Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
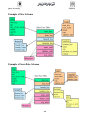
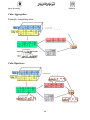
Query Processing Chapter6 Contents Contents ................................................................................................................................................................199 Present Business Scenario ....................................................................................................................................200 Data Modeling and Normalization .......................................................................................................................201 A Data Warehouse ! .............................................................................................................................................203 What is Data Warehouse?.................................................................................................................................204 Data Warehousing -- It is a process ..................................................................................................................204 Evolution ..........................................................................................................................................................206 Data Warehouse—Subject-Oriented ....................................................................................................................207 Data Warehouse—Integrated ...............................................................................................................................208 Data Warehouse—Time Variant ..........................................................................................................................208 Data Warehouse—Non-Volatile...........................................................................................................................208 Data Warehouse vs. Heterogeneous DBMS .........................................................................................................209 OLTP vs. OLAP ...................................................................................................................................................209 Entering Data into the Warehouse ........................................................................................................................212 Data Warehouse Components ..............................................................................................................................213 Loading the Warehouse ........................................................................................................................................214 Data Transformation Terms..................................................................................................................................216 Loading .................................................................................................................................................................199 Data -- Heart of the Data Warehouse ...................................................................................................................201 Vertical Partitioning .............................................................................................................................................203 Schema Design .....................................................................................................................................................204 Dimension Tables .................................................................................................................................................204 Star Schema ..........................................................................................................................................................205 Snowflake schema ................................................................................................................................................206 Fact Constellation .................................................................................................................................................206 Cube: A Lattice of Cuboids ..................................................................................................................................208 Defining a Star Schema in DMQL .......................................................................................................................211 Concept Hierarchy: Dimension (location) ............................................................................................................213 On-Line Analytical Processing (OLAP)...............................................................................................................215 Limitations of SQL ...............................................................................................................................................216 197 Query Processing Chapter6 Typical OLAP Operations ....................................................................................................................................219 Aggregates ............................................................................................................................................................223 Cube Operation.....................................................................................................................................................228 Cross Tab ..............................................................................................................................................................231 Cross Tabulation of sales by