Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
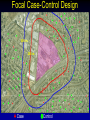
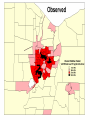
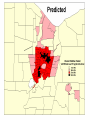
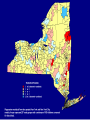
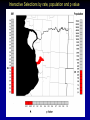
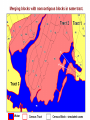
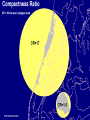
Statistical approaches for detecting unexplained clusters of disease. Spatial Aggregation Thomas Talbot New York State Department of Health Environmental Health Surveillance Section Albany School of Public Health GIS & Public Health Class March 3, 2009 Cluster • A number of similar things grouped closely together Webster’s Dictionary • Unexplained concentrations of health events in space and/or time Public Health Definition • Occupation • Sex, Age • Socioeconomic class • Behavior (smoking) • Race • Time • Space Spatial Autocorrelation “Everything is related to everything else, but near things are more related than distant things.” - Tobler’s first law of geography Positive autocorrelation Negative autocorrelation Moran’s I • A test for spatial autocorrelation in disease rates. • Nearby areas tend to have similar rates of disease. Moran I is greater than 1, positive spatial autocorrelation. • When nearby areas are dissimilar Moran I is less than 1, negative spatial autocorrelation. Detecting Clusters • Consider scale • Consider zone • Control for multiple testing Talbot Cluster Questions • Does a disease cluster in space? • Does a disease cluster in both time and space? • Where is the most likely cluster? • Where is the most likely cluster in both time and space? More Cluster Questions • At what geographic or population scale do clusters appear? • Are cases of disease clustered in areas of high exposure? Nearest Neighbor Analysis Cuzick & Edwards Method • Count the the number of cases whose nearest neighbors are cases and not controls. • When cases are clustered the nearest neighbor to a case will tend to be another case, and the test statistic will be large. Nearest Neighbor Analyses Advantages • Accounts for the geographic variation in population density • Accounts for confounders through judicious selection of controls • Can detect clustering with many small clusters Disadvantages • Must have spatial locations of cases & controls • Doesn’t show location of the clusters Spatial Scan Statistic Martin Kulldorff •Determines the location with elevated rate that is statistically significant. •Adjust for multiple testing of the many possible locations and area sizes of clusters. •Uses Monte Carlo testing techniques The Space-Time Scan Statistic • Cylindrical window with a circular geographic base and a height corresponding to time. • Cylindrical window is moved in space and time. • P value for each cylinder calculated. Knox Method test for space-time interaction • When space-time interaction is present cases near in space will be near in time, the test statistic will be large. • Test statistic: The number of pairs of cases that are near in both time and space. Focal tests for clustering • Cross sectional or cohort approach: Is there a higher rate of disease in populations living in contaminated areas compared to populations in uncontaminated areas? (Relative risk) • Case/control approach: Are there more cases than controls living in a contaminated area? (Odds ratio) Focal Case-Control Design 500 m. 250 m. Case Control Regression Analysis • Control for know risk factors before analyzing for spatial clustering • Analyze for unexplained clusters. • Follow-up in areas with large regression residuals with traditional case-control or cohort studies • Obtain additional risk factor data to account for the large residuals. At what geographic or population scale do clusters appear? Multiresolution mapping. A cluster of cases in a neighborhood provides a different epidemiological meaning then a cluster of cases across several adjacent counties. Results can change dramatically with the scale of analysis. 1995-1999 Interactive Selections by rate, population and p value References • Talbot TO, Kulldorff M, Forand SP, and Haley VB. Evaluation of Spatial Filters to Create Smoothed Maps of Health Data. Statistics in Medicine. 2000, 19:2451-2467 • Forand SP, Talbot TO, Druschel C, Cross PK. Data Quality and the Spatial Analysis of Disease Rates: Congenital Malformations in New York. 2002. Health and Place. 