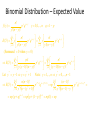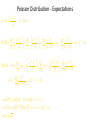Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
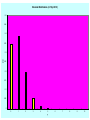
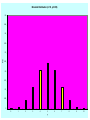
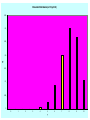
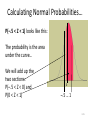
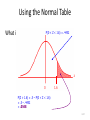
Unit-II-Distribution Funtions Bernoulli Distribution • An experiment consists of one trial. It can result in one of 2 outcomes: Success or Failure (or a characteristic being Present or Absent). • Probability of Success is p (0<p<1) • Y = 1 if Success (Characteristic Present), 0 if not p p( y) 1 p y 1 y0 1 E (Y ) yp( y ) 0(1 p ) 1 p p y 0 E Y 2 0 2 (1 p ) 12 p p V (Y ) E Y 2 E (Y ) p p 2 p (1 p ) p (1 p ) 2 Binomial Experiment • Experiment consists of a series of n identical trials • Each trial can end in one of 2 outcomes: Success or Failure • Trials are independent (outcome of one has no bearing on outcomes of others) • Probability of Success, p, is constant for all trials • Random Variable X, is the number of Successes in the n trials is said to follow Binomial Distribution with parameters n and p • Y can take on the values x=0,1,…,n • Notation: X~Bin(n,p) Binomial Distribution Consider outcomes of an experiment with 3 Trials: SSS y 3 P( SSS ) P(Y 3) p (3) p 3 SSF , SFS , FSS y 2 P ( SSF SFS FSS ) P (Y 2) p (2) 3 p 2 (1 p ) SFF , FSF , FFS y 1 P( SFF FSF FFS ) P (Y 1) p (1) 3 p (1 p ) 2 FFF y 0 P ( FFF ) P (Y 0) p (0) (1 p)3 In General: n n! 1) # of ways of arranging y S s (and (n y ) F s ) in a sequence of n positions y y !(n y )! 2) Probability of each arrangement of y S s (and (n y ) F s ) p y (1 p ) n y n 3) P(Y y ) p ( y ) p y (1 p) n y y 0,1,..., n y EXCEL Functions: p ( y ) is obtained by function: BINOM.DIST(y, n, p, 0) F ( y ) is obtained by function: BINOM.DIST(y, n, p,1) n Binomial Expansion: (a b) a i b n i i 0 i n n n n p ( y ) p y (1 p ) n y p (1 p ) 1 "Legitimate" Probability Distribution y 0 y 0 y n n Binomial Distribution (n=10,p=0.10) 0.5 0.45 0.4 0.35 p(y) 0.3 0.25 0.2 0.15 0.1 0.05 0 0 1 2 3 4 5 y 6 7 8 9 10 Binomial Distribution (n=10, p=0.50) 0.5 0.45 0.4 0.35 p(y) 0.3 0.25 0.2 0.15 0.1 0.05 0 0 1 2 3 4 5 y 6 7 8 9 10 Binomial Distribution(n=10,p=0.8) 0.35 0.3 0.25 p(y) 0.2 0.15 0.1 0.05 0 0 1 2 3 4 5 y 6 7 8 9 10 Binomial Distribution – Expected Value f ( y) n! p y q n y y!(n y )! y 0,1,..., n q 1 p n n! n! y n y E (Y ) y p q y p y q n y y 0 y!( n y )! y 1 y!(n y )! (Summand 0 when y 0) n n yn! n! y n y y n y E (Y ) p q p q y 1 y ( y 1)! ( n y )! y 1 ( y 1)!(n y )! Let y * y 1 y y * 1 Note : y 1,..., n y * 0,..., n 1 n n 1 n(n 1)! (n 1)! y*1 n ( y*1) y* ( n 1) y* E (Y ) * p q np p q * * * y * 0 y ! n ( y 1) ! y * 0 y ! ( n 1) y ! n 1 np ( p q ) n 1 np p (1 p ) n 1 np (1) np Geometric Distribution • Used to model the number of Bernoulli trials needed until the first Success occurs (P(S)=p) – First Success on Trial 1 S, y = 1 p(1)=p – First Success on Trial 2 FS, y = 2 p(2)=(1-p)p – First Success on Trial k F…FS, y = k p(k)=(1-p)k-1 p p ( y ) (1 p ) y 1 p y 1 y 1 p( y) (1 p) y 1,2,... y 1 p p (1 p ) y 1 y 1 Setting y * y 1 and noting that y 1,2,... y * 0,1,... p 1 p ( y ) p (1 p ) p 1 y 1 y * 0 1 (1 p ) p y* Poisson Distribution • Distribution often used to model the number of incidences of some characteristic in time or space: – Arrivals of customers in a queue – Numbers of flaws in a roll of fabric – Number of typos per page of text. • Distribution obtained as follows: – – – – – – Break down the “area” into many small “pieces” (n pieces) Each “piece” can have only 0 or 1 occurrences (p=P(1)) Let l=np ≡ Average number of occurrences over “area” Y ≡ # occurrences in “area” is sum of 0s & 1s over “pieces” Y ~ Bin(n,p) with p = l/n Take limit of Binomial Distribution as n with p = l/n Poisson Distribution - Derivation n! n! l l p( y) p y (1 p ) n y 1 y!(n y )! y!(n y )! n n Taking limit as n : y n! l l lim p ( y ) lim 1 n n y!( n y )! n n y ly n y n y ly n(n 1)...( n y 1)( n y )! l n l lim 1 y! n n y (n y )! n n n n(n 1)...( n y 1) l ly n n 1 n y 1 l lim 1 lim ... 