item-name and color ..........................................................................................231 Cross Tabulation With Hierarchy .....................................................................................................................232 Relational Representation of Crosstabs ............................................................................................................232 Three-Dimensional Data Cube .........................................................................................................................233 Data warehouse implementation … .....................................................................................................................234 Relational OLAP: 3 Tier DSS .............................................................................................................................235 MOLAP: 2 Tier DSS ............................................................................................................................................236 Data Warehouse Back-End Tools and Utilities ....................................................................................................236 Index Structures ....................................................................................................................................................237 Bit Maps ...............................................................................................................................................................238 Join .......................................................................................................................................................................239 What to Materialize? ............................................................................................................................................240 Meta data ..............................................................................................................................................................242 Recipe for a Successful Warehouse......................................................................................................................243 DW and OLAP Research Issues ...........................................................................................................................244 Data Warehouse Usage.........................................................................................................................................246 An OLAM Architecture .......................................................................................................................................248 Summary...............................................................................................................................................................248 Exercises ...............................................................................................................................................................249 198 Query Processing Chapter6 Data Warehouse Extracted from : Han - Data Mining: Concepts and Techniques S. Sudarshan and Krithi Ramamritham – Slides DATA WAREHOUSING AND DATA MINING Objective To gain an understanding about datawarehous, muli-dimentional data model and OLAP. Contents Motivation What is a data warehouse? A multi-dimensional data model Data warehouse implementation From data warehousing to data mining Motivation Over the last 20 years, $1 trillion has been invested in new computer systems to gain competitive advantage. The vast majority of these systems have automated business processes, to make them faster, cheaper, and more responsive to the customer. Electronic point of sales (EPOS) at supermarkets, itemized billing at telecommunication companies (telcos), and mass market mailing at catalog companies are some examples of such ―Operational Systems‖. 199 Query Processing Chapter6 Present Business Scenario Presently almost all businesses have operational systems and these systems are not giving them any competitive advantage. These systems have gathered a vast amount of ―data‖ over the years. The companies are now realizingthe importance of this ―hidden treasure‖ of information. Efforts are now on to tap into this information that will improve the quality of their decision-making. A ―data warehouse‖ is nothing but a repository of data collected from the various operational systems of an organization. This data is then comprehensively analyzed to gain competitive advantage. The analysis is basically used in decision making at the top level. A data warehousing system can perform advanced analyses of operational data without impacting operational systems. Decision support systems & Transactional Databases Operational or transactional databases are designed to process individual transactions quickly and efficiently. This type of transaction-based interaction is known as On-Line Transactional Processing (OLTP). OLTP is very fast and efficient at recording the business transactions not so good at providing answers to high-level strategic questions. In contrast, decision support systems are subject oriented. 