2002, 8:191-199 • Haley VB, Talbot TO. Geographic Analysis of Blood Lead Levels in New York State Children Born 1994-1997. Environmental Health Perspectives 2004, 112(15):1577-1582 • Kuldorff M, National Cancer Institute. SatScan User Guide www.satscan.org Geographic Aggregation of Health Data by Thomas Talbot NYS Department of Health Environmental Health Surveillance Section Health data can be shown at different geographic scales • • • • • Residential address Census blocks, and tracts Towns Counties State Concerns about release of small area data • Risk of disclosure of confidential information. • Rates of disease are unreliable due to small numbers. Rate maps with small numbers provide very little information. http://www.nyhealth.gov/statistics/ny_asthma/hosp/zipcode/hamil_t2.htm http://www.nyhealth.gov/statistics/ny_asthma/hosp/zipcode/pdf/hamil_m2.pdf Disclosure of confidential information Census Blocks Smoothed or Aggregated Count & Rate Maps • Protect Confidentiality so data can be shared. • Reduce random fluctuations in rates due to small numbers. Smoothed Rate Maps • Borrow data from neighboring areas to provide more stable rates of disease. – Shareware tools available – Empirical or Hierarchal Bayesian approaches – Adaptive Spatial Filters – Head banging – etc. from Talbot et al., Statistics in Medicine, 2000 Problems with smoothing • Does not provide counts & rates for defined geographic areas. • Not clear how to link risk factor data with smoothed health data. • Methods are sometimes difficult to understand - “black boxes” • Does not meet requirements of some recent New York policies & legislation. Environmental Facilities & Cancer Incidence Map Law, 2008 § 3-0317 • Plot cancer cases by census block, except in cases where such plotting could make it possible to identify any cancer patient. • Census blocks shall be aggregated to protect confidentiality. Environmental Justice & Permitting NYSDEC Commissioner Policy 29 • Incorporate existing human health data into the environmental review process. • Data will be made available at a fine geographic scale (ZIP code or ZIP Code Groups). Aggregated Count or Rate Maps • Merge small areas with neighboring areas to provide more stable rates of disease and/or protect confidentiality. – Aggregation can be done manually. – Existing automated tools were difficult to use. Original ZIP Codes 3 Years Low Birth Weight Incidence Ratios Aggregated to 250 Births per ZIP Code Group Our Tool Requirements Goal • Aggregate small areas into larger ones. • User decides how much aggregation is needed. • Works with various levels of geography. – census blocks, tracts, towns, ZIP codes etc. – can nest one level of geography in another • Uses software which is readily available in NYSDOH (SAS) • Can output results for use in mapping programs. Aggregation Tool Regions Original Block Data † Block Block Cases Region 122300/2004 10 A 122300/2005 11 A 014500/3005 3 B Cases 122300/2004 10 122300/2005 11 014500/3005 3 014500/3007 4 014500/3007 4 B 014500/3008 0 014500/3008 0 B 014500/3009 1 014500/3009 1 B 014500/3010 15 014500/3010 15 B 103202/2001 8 103202/2001 8 C 103202/2002 6 103202/2002 6 C † Simulated data SAS Tool Cases Region 21 A 23 B 14 C Aggregation Process • Populated blocks with the fewest cases are merged first. • If there is a tie the program starts with the block with the fewest neighbors. • Selected block then is merged with the closest neighbor in the same census block group. • After merging the first block the list of neighbors is updated. • Process repeats until all regions have a minimum number of cases – program can also merge to user specified population Special Situations • Tool tries to avoid merging blocks in different census areas: – Census block groups – Census tracts (homogeneous population characteristics). – Counties • Tool tries to avoid merging blocks across major water bodies e.g. Finger lakes, Hudson River, Atlantic Ocean Water † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population † Simulated data 9 Cases 98 Population New York State Descriptive Statistics Year 2000 populated census blocks New Regions: Level of Aggregation Statistic (calculated using populated regions only) Original Census Blocks 6 cases 12 cases 24 cases 225,167 39,748 21,525 11,381 84 477 882 1,667 Median cases 1 10 20 38 Median Census blocks 1 4 7 14 Number Average Population NY number of cases NY population 470,000 18,976,457 Performance Measures • Compactness • Homogeneity with respect to demographic factors (measured as index of dissimilarity) • Similar population sizes. • Number of aggregated areas. • Aggregated zones are completely contained within larger areas. – e.g. blocks aggregation areas contained within tracts Index of dissimilarity the percentage of one group that would have to move to a different area in order to have a even distribution Wikipedia bi = the minority population of the ith area, e.g. census tract B = the total minority population of the large geographic entity for which the index of dissimilarity is being calculated. wi = the non-minority population of the ith area W = the total non-minority population of the large geographic entity for which the index of dissimilarity is being calculated. The End