Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
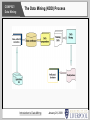
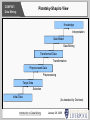
COMP527: Data Mining COMP527: Data Mining M. Sulaiman Khan ([email protected]) Dept. of Computer Science University of Liverpool 2009 Introduction to Data Mining January 28, 2009 Slide 1 COMP527: Data Mining COMP527: Data Mining Introduction to the Course Introduction to Data Mining Introduction to Text Mining General Data Mining Issues Data Warehousing Classification: Challenges, Basics Classification: Rules Classification: Trees Classification: Trees 2 Classification: Bayes Classification: Neural Networks Classification: SVM Classification: Evaluation Classification: Evaluation 2 Regression, Prediction Introduction to Data Mining Input Preprocessing Attribute Selection Association Rule Mining ARM: A Priori and Data Structures ARM: Improvements ARM: Advanced Techniques Clustering: Challenges, Basics Clustering: Improvements Clustering: Advanced Algorithms Hybrid Approaches Graph Mining, Web Mining Text Mining: Challenges, Basics Text Mining: Text-as-Data Text Mining: Text-as-Language Revision for Exam January 28, 2009 Slide 2 COMP527: Data Mining Today's Topics What is Data Mining? Definitions KDD: Knowledge Discovery in Databases KDD Process Differences with Statistics Views on the Process Basic Functions Why would you do this? Motivations Applications Summary Introduction to Data Mining January 28, 2009 Slide 3 COMP527: Data Mining What is Data Mining? Some Definitions: “The nontrivial extraction of implicit, previously unknown, and potentially useful information from data” (Piatetsky-Shapiro) "...the automated or convenient extraction of patterns representing knowledge implicitly stored or captured in large databases, data warehouses, the Web, ... or data streams." (Han, pg xxi) “...the process of discovering patterns in data. The process must be automatic or (more usually) semiautomatic. The patterns discovered must be meaningful...” (Witten, pg 5) “...finding hidden information in a database.” (Dunham, pg 3) “...the process of employing one or more computer learning techniques to automatically analyse and extract knowledge from data contained within a database.” (Roiger, pg 4) Introduction to Data Mining January 28, 2009 Slide 4 COMP527: Data Mining What is Data Mining? Keywords from each definition: “The nontrivial extraction of implicit, previously unknown, and potentially useful information from data” (Piatetsky-Shapiro) "...the automated or convenient extraction of patterns representing knowledge implicitly stored or captured in large databases, data warehouses, the Web, ... or data streams." (Han, pg xxi) “...the process of discovering patterns in data. The process must be automatic or (more usually) semiautomatic. The patterns discovered must be meaningful...” (Witten, pg 5) “...finding hidden information in a database.” (Dunham, pg 3) “...the process of employing one or more computer learning techniques to automatically analyze and extract knowledge from data contained within a database.” (Roiger, pg 4) Introduction to Data Mining January 28, 2009 Slide 5 COMP527: Data Mining KDD: Knowledge Discovery in Databases Many texts treat KDD and Data Mining as the same process, but it is also possible to think of Data Mining as the discovery part of KDD. Dunham: KDD is the process of finding useful information and patterns in data. Data Mining is the use of algorithms to extract information and patterns derived by the KDD process. For this course, we will discuss the entire process (KDD) but focus mostly on the algorithms used for discovery. Introduction to Data Mining January 28, 2009 Slide 6 COMP527: Data Mining KDD: Knowledge Discovery in Databases KDD (Knowledge Discovery in Databases) is the nontrivial process of identifying valid, novel, potentially useful and ultimately understandable patterns in data. (Fayyad, Shapiro, & Smyth, CACM 96) Or KDD : non-trivial extraction of implicit, previously unknown and potentially useful information Data mining is just a part of the KDD process Data mining applies algorithms to large data to produce models or patterns interesting to the user. Introduction to Data Mining January 28, 2009 Slide 7 COMP527: Data Mining The Data Mining (KDD) Process Introduction to Data Mining January 28, 2009 Slide 8 COMP527: Data Mining KDD Process Components Operational Data - Day-to-day data used to run business Clean, collect and summarise - Most Data is not suitable for data mining - Errors or Noise, missing data, invalid formats Data warehouse - Mega store of clean (analysis) data Data Preparation - Validating the data for mining (e.g. remove noise, formatting, running validation routines etc.) Training Data – Data used as test case for mining