200 Query Processing Chapter6 They incorporate facilities for reporting, analyzing, and mining data about a particular topic such as heart disease. Data Modeling and Normalization Relationships: o One-to-One Relationships o One-to-Many Relationships o Many-to-Many Relationships Normal forms o First Normal Form o Second Normal Form o Third Normal Form Type ID Make Customer ID Year Income Range Vehicle - Type Customer 201 Query Processing Chapter6 Table 6.1a • Relational Table for Vehicle-Type Type ID Make Year 4371 6940 4595 2390 Chevrolet Cadillac Chevrolet Cadillac 1995 2000 2001 1997 Table 6.1b • Relational Table for Customer Customer ID Income Range ($) Type ID 0001 0002 0003 0004 0005 70–90K 30–50K 70–90K 30–50K 70–90K 2390 4371 6940 4595 2390 Table 6.2 • Join of Tables 6.1a and 6.1b Customer ID Income Range ($) Type ID Make Year 0001 0002 0003 0004 0005 70–90K 30–50K 70–90K 30–50K 70–90K 2390 4371 6940 4595 2390 Cadillac Chevrolet Cadillac Chevrolet Cadillac 1997 1995 2000 2001 1997 Is this table Normalized? ―Is there a relationship between salary and type of a car?‖ This kind of relationship is not of interest in a transactional environment, but it is of primary importance to decision support. Relationships showing this type of redundancy can only be observed by denormalizing the data. 202 Query Processing Chapter6 This leads to new questions about o which entities to combine, as well as o how and where to store and maintain the combined entities A better choice is to have:o Mechanism for storing, maintaining, and processing transactional data, and another o To house data for decision support Contents Motivation What is a data warehouse? A multi-dimensional data model Data warehouse implementation From data warehousing to data mining A Data Warehouse ! A data warehouse archives information gathered from multiple sources, and stores it under a unified schema, at a single site. o Important for large businesses which generate data from multiple divisions, possibly at multiple sites. When transactional data is no longer of value to the operational environment, it is removed from the database. If a business is without a decision support (DS) facility, the data is archived and eventually destroyed. 203 Query Processing Chapter6 However, if there is a DS environment, the data is transported to some type of interactive medium commonly referred to as a data warehouse. What is Data Warehouse? A decision support database that is maintained separately from the organization’s operational database. Support information processing by providing a solid platform of consolidated, historical data for analysis. ―A data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management’s decisionmaking process.‖—W. H. Inmon Data warehousing: o The process of constructing and using data warehouses Data Warehousing -- It is a process Technique for assembling and managing data from various sources for the purpose of answering business questions. Thus making decisions that were not previous possible. A decision support database maintained separately from the organization’s operational database 204 Query Processing Chapter6 Problems faced by users I can’t find the data I need o data is scattered over the network o many versions, subtle differences I can’t get the data I need o need an expert to get the data I can’t understand the data I found o available data poorly documented I can’t use the data I found o results are unexpected o data needs to be transformed from one form to other What are the users saying... Data should be integrated across the enterprise Summary data has a real value to the organization Historical data holds the key to understanding data over time What-if capabilities are required 205 Query Processing Chapter6 Evolution 60’s: Batch reports o hard to find and analyze information o inflexible and expensive, reprogram every new request 70’s: Terminal-based DSS and EIS (executive information systems) o still inflexible, not integrated with desktop tools 80’s: Desktop data access and analysis tools o query tools, spreadsheets, GUIs o easier to use, but only access operational databases 90’s: Data warehousing with integrated OLAP engines and tools Very Large Data Bases Terabytes -- 10^12 bytes: Walmart -- 24 Terabytes Petabytes -- 10^15 bytes: Geographic Information Systems Exabytes -- 10^18 bytes: National Medical Records Zettabytes -- 10^21 bytes: Weather images Zottabytes -- 10^24 bytes: Intelligence Agency Videos Data Warehouse A data warehouse is a o subject-oriented o integrated o time-varying 206 Query Processing Chapter6 o non-volatile collection of data that is used primarily in organizational decision making. Bill Inmon, Building the Data Warehouse 1996 Data Warehouse—Subject-Oriented Organized around major subjects, such as customer, product, sales. Focusing on the modeling and analysis of data for decision makers, not on daily operations or transaction processing. Provide a simple and concise view around particular subject issues by excluding data that are not useful in the decision support process. Example: 207 Query Processing Chapter6 Data Warehouse—Integrated Constructed by integrating multiple, heterogeneous data sources o relational databases, flat files, on-line transaction records Data cleaning and data integration techniques are applied. o Ensure consistency in naming conventions, encoding structures, attribute measures, etc. among different data sources E.g., Hotel price: currency, tax, breakfast covered, etc. o When data is moved to the warehouse, it is converted. Data Warehouse—Time Variant The time horizon for the data warehouse is significantly longer than that of operational systems. o Operational database: current value data. o Data warehouse data: provide information from a historical perspective (e.g., past 5-10 years) Every key structure in the data warehouse o Contains an element of time, explicitly or implicitly o But the key of operational data may or may not contain ―time element‖. Data Warehouse—Non-Volatile A physically separate store of data transformed from the operational environment. Operational update of data does not occur in the data warehouse environment. 