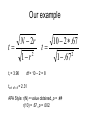Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Correlation Correlational Research Correlational research: describes the relationship between two or more naturally occurring variables. – Is age related to political conservativism? – Are highly extraverted people less afraid of rejection than less extraverted people? – Is depression correlated with hypochondriasis? – Is I.Q. related to reaction time? measure two variables and determine whether there is a relationship present predictor <-> criterion No causality because: direction: there is no way to tell which is the cause or the effect third variable problem: some third variable that was not measured could be responsible for the relationship. ? Dr. Dimwit ? speeding ticket red car ? midnight basketball healthier vitamins ? larger feet less crime reading skills 3rd variable problem Estimate r for each case: No relationship Positive linear relationship Curvilinear Relationship: (Linear corr. not appropriate) Negative linear relationship • Correlation coefficient (r) +1.00 perfect positive correlation; -1.00 perfect negative correlation; 0 lack of correlation ABS|r| = magnitude of relationship sign (r) direction of relationship r2 = % variance of Y explained by X Types of correlation coefficients Pearson’s correlation coefficient: linear relationship between two interval / ratio variables. Spearman’s rank-order correlation: linear relationship between two variables measured using ordinal (ranked) scores. Point-biserial correlation: linear relationship between the scores from one continuous variable and one dichotomous (0 or 1) variable. Conceptual Formula for Pearson’s correlation: Xi X zx sx r zx z y N Positive r [z’s from x and y same sign] <-Neg zy | Pos zy-> <-Neg zy | Pos zy-> Negative r [z’s from x and y different sign] <-Neg zx | Pos zx-> <-Neg zx | Pos zx-> Example: Is education about other ethnicities correlated with tolerant attitudes towards others? Education Tolerance Zx Zy ZxZy Score Score 25 3 -1.05 -2.38 2.50 25 9 -1.05 -.62 .65 33 14 .24 .85 .20 35 11 .56 -.03 -.02 38 13 1.05 .56 .59 36 14 .72 .85 .61 31 12 -.08 .26 -.02 29 12 -.40 .26 -.10 22 9 -1.53 -.62 .95 41 14 1.53 .85 1.30 315 111 6.66 Xi X zx sx Yi Y zy sy s X i N 1 X 31.5 Y 11.1 Sx = 6.22 Sy = 3.41 X 2 N 6.66 10 .67 14.00 Tolerance Score r zx z y 16.00 12.00 10.00 8.00 6.00 4.00 2.00 0.00 0.00 10.00 20.00 30.00 40.00 Education Score 50.00 Could this be (1) due to chance, such as random error, or (2) very UNLIKELY to occur due to chance (< 5%)? Inferential statistics are needed. Testing Pearson’s r for significance Ho: ρ = 0 Ha: ρ ≠ 0 x<->y association does not exist x<->y association exists (non-directional) Using the t distribution: t N 2r 1 r 2 Using the table of critical values df = N – 2 (N is the number of pairs of scores) = 10 – 2 = 8 Using a t-table ha: an association exists between education & tolerance (two-tailed) alpha = .05 df = N – 2 10-2 = 8 df p= 0.05 1 12.71 2 3 4 5 6 7 8 9 10 11 12 13 14 4.30 3.18 2.78 2.57 2.45 2.36 2.31 2.26 2.23 2.20 2.18 2.16 2.14 p= 0.01 63.6 6 9.92 5.84 4.60 4.03 3.71 3.50 3.36 3.25 3.17 3.11 3.05 3.01 2.98 If t > 2.31, reject ho, left with ha. If t <= 2.31, retain ho Hypotheses Directional hypothesis – ha states whether the correlation is expected to be positive or negative (one-tailed test appropriate). Nondirectional hypothesis – ha states that there is an association, but does not specify the direction (two-tailed test appropriate). df = 60 alpha = .05 t = -2.0 t = +2.0 t = -1.67 Our example t tr = 3.96 tcrit df = 8 = N 2r 1 r 2 t 10 2 .67 1 .67 df = 10 – 2 = 8 2.31 APA Style: r(N) = value obtained, p = .