Data Mining – the process of applying mining algorithms on data to produce interesting patterns Introduction to Data Mining January 28, 2009 Slide 9 COMP527: Data Mining • • • • Differences with Statistics Data Mining Algorithms scale to large data Data is used secondary for Data mining DM–tools use background knowledge for End-User Strategy : – Exploration – Cyclic Introduction to Data Mining • • • • Statistics Many algorithms with quadratic run time. Data is used for the Statistic (primary) Statistical background is often required Strategy: – Conformational – Verifying – Few loops January 28, 2009 Slide 10 COMP527: Data Mining Piatetsky-Shapiro View Knowledge Interpretation Data Model Data Mining Transformed Data Transformation Preprocessed Data Preprocessing Target Data Selection Initial Data Introduction to Data Mining (As tweaked by Dunham) January 28, 2009 Slide 11 COMP527: Data Mining CRISP-DM View Introduction to Data Mining January 28, 2009 Slide 12 COMP527: Data Mining Data Mining Functions All Data Mining functions can be thought of as attempting to find a model to fit the data. Each function needs Criteria to create one model over another. Each function needs a technique to Compare the data. Two types of model: Predictive models predict unknown values based on known data Descriptive models identify patterns in data Each type has several sub-categories, each of which has many algorithms. We won't have time to look at ALL of them in detail. Introduction to Data Mining January 28, 2009 Slide 13 COMP527: Data Mining Data Mining Functions Predictive Classification: Maps data into predefined classes Regression: Maps data into a function Prediction: Predict future data states Time Series Analysis: Analyze data over time (Supervised Learning) Data Mining Descriptive Clustering: Find groups of similar items Association Rules: Find relationships between items Characterisation: Derive representative information Sequence Discovery: Find sequential patterns (Unsupervised Learning) Introduction to Data Mining January 28, 2009 Slide 14 COMP527: Data Mining Classification The aim of classification is to create a model that can predict the 'type' or some category for a data instance that doesn't have one. Two phases: 1. Given labelled data instances, learn model for how to predict the class label for them. (Training) 2. Given an unlabelled, unseen instance, use the model to predict the class label. (Prediction) Some algorithms predict only a binary split (yes/no), some can predict 1 of N classes, some give probabilities for each of N classes. Introduction to Data Mining January 28, 2009 Slide 15 COMP527: Data Mining Clustering The aim of clustering is similar to classification, but without predefined classes. Clustering attempts to find clusters of data instances which are more similar to each other than to instances outside of the cluster. Unsupervised Learning: learning by observation, rather than by example. Some algorithms must be told how many clusters to find, others try to find an 'appropriate' number of clusters. Introduction to Data Mining January 28, 2009 Slide 16 COMP527: Data Mining Association Rule Mining The aim of association rule mining is to find patterns that occur in the data set frequently enough to be interesting. Hence the association or correlation of data attributes within instances, rather than between instances. These correlations are then expressed as rules – if X and Y appear in an instance, then Z also appears. Most algorithms are extensions of a single base algorithm known as 'A Priori', however a few others also exist. Introduction to Data Mining January 28, 2009 Slide 17 COMP527: Data Mining Why? That all sounds ... complicated. Why should I learn about Data Mining? What's wrong with just a relational database? Why would I want to go through these extra [complicated] steps? Isn't it expensive? It sounds like it takes a lot of skill, programming, computational time and storage space. Where's the benefit? Data Mining isn't just a cute academic exercise, it has very profitable real world uses. Practically all large companies and many governments perform data mining as part of their planning and analysis. Introduction to Data Mining January 28, 2009 Slide 18 COMP527: Data Mining Why Data Mining? Some general reasons We are Data rich but knowledge poor Computing affordable - Storage, CPU, networking Data is too large to analyse (Very Large Databases (VLBD) - Dimensionality (size) - distributed (location spread) - heterogeneous (different types of data) Traditional techniques infeasible - Statistics, databases Competitive pressure in business enterprises - Customer profiling (Need to know who is a good customer) - Business to Business (B2B – Being “old” is not profitable) Introduction to