208 Query Processing Chapter6 o Does not require transaction concurrency control mechanisms processing, recovery, and o Requires only two operations in data accessing: initial loading of data and access of data. Data Warehouse vs. Heterogeneous DBMS Traditional heterogeneous DB integration: o Build wrappers/mediators on top of heterogeneous databases o Query driven approach When a query is posed to a client site, a meta-dictionary is used to translate the query into queries appropriate for individual heterogeneous sites involved, and the results are integrated into a global answer set Data warehouse: Information from heterogeneous sources is integrated in advance and stored in warehouses for direct query and analysis OLTP vs. OLAP OLTP (on-line transaction processing) o Major task of traditional relational DBMS o Day-to-day operations: purchasing, inventory, banking, manufacturing, payroll, registration, accounting, etc. OLAP (on-line analytical processing) o Major task of data warehouse system 209 Query Processing Chapter6 o Data analysis and decision making OLTP OLAP users clerk, IT professional, salespersons, administrator Business analysts, managers, Primary purpose day to day operations decision support DB design application-oriented subject-oriented data current, up-to-date historical, detailed, flat relational summarized, multidimensional isolated integrated, consolidated usage repetitive ad-hoc access read/write lots of scans index/hash on prim. key unit of work short, narrow, planned, and simple updates and queries, Broad, complex queries and analysis # records accessed tens, many constant updates and queries on one or few table rows Millions, periodic batch updates and queries requiring many or all rows #users thousands hundreds DB size 100MB-GB 100GB-TB 210 Query Processing Design goal Chapter6 Performance throughput, availability Ease of flexible access and use Why Separate Data Warehouse? High performance for both systems o DBMS— tuned for OLTP: access methods, indexing, concurrency control, recovery o Warehouse—tuned for OLAP: complex multidimensional view, consolidation. OLAP queries, Different functions and different data: o missing data: Decision support requires historical data which operational DBs do not typically maintain o data consolidation: DS requires consolidation (aggregation, summarization) of data from heterogeneous sources o data quality: different sources typically use inconsistent data representations, codes and formats which have to be reconciled 211 Query Processing Chapter6 Entering Data into the Warehouse Data mart is a data store that is similar to a warehouse but limits its focus to a single subject. Independent data mart is structured by using operational data as well as external data sources. Dependent data mart can be structured by using data from a warehouse. External data represents items such as economic indicators, weather information, (i.e., information not specific to the internal organization) ETL (Extract, Transform, Load) Responsibilities of ETL includes: o Extracting data from one or more of the input sources o Cleaning and transforming the external data as necessary o Loading the data into the warehouse 212 Query Processing Chapter6 Data Warehouse Components Components of the Warehouse Data Extraction, Cleaning and Loading The Warehouse Analyze and Query -- OLAP Tools Metadata Data Mining tools Need for Data warehouse Can data mining continue to take place in environments not supporting a data warehouse? Yes, but as volume of data continue to be collected for purpose of decision support, the need for organized, efficient data storage and retrieval architectures has become quite apparent, thus the need for the data warehouse. 213 Query Processing Chapter6 Loading the Warehouse Extract and Transform the data before it is loaded Source Data Typically host based, legacy applications o Customized applications, COBOL, 3GL, 4GL Point of Contact Devices o POS, ATM, Call switches External Sources o Nielsen’s, Acxiom, CMIE, Vendors, Partners 214 Query Processing Chapter6 Data Quality - The Reality Tempting to think creating a data warehouse is simply extracting operational data and entering into a data warehouse Nothing could be farther from the truth Warehouse data comes from disparate questionable sources Data Integration Across Sources Data Transformation Example 215 Query Processing Chapter6 Data Integrity Problems Same person, different spellings o Agarwal, Agrawal, Aggarwal etc... Multiple ways to denote company name o Persistent Systems, PSPL, Persistent Pvt. LTD. Different account numbers generated by different applications for the same customer Required fields left blank Invalid product codes collected at point of sale o manual entry leads to mistakes o ―in case of a problem use 9999999‖ Data Transformation Terms Extracting Conditioning Scrubbing Merging Householding 216 Query Processing Chapter6 Enrichment Scoring Loading Validating Updating Extracting o Capture of data from operational source in ―as is‖ status o Sources for data generally in legacy mainframes in VSAM, IMS, IDMS, DB2; more data today in relational databases on Unix Conditioning o The conversion of data types from the source to the target data store (warehouse) -- always a relational database Householding o Identifying all members of a household (living at the same address) o Ensures only one mail is sent to a household o Can result in substantial savings: eg catalog postage. Enrichment o Bring data from external sources to augment/enrich operational data. Data sources include Dunn and Bradstreet, A. C. Nielsen, CMIE, IMRA etc... Scoring 198 Query Processing Chapter6 o computation of a probability of an event. e.g..., chance that a