deviation. This product is added to the conditional mean as in the previous slide. Yt E t 1[Yt | X t 1 ] σ t ε t • t must be non-negative since it is a standard deviation 11 Stylized Facts of asset returns • Thick tails, they tend to be leptokurtic • Volatility clustering, Mandelbrot, ‘large changes tend to be followed by large changes of either sign’ • Leverage Effects, refers to the tendency for changes in stock prices to be negatively correlated with changes in volatility. • Forcastable events, volatility is high at regular times such as news announcements or other expected events, or even at certain times of day, e.g. less volatile in the early afternoon. Volatility Clustering (read books) 14 Heavy Tails • Daily exchange rate changes are not normally distributed – The distribution has heavier tails than the normal distribution – It is more peaked than the normal distribution • This means that small changes and large changes are more likely than the normal distribution would suggest • Many market variables have this property, known as excess kurtosis 15 Normal and Heavy-Tailed Distribution 16 Are Daily Changes in Exchange Rates Normally Distributed? Real World (%) >1 SD >2SD >3SD >4SD >5SD >6SD 25.04 5.27 1.34 0.29 0.08 0.03 Normal Model (%) 31.73 4.55 0.27 0.01 0.00 0.00 17 ARCH and GARCH 18 References The classics: • Engle, R.F. (1982), Autoregressive Conditional Heteroskedasticity with Estimates of the Variance of U.K. • Bollerslev, T.P. (1986), Generalized Autoregresive Conditional Heteroscedasticity. Introduction/Reviews: • Bollerslev T., Engle R. F. and D. B. Nelson (1994), ARCH Models • Engle, R. F. (2001), GARCH 101: The Use of ARCH/GARCH Models in Applied Econometrics. Weighting Scheme Instead of assigning equal weights to the observations when calculating volatility we can use different weights i for each observation 2 u i 1 i n i m 2 n where m i 1 i 1 20 ARCH(q) Model Engle(1982) Auto-Regressive Conditional Heteroscedasticity Yt βX t σ t ε t where ε t ~ N(0,1) σ γVL i 1 α i (σ t i ε t i ) q 2 t 2 where q γ αi 1 i 1 In an ARCH(q) model we also assign some weight to the long-run variance rate, VL: 21 Note: as we are dealing with a variance VL and both 0 and i 0 all i Even though the errors may be serially uncorrelated they are not independent, there will be volatility clustering and fat tails. 22 EWMA Model • In an exponentially weighted moving average model, the weights assigned to the u2 decline exponentially as we move back through time • This leads to (yesterday+ σ λσ 2 t 2 t 1 (1 λ)(Yt E t 1[Yt | X t 1 ]) 23 2 Attractions of EWMA • Relatively little data needs to be stored • We need only remember the current estimate of the variance rate and the most recent observation on the innovation to the market variable • Tracks volatility changes • RiskMetrics uses = 0.94 for daily volatility forecasting 24 GARCH(p,q) Bollerslev (1986) In empirical work with ARCH models high q is often required, a more parsimonious representation is the Generalised ARCH model VL= average of LT variance p σ t ω α i σ ε 2 i 1 2 2 t i t 1 q β jσ 2 tj j1 ω γVL 25 GARCH (1,1) In GARCH (1,1) we assign some weight to the long-run average variance rate σ 2t ω ασ 2t 1ε 2t 1 βσ 2t 1 ω γVL ω VL 1 α β Since weights must sum to 1 + + =1 26 Example • Suppose σ 0.000002 0.13 σ ε 0.86 σ 2 t 2 2 t 1 t 1 2 t 1 • The long-run variance rate is 0.0002 so that the long-run volatility per day is 1.4% 27 Example continued • Suppose that the current estimate of the volatility is 1.6% per day and the most recent percentage change in the market variable is 1%. • The new variance rate is 0000002 . 013 . 00001 . 086 . 0000256 . 000023336 . The new volatility is 1.53% per day 28 Independence vs. Zero Correlation • Independence implies zero correlation but not vice versa • GARCH processes are good examples • Dependence of the conditional variance on the past is the reason the process is not independent • Independence of the conditional mean on the past is the reason that the process is uncorrelated Other Models • Many other GARCH models have been proposed • For example, we can design a GARCH models so that the weight given to i2 depends on whether i is positive or negative 30 Variance Targeting • One way of implementing GARCH(1,1) that increases stability is by using variance targeting • We set the long-run average volatility equal to the sample variance • Only two other parameters then have to be estimated 31 Maximum Likelihood Methods • All parameters in GARCH models are simply estimated by maximum likelihood using the same basic likelihood function, assuming normality T log( L) ( log( t ) t / t ) 2 2 2 i 1 • In maximum likelihood methods we choose parameters that maximize the likelihood of the observations occurring 32 Example 1 • We observe that a certain event happens one time in ten trials. What is our estimate of the proportion of the time, p, that it happens? • The probability of the outcome is p(1 p) 9 • We maximize this to obtain a maximum likelihood estimate: p=0.1 33 Example 2 Estimate the variance of observations from a normal distribution with mean zero Observations are: u1 , u2 ,........, um The variance is denoted by The likelihood that ui is observed is given by the probability density function of the normal distribution: ui2 1 exp 2v 2v 34 The likelihood of n observations occurring in the order in which they are observed is: 1 ui2 Maximize : exp i 1 2v 2v n ui2 or : ln( v) v i 1 1 n 2 This gives : v ui n i 1 n 35 Application to GARCH (1,1) We choose parameters that maximize u ln(vi ) vi i 1 n 2 i 36 Forecasting and Persistence with GARCH(1,1) model σ 2t 1 ω ασ 2tε 2t βσ 2t (1 α β) VL ασ 2tε 2t βσ 2t σ 2t 1 VL α(σ 2tε 2t VL ) β(σ 2t VL ) Taking expectation at time t E t (σ 2t 1 VL ) (α β) E t [σ 2t VL ] By repeated substitutions: E t (σ2t j ) VL (α β) j (σ2t VL ) As j→∞, the forecast reverts to the unconditional variance: ω/(1-α-β). When α+β=1, as in EWMA model, the expected future variance rate equals to today’s variance rate.