Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
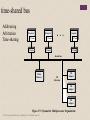
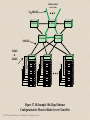
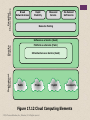
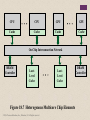
+ Chapter 17 Parallel Processing © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + Multiple Processor Organization Single instruction, single data (SISD) stream Single processor executes a single instruction stream to operate on data stored in a single memory Uniprocessors fall into this category Single instruction, multiple data (SIMD) stream A single machine instruction controls the simultaneous execution of a number of processing elements on a lockstep basis Vector and array processors fall into this category © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Multiple instruction, single data (MISD) stream A sequence of data is transmitted to a set of processors, each of which executes a different instruction sequence Not commercially implemented Multiple instruction, multiple data (MIMD) stream A set of processors simultaneously execute different instruction sequences on different data sets SMP(Symmetric multiprocessing)s, clusters and NUMA(Non-uniform memory access) systems fit this category Processor Organizations Single Instruction, Single Data Stream (SISD) Single Instruction, Multiple Data Stream (SIMD) Multiple Instruction, Single Data Stream (MISD) Multiple Instruction, Multiple Data Stream (MIMD) Uniprocessor Vector Processor Array Processor Shared Memory (tightly coupled) Distributed Memory (loosely coupled) Clusters Symmetric Multiprocessor (SMP) Nonumiform Memory Access (NUMA) Figure 17.1 A Taxonomy of Parallel Processor Architectures © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. CU IS PU DS MU PU1 (a) SISD PU2 IS DS DS LM1 LM2 CU CUn IS IS PU1 PU2 PUn DS PUn DS LMn (b) SIMD (with distributed memory) DS DS CU1 CU2 IS IS PU1 PU2 DS DS LM1 LM2 (c) MIMD (with shared memory) CU = control unit IS = instruction stream PU = processing unit DS = data stream MU = memory unit LM = local memory SISD = single instruction, single data stream SIMD = single instruction, multiple data stream MIMD = multiple instruction, multiple data stream CUn IS PUn DS (d) MIMD (with distributed memory) Figure 17.2 Alternative Computer Organizations © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. LMn Interconnection Network CU2 IS Shared Memory CU1 Symmetric Multiprocessor (SMP) A stand alone computer with the following characteristics: Two or more similar processors of comparable capacity Processors share same memory and I/O facilities • Processors are connected by a bus or other internal connection • Memory access time is approximately the same for each processor All processors share access to I/O devices • Either through same channels or different channels giving paths to same devices © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. All processors can perform the same functions (hence “symmetric”) System controlled by integrated operating system • Provides interaction between processors and their programs at job, task, file and data element levels Time Process 1 Process 2 Potential but not guaranteed advantages: Performance Availability Incremental growth Scaling Process 3 (a) Interleaving (multiprogramming, one processor) Process 1 Process 2 Process 3 (b) Interleaving and overlapping (multiprocessing; two processors) Blocked Running Figure 17.3 Multiprogramming and Multiprocessing © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Processor Processor Processor I/O I/O Interconnection Network I/O Main Memory There are two or more processors. Each processor is selfcontained, including a control unit, ALU, registers, and, typically, one or more levels of cache. Each processor has access to a shared main memory and the I/O devices through some form of interconnection mechanism. The processors can communicate with each other through memory Figure 17.4 Generic Block Diagram of a Tightly Coupled Multiprocessor time-shared bus Addressing Arbitration Time-sharing Processor Processor L1 Cache Processor L1 Cache L2 Cache L1 Cache L2 Cache L2 Cache shared bus Main Memory I/O Subsytem I/O Adapter I/O Adapter I/O Adapter Figure 17.5 Symmetric Multiprocessor Organization © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + The bus organization has several attractive features: Simplicity Simplest approach to multiprocessor organization Flexibility Generally easy to expand the system by attaching more processors to the bus Reliability The bus is essentially a passive medium and the failure of any attached device should not cause failure of the whole system © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + Disadvantages of the bus organization: Main drawback is performance All memory references pass through the common bus Performance is limited by bus cycle time Each processor should have cache memory Reduces the number of bus accesses Leads to problems with cache coherence If a word is altered in one cache it could conceivably invalidate a word in another cache To prevent this the other processors must be alerted that an update has taken place Typically addressed in hardware rather than the operating system © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + Multiprocessor Operating System Design Considerations Simultaneous concurrent processes OS routines need to be reentrant to allow several processors to execute the same IS code simultaneously OS tables and management structures must be managed properly to avoid deadlock or invalid oper Scheduling Any processor may perform scheduling so conflicts must be avoided Scheduler must assign ready processes to available processors Synchronization With multiple active processes having potential access to shared address spaces or I/O resources, care must be taken to provide effective synchronization Synchronization is a facility that enforces mutual exclusion and event ordering Memory management In addition to dealing with all of the issues found on uniprocessor machines, the OS needs to exploit the available hardware parallelism to achieve the best performance Paging mechanisms on different processors must be coordinated to enforce consistency when several processors share a page or segment and to decide on page replacement Reliability and fault tolerance OS should provide graceful degradation in the face of processor failure Scheduler and other portions of the operating system must recognize the loss of a processor and restructure accordingly + Multithreading and Chip Multiprocessors Processor performance can be measured by the rate at which it executes instructions MIPS rate = f * IPC f = processor clock frequency, in MHz IPC = average instructions per cycle Increase performance by increasing clock frequency and increasing instructions that complete during cycle Multithreading