customer will defect to AT&T from MCI, chance that a customer is likely to buy a new product Scrubbing/Cleaning Data Sophisticated transformation tools. Used for cleaning the quality of data Clean data is vital for the success of the warehouse Example o Naming problems, Coding, … Cleaning Tools o Apertus -- Enterprise/Integrator o Vality -- IPE o Postal Soft Loading After extracting, scrubbing, cleaning, validating etc. need to load the data into the warehouse Issues o huge volumes of data to be loaded o small time window available when warehouse can be taken off line (usually nights) o when to build index and summary tables 199 Query Processing Chapter6 o allow system administrators to monitor, cancel, resume, change load rates o Recover gracefully -- restart after failure from where you were and without loss of data integrity When to Refresh? periodically (e.g., every night, every week) or after significant events on every update: not warranted unless warehouse data require current data (up to the minute stock quotes) refresh policy set by administrator based on user needs and traffic possibly different policies for different sources Refresh Techniques Full Extract from base tables o read entire source table: too expensive o maybe the only choice for legacy systems Detecting Changes Create a snapshot log table to record ids of updated rows of source data and timestamp Detect changes by: o Defining after row triggers to update snapshot log when source table changes o Using regular transaction log to detect changes to source data 200 Query Processing Chapter6 Contents Motivation What is a data warehouse? A multi-dimensional data model Data warehouse implementation From data warehousing to data mining Data -- Heart of the Data Warehouse Heart of the data warehouse is the data itself! Corporate memory Data is organized in a way that represents business -- subject orientation Data Warehouse Structure Subject Orientation -- customer, product, policy, account etc... A subject may be implemented as a set of related tables. o E.g., customer may be five tables o base customer (1985-87) custid, from date, to date, name, phone, dob o base customer (1988-90) custid, from date, to date, name, credit rating, employer o customer activity (1986-89) -- monthly summary o customer activity detail (1987-89) custid, activity date, amount, clerk id, order no 201 Query Processing Chapter6 o customer activity detail (1990-91) custid, activity date, amount, line item no, order no Data Analysis and OLAP Aggregate functions summarize large volumes of data Online Analytical Processing (OLAP) o Interactive analysis of data, allowing data to be summarized and viewed in different ways in an online fashion (with negligible delay) Data that can be modeled as dimension attributes and measure attributes are called multidimensional data model. Measure and Dimension attributes Measure attributes define some value, and can be aggregated upon. For instance, the attribute number of the sales relation is a measure attribute, since it measures the number of units sold. Dimension attributes define the dimensions on which measure attributes, and summaries of measure attributes, are viewed. Data Granularity in Warehouse Summarized data stored o reduce storage costs o reduce cpu usage o increases performance since smaller number of records to be processed o design around traditional high level reporting needs 202 Query Processing Chapter6 o tradeoff with volume of data to be stored and detailed usage of data Granularity in Warehouse Can not answer some questions with summarized data o Did John call Sara last month? Not possible to answer if total duration of calls by John over a month is only maintained and individual call details are not. Detailed data too voluminous Tradeoff is to have dual level of granularity o Store summary data on disks 95% of DSS processing done against this data o Store detail on tapes 5% of DSS processing against this data Vertical Partitioning 203 Query Processing Chapter6 Schema Design Dataware house organization o must look like business o must be recognizable by business user o approachable by business user o Must be simple Schema Types o Star Schema o Fact Constellation Schema o Snowflake schema Two types of tables o Dimension o Measure (Fact) Dimension Tables Dimension tables o Define business in terms already familiar to users o Wide rows with lots of descriptive text o Tables with few rows o Joined to fact table by a foreign key o heavily indexed o typical dimensions 204 Query Processing Chapter6 time periods, geographic region (markets, cities), products, customers, salesperson, etc. Fact (measure) Table Contains the measure attributes Central table o mostly raw numeric items o narrow rows, a few columns at most o large number of rows (millions to a billion) o Access via dimensions Star Schema A single fact table and for each dimension one dimension table Does not capture hierarchies directly 205 Query Processing Chapter6 Snowflake schema Represent dimensional hierarchy directly by normalizing tables. Easy to maintain and saves storage Fact Constellation Multiple fact tables that share many dimension tables Booking and Checkout may share many dimension tables in the hotel industry 206 Query Processing Chapter6 De-normalization Normalization in a data warehouse may lead to lots of small tables Can lead to excessive I/O’s since many tables have to be accessed De-normalization is the answer especially since updates are rare Multidimensional data model A data warehouse is based on a multidimensional data model which views data in the form of a data cube A data cube, such as sales, allows data to be modeled and viewed