## r(10) = .67, p = .002 2 Hypothesis Testing Rejecting the null hypothesis –concluding that the null hypothesis is wrong. Leaving us with the alternative hypothesis (ha) that there is an association between predictor and criterion Failing to reject the null hypothesis –concluding the null hypothesis (no association) is a likely possibility. We do not “accept” the null hypothesis (h0) , because the null hypothesis can never be proven. Errors • Type I error – a researcher rejects the null hypothesis when it is true (a false positive) – Alpha –probability of Type I error (most commonly p = .05). • Type II error – a researcher fails to reject the null hypothesis when it is false (a false negative) – Beta – the probability of Type II error (most commonly beta = .20). Statistical Decisions and Outcomes Reality (unknown) Statistical Decision Reject null Fail to reject hypothesis (we retain) null Correct: Type II Error (): Null hypothesis false Correlation exists Incorrectly conclude No correlation Null hypothesis Type I Error (): Incorrectly conclude true there is a correlation Correct: Correlation does not exist Power • Power is the probability that a study will detect effects that are really present (correctly reject the null hypothesis). • Power = 1-beta. Typically set at .80, or 80% chance of observing an effect when present. • Power analysis is used to decide how many participants are needed to detect a significant effect, since increasing participants increases power. Power Table: required n (rows) and r (columns) n .10 .20 .30 .40 .50 .60 .70 .80 .90 15 .06 .11 .19 .32 .50 .70 .88 .98 >.995 30 .08 .16 .37 .61 .83 .95 >.995 50 .11 .29 .57 .83 .97 >.995 100 .17 .52 .86 .99 >.995 200 .29 .81 .99 >.995 1000 .89 >.995 Power has a direct impact on likelihood of success and is often required for Masters and Dissertation proposals and fellowship and grant applications. Know your power, use your power! Effect Size Effect size: how strongly variables are related to eachother. Coefficient of determination (r2): the proportion of variability in the DV that is due to the IV (Range: .00 to 1.00). One indicator of effect size. r2 =.672 = .45 45% of variance in the criterion (tolerance) is explained by the predictor (education) Limitations • Pearson’s r only measures the degree of linear correlation • Problems in generalizing from sample correlations – Restricted or truncated ranges (results in smaller value) – Bivariate outliers RESTRICTION OF RANGE Full Range. r = .60 Restricted range, r = .20 Restriction of range often decreases r Marital Satisfaction Marital Satisfaction Over Time Wife Husband 1 2 3 4 5 6 7 8 Years of Marriage 9 10 Marital Satisfaction Over Time m en ire R et y pt Em Years of Marriage t t N es lt A du ng en t Yo u A do le sc ho ol Sc ol ch o Pr es fa nt In N o C hi ld Marital Satisfaction Previous slide data showed restriction of range! Outliers • An outlier is a score that is so deviant from the data that one can question whether it belongs in the data set. • > + / - 3 SD from the mean. • On-line outliers fall in the same pattern as the rest of the data artificially inflating r. • Off-line outliers fall outside of the pattern of the rest of the data artificially deflating r. IMPACT OF OUTLIERS ON CORRELATION On-line outlier … .. Off-line outlier Assumptions of the significance test Independent random sampling Normal distribution (and bivariate normal distribution) Interval or ratio scale variables SPSS Pearson’s r: Analyze → correlate → bivariate correlations Select variable you wish to correlate and place them in box Make sure Pearson’s is checked Choose one/two tailed OK SPSS Scatter Plot: GraphLegacy DialoguesScatter/Dot Select Simple Scatter Select variables for X and Y axis Ok Note: Select 3D Scatter to look at bivariate normal assumption for r. END Null Hypothesis Testing and Inferential Statistics Partitioning of Variance Systematic variance: the portion of the participant’s score (e.g., behavior) that is related to variables within the study Error variance: the portion of the participant’s score that is unaccounted for by variables within the study total variance = systematic variance + error variance t-test, F-test, r, β based on: systematic variance error variance