1 y y! n (n l ) y! n n l n l n l n n n n n y 1 Note : lim ... lim 1 for all fixed y n n l n nl ly l lim p ( y ) lim 1 n y! n n n n a From Calculus, we get : lim 1 e a n n ly e l l y lim p ( y ) e l y 0,1,2,... n y! y! Series expansion of exponentia l function : e x x 0 e l l e l e l e l 1 " Legitimate " Probabilit y Distributi on y! y 0 y 0 y! p( y) y 0 l xi i! y EXCEL Functions : p ( y ) : POISSON( y, l ,0) F ( y ) : POISSON( y, l ,1) y n y Poisson Distribution - Expectations el ly f ( y) y! y 0,1,2,... e l l y e l l y e l l y l y 1 l l l E (Y ) y y l e l e e l y! y 1 y! y 1 ( y 1)! y 0 y 1 ( y 1)! e l l y e l l y e l l y E Y (Y 1) y ( y 1) y ( y 1) y 0 y! y 2 y! y 2 ( y 2)! ly 2 l2 e l y 2 ( y 2)! l2 e l e l l2 E Y 2 E Y (Y 1) E (Y ) l2 l V (Y ) E Y 2 E (Y ) l2 l [l ]2 l l 2 Probability Density Functions… Unlike a discrete random variable which we studied in Chapter 7, a continuous random variable is one that can assume an uncountable number of values. We cannot list the possible values because there is an infinite number of them. Because there is an infinite number of values, the probability of each individual value is virtually 0. 8.12 Point Probabilities are Zero Because there is an infinite number of values, the probability of each individual value is virtually 0. Thus, we can determine the probability of a range of values only. E.g. with a discrete random variable like tossing a die, it is meaningful to talk about P(X=5), say. In a continuous setting (e.g. with time as a random variable), the probability the random variable of interest, say task length, takes exactly 5 minutes is infinitesimally small, hence P(X=5) = 0. It is meaningful to talk about P(X ≤ 5). 8.13 Probability Density Function… A function f(x) is called a probability density function (over the range a ≤ x ≤ b if it meets the following requirements: 1) f(x) ≥ 0 for all x between a and b, and f(x) area=1 a b x 2) The total area under the curve between a and b is 1.0 8.14 8.15 Uniform Distribution… Consider the uniform probability distribution (sometimes called the rectangular probability distribution). f(x) It is described by the function: a b area = width x height = (b – a) x x =1 8.16 Example: The amount of gasoline sold daily at a service station is uniformly distributed with a minimum of 2,000 gallons and a maximum of 5,000 gallons. f(x) 2,000 5,000 x What is the probability that the service station will sell at least 4,000 gallons? Algebraically: what is P(X ≥ 4,000) ? P(X ≥ 4,000) = (5,000 – 4,000) x (1/3000) = .3333 8.17 The Normal Distribution… The normal distribution is the most important of all probability distributions. The probability density function of a normal random variable is given by: It looks like this: Bell shaped, Symmetrical around the mean … 8.18 The Normal Distribution… Important things to note: The normal distribution is fully defined by two parameters: its standard deviation and mean The normal distribution is bell shaped and symmetrical about the mean Unlike the range of the uniform distribution (a ≤ x ≤ b) Normal distributions range from minus infinity to plus infinity 8.19 Standard Normal Distribution… A normal distribution whose mean is zero and standard deviation is one is called the standard normal distribution. 0 1 1 As we shall see shortly, any normal distribution can be converted to a standard normal distribution with simple algebra. This makes calculations much easier. 8.20 Normal Distribution… The normal distribution is described by two parameters: its mean and its standard deviation . Increasing the mean shifts the curve to the right… 8.21 Normal Distribution… The normal distribution is described by two parameters: its mean and its standard deviation . Increasing the standard deviation “flattens” the curve… 8.22 Calculating Normal Probabilities… Example: The time required to build a computer is normally distributed with a mean of 50 minutes and a standard deviation of 10 minutes: 0 What is the probability that a computer is assembled in a time between 45 and 60 minutes? Algebraically speaking, what is P(45 < X < 60) ? 