in multiple dimensions o Dimension tables, such as item (item_name, brand, type), or time(day, week, month, quarter, year) o Fact table contains measures (such as dollars_sold) and keys to each of the related dimension tables In data warehousing literature, an n-D base cuboid is called a base cuboid. The top most 0-D cuboid, which holds the highest-level of summarization, is called the apex cuboid. The lattice of cuboids forms a data cube. 207 Query Processing Chapter6 Cube: A Lattice of Cuboids Conceptual Modeling of Data Warehouses Modeling data warehouses: dimensions & measures o Star schema: A fact table in the middle connected to a set of dimension tables o Snowflake schema: A refinement of star schema where some dimensional hierarchy is normalized into a set of smaller dimension tables o Fact constellations: Multiple fact tables share dimension tables, viewed as a collection of stars, therefore called galaxy schema or fact constellation 208 Query Processing Chapter6 Example of Star Schema Example of Snowflake Schema 209 Query Processing Chapter6 Example of Fact Constellation A Data Mining Query Language, DMQL: Language Primitives Cube Definition (Fact Table) define cube <cube_name> [<dimension_list>]: <measure_list> Dimension Definition ( Dimension Table ) define dimension <dimension_name> as (<attribute_or_subdimension_list>) Special Case (Shared Dimension Tables) o First time as ―cube definition‖ o define dimension <dimension_name> as <dimension_name_first_time> in cube <cube_name_first_time> 210 Query Processing Chapter6 Defining a Star Schema in DMQL define cube sales_star [time, item, branch, location]: dollars_sold = sum(sales_in_dollars), avg_sales = avg(sales_in_dollars), units_sold = count(*) define dimension time as (time_key, day, day_of_week, month, quarter, year) define dimension item as (item_key, item_name, brand, type, supplier_type) define dimension branch as (branch_key, branch_name, branch_type) define dimension location as (location_key, street, city, province_or_state, country) Defining a Snowflake Schema in DMQL define cube sales_snowflake [time, item, branch, location]: dollars_sold = sum(sales_in_dollars), avg_sales = avg(sales_in_dollars), units_sold = count(*) define dimension time as (time_key, day, day_of_week, month, quarter, year) define dimension item as (item_key, item_name, brand, type, supplier(supplier_key, supplier_type)) define dimension branch as (branch_key, branch_name, branch_type) define dimension location as (location_key, street, city(city_key, province_or_state, country)) 211 Query Processing Chapter6 Defining a Fact Constellation in DMQL define cube sales [time, item, branch, location]: dollars_sold = sum(sales_in_dollars), avg_sales = avg(sales_in_dollars), units_sold = count(*) define dimension time as (time_key, day, day_of_week, month, quarter, year) define dimension item as (item_key, item_name, brand, type, supplier_type) define dimension branch as (branch_key, branch_name, branch_type) define dimension location as (location_key, street, city, province_or_state, country) define cube shipping [time, item, shipper, from_location, to_location]: dollar_cost = sum(cost_in_dollars), unit_shipped = count(*) define dimension time as time in cube sales define dimension item as item in cube sales define dimension shipper as (shipper_key, shipper_name, location as location in cube sales, shipper_type) define dimension from_location as location in cube sales define dimension to_location as location in cube sales 212 Query Processing Chapter6 Concept Hierarchy: Dimension (location) Concept Hierarchy … Example of dbminer software Sales volume as a function of product, month, and region 213 Query Processing Chapter6 A Sample Data Cube Cuboids Corresponding to the Cube 214 Query Processing Chapter6 On-Line Analytical Processing (OLAP) Making Decision Support Possible Typical OLAP Queries Write a multi-table join to compare sales for each product this year vs. last year. Repeat the above process to find the top 5 product contributors to margin. Repeat the above process to find the sales of a product line to new vs. existing customers. 215 Query Processing Chapter6 Repeat the above process to find the customers that have had negative sales growth. Limitations of SQL What Is OLAP? Online Analytical Processing - coined by EF Codd in 1994 paper contracted by Arbor Software* Generally synonymous with earlier terms such as Decisions Support, Business Intelligence, Executive Information System, Multidimensional Database 216 Query Processing Chapter6 The OLAP Market Rapid growth in the enterprise market o 1995: $700 Million o 1997: $2.1 Billion Significant consolidation activity among major DBMS vendors o 10/94: Sybase acquires ExpressWay o 7/95: Oracle acquires Express o 11/95: Informix acquires Metacube o 1/97: Arbor partners up with IBM o 10/96: Microsoft acquires Panorama Result: OLAP shifted from small vertical niche to mainstream DBMS category Strengths of OLAP It is a powerful visualization paradigm It provides fast, interactive response times It is good for analyzing time series It can be useful to find some clusters and outliers Many vendors offer OLAP tools 217 Query Processing Chapter6 Multi-dimensional Data Data Cube Lattice Cube lattice Can materialize some groupbys, compute others on demand Question: which groupbys to materialze? Question: what indices to create Question: how to organize data (chunks, etc) 218 Query Processing Chapter6 Typical OLAP Operations Pivot (rotate): o reorient the cube, visualization, 3D to series of 2D planes. Roll up : summarize data o by climbing up hierarchy or by dimension reduction Drill down : reverse of roll-up o from higher