Data Mining January 28, 2009 Slide 19 COMP527: Data Mining Data is Everywhere! Relational database—A commodity of every enterprise Huge data warehouses are under construction POS (Point of Sales): Transactional DBs in terabytes Object, relational, distributed, heterogeneous and legacy databases Spatial databases (GIS), remote sensing database (EOS), and scientific/engineering databases (Genetic data etc) Time-series data (e.g., stock trading) and temporal data Text (documents, emails) and multimedia databases WWW:A huge, hyper-linked, dynamic, global information system (XML, Web content and Web usage data) Crime data – terrorist data more recent applications Introduction to Data Mining January 28, 2009 Slide 20 COMP527: Data Mining The Data Explosion The rate of data creation is accelerating each year. In 2003, UC Berkeley estimated that the previous year generated 5 exabytes of data, of which 92% was stored on electronically accessible media. Mega < Giga < Tera < Peta < Exa ... All the data in all the books in the US Library of Congress is ~136 Terabytes. So 37,000 New Libraries of Congress in 2002. VLBI Telescopes produce 16 Gigabytes of data every second. Each engine of each plane of each company produces ~1 Gigabyte of data every trans-atlantic length journey. Google searches 18 billion+ accessible web pages. Introduction to Data Mining January 28, 2009 Slide 21 COMP527: Data Mining Data Explosion Implications As the amount of data increases, the proportion of information decreases. As more and more data is generated automatically, we need to find automatic solutions to turn those stored raw results into information. Companies need to turn stored data into profit ... otherwise why are they storing it? Let's look at some real world examples. Introduction to Data Mining January 28, 2009 Slide 22 COMP527: Data Mining Classification The data generated by airplane engines can be used to determine when it needs to be serviced. By discovering the patterns that are indicative of problems, companies can service working engines less often (increasing profit) and discover faults before they materialise (increasing safety). Loan companies can “give you results in minutes” by classifying you into a good credit risk or a bad risk, based on your personal information and a large supply of previous, similar customers. Cell phone companies can classify customers into those likely to leave, and hence need enticement, and those that are likely to stay regardless. Introduction to Data Mining January 28, 2009 Slide 23 COMP527: Data Mining Clustering Discover previously unknown groups of customers/items. By finding clusters of customers, companies can then determine how best to handle that particular cluster. For example, this could be used for targeted advertising, special offers, transferring information gathered by association rule mining to other members of the cluster, and so forth. The concept of 'Similarity' is often used for determining other items that you might be interested in, eg 'More Like This' links. Introduction to Data Mining January 28, 2009 Slide 24 COMP527: Data Mining Association Rule Mining By finding association rules from shopping baskets, supermarkets can use this information for many things, including: Product placement in the store What to put on sale What to create as 'joint special offers' What to offer the customer in terms of coupons What to advertise together It shouldn't be surprising that your Tesco coupons are for things that you sometimes buy, rather than things you always or never buy. Wal-Mart in the US records every transaction at every store -petabytes of information to sift through. (TeraData) Introduction to Data Mining January 28, 2009 Slide 25 COMP527: Data Mining Data/Information/Knowledge/Wisdom Note well that data mining applications have no wisdom. They cannot apply the knowledge that they discover appropriately. For example, a data mining application may tell you that there is a correlation between buying music magazines and beer, but it doesn't tell you how to use that knowledge. Should you put the two close together to reinforce the tendency, or should you put them far apart as people will buy them anyway and thus stay in the store longer? Data mining can help managers plan strategies for a company, it does not give them the strategies. Introduction to Data Mining January 28, 2009 Slide 26 COMP527: Data Mining Summary What is data mining? KDD - knowledge discovery in databases: nontrivial extraction of implicit, previously unknown and potentially useful information Why do we need data mining? - Very large data - data explosion, - Dimensionality of data - Heterogeneity of data - Technology rich - Traditional techniques infeasible Introduction to Data Mining January 28, 2009 Slide 27