8.23 Calculating Normal Probabilities… P(45 < X < 60) ? …mean of 50 minutes and a standard deviation of 10 minutes… 0 8.24 Calculating Normal Probabilities… P(–.5 < Z < 1) looks like this: The probability is the area under the curve… We will add up the two sections: P(–.5 < Z < 0) and P(0 < Z < 1) 0 –.5 … 1 8.25 Calculating Normal Probabilities… This table gives probabilities P(0 < Z < z) First column = integer + first decimal Top row = second decimal place P(0 < Z < 0.5) How to use Table 3… [other forms of normal tables exist] P(0 < Z < 1) P(–.5 < Z < 1) = .1915 + .3414 = .5328 The probability time is between 45 and 60 minutes = .5328 8.26 Using the Normal Table What is P(Z > 1.6) ? P(0 < Z < 1.6) = .4452 z 0 1.6 P(Z > 1.6) = .5 – P(0 < Z < 1.6) = .5 – .4452 = .0548 8.27 Using the Normal Table P(0 < Z < 2.23) What is P(Z < -2.23) ? P(Z < -2.23) P(Z > 2.23) z -2.23 0 2.23 P(Z < -2.23) = P(Z > 2.23) = .5 – P(0 < Z < 2.23) = .0129 8.28 Using the Normal Table What is P(Z < 1.52) ? P(Z < 0) = .5 P(0 < Z < 1.52) z 0 1.52 P(Z < 1.52) = .5 + P(0 < Z < 1.52) = .5 + .4357 = .9357 8.29 Using the Normal Table What is P(0.9 < Z < 1.9) ? P(0 < Z < 0.9) P(0.9 < Z < 1.9) z 0 0.9 1.9 P(0.9 < Z < 1.9) = P(0 < Z < 1.9) – P(0 < Z < 0.9) =.4713 – .3159 = .1554 8.30 Example The return on investment is normally distributed with a mean of 10% and a standard deviation of 5%. What is the probability of losing money? We want to determine P(X < 0). Thus, X 0 10 P(X 0) P 5 P( Z 2) .5 P(0 Z 2) .5 .4772 .0228 8.31 Finding Values of ZA… Often we’re asked to find some value of Z for a given probability, i.e. given an area (A) under the curve, what is the corresponding value of z (zA) on the horizontal axis that gives us this area? That is: P(Z > zA) = A 8.32 Finding Values of Z… What value of z corresponds to an area under the curve of 2.5%? That is, what is z.025 ? Area = .50 Area = .025 Area = .50–.025 = .4750 If you do a “reverse look-up” on Table 3 for .4750, you will get the corresponding zA = 1.96 Since P(z > 1.96) = .025, we say: z.025 = 1.96 8.33 Finding Values of Z… Other Z values are Z.05 = 1.645 Z.01 = 2.33 Will show you shortly how to use the “t-tables” with infinite degrees of freedom to find a bunch of these standard values for Zα 8.34 Using the values of Z Because z.025 = 1.96 and - z.025= -1.96, it follows that we can state P(-1.96 < Z < 1.96) = .95 The old Empirical Rule stated about 95% within + 2σ P(-2 < Z < 2) = .95 From now on we will use the 1.96 number for this statement unless you are just talking in general terms about how much of a population in with + 2σ Similarly P(-1.645 < Z < 1.645) = .90 8.35 Problems: Standard Normal “Z” If the random variable Z has a standard normal distribution, calculate the following probabilities. P(Z > 1.7) = P(Z < 1.7) = P(Z > -1.7) = P(Z < -1.7) = P(-1.7 < Z < 1.7) 8.36 Problems: Normal Distribution If the random variable X has a normal distribution with mean 40 and std. dev. 5, calculate the following probabilities. P(X > 43) = P(X < 38) = P(X = 40) = P(X > 23) = 8.37 Problem: Normal The time (Y) it takes your professor to drive home each night is normally distributed with mean 15 minutes and standard deviation 2 minutes. Find the following probabilities. Draw a picture of the normal distribution and show (shade) the area that represents the probability you are calculating. P(Y > 25) = P( 11 < Y < 19) = P (Y < 18) = 8.38 Problem: Target the Mean The manufacturing process used to make “heart pills” is known to have a standard deviation of 0.1 mg. of active ingredient. Doctors tell us that a patient who takes a pill with over 6 mg. of active ingredient may experience kidney problems. Since you want to protect against this (and most likely lawyers), you are asked to determine the “target” for the mean amount of active ingredient in each pill such that the probability of a pill containing over 6 mg. is 0.0035 (0.35%). You may assume that the amount of active ingredient in a pill is normally distributed. *Solve for the target value for the mean. 8.39