level summary to lower level summary or detailed data, or introducing new dimensions Slice and dice: o project and select Browsing a Data Cube Visualization OLAP capabilities Interactive manipulation 219 Query Processing Chapter6 Visualizing Neighbors is simpler A Visual Operation: Pivot (Rotate) 220 Query Processing Chapter6 Relational presentation vs multi-dimensional cube Aggregates Add up amounts for day 1 In SQL: SELECT sum(amt) FROM SALE WHERE date = 1 221 Query Processing Chapter6 Add up amounts by day In SQL: SELECT date, sum(amt) FROM SALE GROUP BY date Another Example Add up amounts by day, product In SQL: SELECT date, sum(amt) FROM SALE GROUP BY date, prodId 222 Query Processing Chapter6 Roll-up and Drill Down Aggregates Operators: sum, count, max, min, median, ave ―Having‖ clause Using dimension hierarchy o average by region (within store) o maximum by month (within date) 223 Query Processing Chapter6 Cube Aggregation Example: computing sums Cube Operators 224 Query Processing Chapter6 Extended Cube Aggregation Using Hierarchies 225 Query Processing Chapter6 “Slicing and Dicing” A Star-Net Query Model 226 Query Processing Chapter6 Nature of OLAP Analysis Aggregation -- (total sales, percent-to-total) Comparison -- Budget vs. Expenses Ranking -- Top 10, quartile analysis Access to detailed and aggregate data Complex criteria specification Visualization Multidimensional Spreadsheets Analysts need spreadsheets that support o pivot tables (cross-tabs) o drill-down and roll-up o slice and dice o sort o selections o derived attributes Eg. Excel pivot table SQL Extensions Front-end tools require o Extended Family of Aggregate Functions rank, median, mode 227 Query Processing Chapter6 o Reporting Features running totals, cumulative totals o Results of multiple group by total sales by month and total sales by product o Data Cube Cube Operation Cube definition and computation in DMQL define cube sales[item, city, year]: sum(sales_in_dollars) compute cube sales Transform it into a SQL-like language (with a new operator cube by, introduced by Gray et al.’96) SELECT item, city, year, SUM (amount) FROM SALES CUBE BY item, city, year Need compute the following Group-Bys 228 Query Processing Chapter6 Typical OLAP Problems Data Explosion On-line Analytical Processing (OLAP) OLAP is a query-based methodology that supports data analysis in a multidimensional environment. OLAP is a valuable tool for o verifying or refuting human-generated hypotheses and o performing manual data mining. OLAP engine logically structures multidimensional data in the form of a cube. 229 Query Processing Chapter6 Month = Dec. Category = Vehicle Region = Two Amount = 6,720 Count = 110 Dec. Nov. Oct. Sep. Month Aug. Jul. Jun. May Apr. Mar. Feb. Jan. Miscellaneous Restaurant Retail Vehicle Travel Supermarket On e Tw o Fo ur Th ree n gi o Re Category The Cube The Cube displays three dimensions o Purchase category o Time in months o Regions Difficult to picture a data cube having more than three dimensions but crosstabs can be used as views on a data cube 230 Query Processing Chapter6 Cross Tab A cross-tab is a table where o values for one of the dimension attributes form the row headers, values for another dimension attribute form the column headers Other dimension attributes are listed on top o Values in individual cells are (aggregates of) the values of the dimension attributes that specify the cell. Cross Tabulation of sales by item-name and color The table above is an example of a cross-tabulation (cross-tab), also referred to as a pivot-table. 231 Query Processing Chapter6 Cross Tabulation With Hierarchy o Crosstabs can be easily extended to deal with hierarchies Can drill down or roll up on a hierarchy Relational Representation of Crosstabs Crosstabs can be represented as relations 232 Query Processing Chapter6 Three-Dimensional Data Cube A data cube is a multidimensional generalization of a crosstab Cannot view a three-dimensional object in its entirety but crosstabs can be used as views on a data cube Contents Motivation What is a data warehouse? A multi-dimensional data model Data warehouse implementation From data warehousing to data mining 233 Query Processing Chapter6 Data warehouse implementation … ROLAP servers vs. MOLAP servers Index Structures What to Materialize? Metadata Relational OLAP (ROLAP) Architecture Use relational or extended-relational DBMS to store and manage warehouse data and OLAP middle ware to support missing pieces 234 Query Processing Chapter6 Relational OLAP: 3 Tier DSS Multidimensional OLAP (MOLAP) Architecture Array-based multidimensional storage engine (sparse matrix techniques) providing fast indexing to pre-computed summarized data 235 Query Processing Chapter6 MOLAP: 2 Tier DSS Data Warehouse Back-End Tools and Utilities Data extraction: o get data from multiple, heterogeneous, and external sources Data cleaning: o detect errors in the data and rectify them when possible Data transformation: o convert data from legacy or host format to warehouse format Load: o sort, summarize, consolidate, compute views, check integrity, and build indicies and partitions Refresh o propagate the updates from the data sources to the warehouse 236 Query Processing Chapter6 Index Structures Traditional Access Methods o B-trees, hash tables, … Popular in Warehouses o inverted lists o bit map indexes o join indexes Inverted Lists 237 Query Processing Chapter6 Using Inverted Lists Query: o Get people with age = 20 and name = ―fred‖ List for age = 20: r4, r18, r34, r35 List for name = ―fred‖: r18, r52 Answer is intersection: r18 Bit Maps 238 Query Processing Chapter6 Using Bit Maps Query: o Get people with age = 20 and name = ―fred‖ List for age = 20: 1101100000 List for name = ―fred‖: 0100000001 Answer is intersection: 010000000000 Good if domain cardinality small Bit vectors can be compressed Join ―Combine‖ SALE, PRODUCT relations In SQL: SELECT * FROM SALE, PRODUCT 239 Query Processing Chapter6 Join Indexes What to Materialize? Store in warehouse results useful for common queries Example: 240 Query Processing Chapter6 Materialization Factors Type/frequency of queries Query response time Storage cost Update cost Cube Aggregates Lattice 241 Query Processing Chapter6 Meta data Meta data is the data defining warehouse objects. It has the following kinds o Description of the structure of the warehouse schema, view, dimensions, hierarchies, derived data defn, data mart locations and contents o Operational meta-data data lineage (history of migrated data and transformation path), currency of data (active, archived, or purged), monitoring information (warehouse usage statistics, error reports, audit trails) 242 Query Processing Chapter6 o The algorithms used for summarization o The mapping from operational environment to the data warehouse o Data related to system performance warehouse schema, view and derived data definitions o Business data business terms and definitions, ownership of data, charging policies Recipe for a Successful Warehouse For a Successful Warehouse From Larry Greenfield, http://pwp.starnetinc.com/larryg/index.html From day one establish that warehousing is a joint user/builder project Establish that maintaining data quality will be an ONGOING joint user/builder responsibility Train the users one step at a time Look closely at the data extracting, cleaning, and loading tools Determine a plan to test the integrity of the data in the warehouse Data Warehouse Pitfalls You are going to spend much time extracting, cleaning, and loading data Despite best efforts at project management, data warehousing project scope will increase 243 Query Processing Chapter6 You are going to find problems with systems feeding the data warehouse You will find the need to store data not being captured by any existing system You will need to validate data not being validated by transaction processing systems Some transaction processing systems feeding the warehousing system will not contain detail After end users receive query and report tools, requests for IS written reports may increase 'Overhead' can eat up great amounts of disk space You will fail if you concentrate on resource optimization to the neglect of project, data, and customer management issues and an understanding of what adds value to the customer DW and OLAP Research Issues Data cleaning o focus on data inconsistencies, not schema differences o data mining techniques Physical Design o design of summary tables, partitions, indexes o tradeoffs in use of different indexes Query processing o selecting appropriate summary tables 244 Query Processing Chapter6 o dynamic optimization with feedback o query optimization: cost estimation, use of transformations, search strategies o partitioning query processing between OLAP server and backend server. Warehouse Management o resource management o incremental refresh techniques o computing summary tables during load o failure recovery during load and refresh o process management: scheduling queries, load and refresh o Query processing, caching o use of workflow technology for process management Contents Decision support system Transactional Databases What is a data warehouse? A multi-dimensional data model Data warehouse implementation From data warehousing to data mining 245 Query Processing Chapter6 Data Warehouse Usage Three kinds of data warehouse applications o Information processing – informative reporting supports querying, basic statistical analysis, and reporting using crosstabs, tables, charts and graphs o Analytical processing Multidimensional data analysis of data warehouse data supports basic OLAP operations, slice-dice, drilling, pivoting o Data mining knowledge discovery from hidden patterns supports associations, constructing analytical models, performing classification and prediction, and presenting the mining results using visualization tools. 246 Query Processing Chapter6 From On-Line Analytical Processing to On Line Analytical Mining (OLAM) Why online analytical mining? o High quality of data in data warehouses DW contains integrated, consistent, cleaned data o Available information processing structure surrounding data warehouses ODBC, OLEDB, Web accessing, service facilities, reporting and OLAP tools o OLAP-based exploratory data analysis mining with drilling, dicing, pivoting, etc. o On-line selection of data mining functions integration and swapping of multiple mining functions, algorithms, and tasks. 247 Query Processing Chapter6 An OLAM Architecture Summary Data warehouse o A subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management’s decision-making process A multi-dimensional model of a data warehouse o Star schema, snowflake schema, fact constellations o A data cube consists of dimensions & measures 248 Query Processing Chapter6 OLAP operations: drilling, rolling, slicing, dicing and pivoting OLAP servers: ROLAP, MOLAP Efficient computation of data cubes o Partial vs. full vs. no materialization o Multiway array aggregation o Bitmap index and join index implementations Further development of data cube technology o From OLAP to OLAM (on-line analytical mining) Exercises Use SQL-Server to create a cube. Your cube should have at least three dimensions. Experiment with the OLAP operation. Explore the Cube and OLAP capabilities in relational DBMSs such as SQL Server, Oracle, Postgress, Mysql, … 249