Allows for a high degree of instruction-level parallelism without increasing circuit complexity or power consumption Instruction stream is divided into several smaller streams, known as threads, that can be executed in parallel © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Definitions of Threads and Processes Thread switch • The act of switching processor control between threads within the same process • Typically less costly than process switch Thread: • Dispatchable unit of work within a process • Includes processor context (which includes the program counter and stack pointer) and data area for stack • Executes sequentially and is interruptible so that the processor can turn to another thread Thread in multithreaded processors may or may not be the same as the concept of software threads in a multiprogrammed operating system Thread is concerned with scheduling and execution, whereas a process is concerned with both scheduling/execution and resource and resource ownership Process: • An instance of program running on computer • Two key characteristics: • Resource ownership • Scheduling/execution Process switch • Operation that switches the processor from one process to another by saving all the process control data, registers, and other information for the first and replacing them with the process information for the second © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Implicit and Explicit Multithreading + All commercial processors and most experimental ones use explicit multithreading Concurrently execute instructions from different explicit threads Interleave instructions from different threads on shared pipelines or parallel execution on parallel pipelines Implicit multithreading is concurrent execution of multiple threads extracted from single sequential program Implicit threads defined statically by compiler or dynamically by hardware © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + Approaches to Explicit Multithreading Interleaved Fine-grained Processor deals with two or more thread contexts at a time Switching thread at each clock cycle If thread is blocked it is skipped Simultaneous (SMT) Instructions are simultaneously issued from multiple threads to execution units of superscalar processor © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Blocked Coarse-grained Thread executed until event causes delay Effective on in-order processor Avoids pipeline stall Chip multiprocessing Processor is replicated on a single chip Each processor handles separate threads Advantage is that the available logic area on a chip is used effectively Simultaneous multithreading: Figure 17.7j shows a system capable of issuing 8 instructions at a time. Chip multiprocessor (multicore): Figure 17.7k shows a chip containing four cores, each of which has a twoissue superscalar processor. Each core is assigned a thread, from which it can issue up to two instructions per cycle. A B C D A B A A A A (a) single-threaded scalar A B C D A B (b) interleaved multithreading scalar (c) blocked multithreading scalar ABCD A B B D D D A issu A A A A B B B B C ot e sl ABCD A B C D A B A A A N (g) VLIW ABCD B B B N B N N N C N N N A D D B C A A D D D D B A D D A D B A A A A A D B A A A A D B A A A A D A B N D A N N B N D N N N N N D N N (h) interleaved multithreading VLIW ABCD (i) blocked multithreading VLIW A (d) superscalar A A A A (f) blocked multithreading superscalar A A N N A A N N A A A A N N A N N N latency cycle issue bandwidth (e) interleaved multithreading superscalar A A A A A thread switches ABCD B B A A A thread switches A A A thread switches ABCD thread switches cycles ABCD thread switches The final two approaches illustrated in Figure 17.7 enable the parallel, simultaneousexecution of multiple threads: A thread switches Blocked multithreaded scalar: In this case, a single thread is executed until a latency event occurs that would stop the pipeline, at which time the processor switches to another thread. Superscalar: This is the basic superscalar approach with no multithreading. Interleaved multithreading superscalar: During each cycle, as many instructions as possible are issued from a single thread. Blocked multithreaded superscalar: Again, instructions from only one thread may be issued during any cycle, and blocked multithreading is used Very long instruction word (VLIW): A VLIW architecture, such as IA- 64, places multiple instructions in a single word. Blocked multithreaded VLIW: This approach should provide similar efficiencies to those provided by blocked multithreading on a superscalar architecture ABCD B B B B A D (j) simultaneous multithreading (SMT) C D C B A D A A A B B B B B A A A A B B B C C C C C C D D D D D D D D (k) chip multiprocessor (multicore) Figure 17.7 Approaches to Executing Multiple Threads © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Clusters Alternative to SMP as an approach to providing high performance and high availability Particularly attractive for server applications Defined as: A group of interconnected whole computers working together as a unified computing resource that can create the illusion of being one machine (The term whole computer means a system that can run on its own, apart from the cluster) Each computer in a cluster is called a node + Benefits: Absolute scalability Incremental scalability High availability Superior price/performance © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. P M P I/O P I/O High-speed message link I/O P M I/O (a) Standby server with no shared disk High-speed message link P M P I/O I/O I/O I/O I/O RAID (b) Shared disk Figure 17.8 Cluster Configurations © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. P I/O P M Table 17.2 Clustering Methods: Benefits and Limitations Clustering Method Description Benefits Limitations Passive Standby A secondary server takes over in case of primary server failure. Easy to implement. High cost because the secondary server is unavailable for other processing tasks. Active Secondary: The secondary server is also used for processing tasks. Reduced cost because secondary servers can be used for processing. Increased complexity. Separate Servers Separate servers have their own disks. Data is continuously copied from primary to secondary server. High availability. High network and server overhead due to copying operations. Servers Connected to Disks Servers are cabled to the same disks, but each server owns its disks. If one server fails, its disks are taken over by the other server. Reduced network and server overhead due to elimination of copying operations. Usually requires disk mirroring or RAID technology to compensate for risk of disk failure. Servers Share Disks Multiple servers simultaneously share access to disks. Low network and server overhead. Reduced risk of downtime caused by disk failure. Requires lock manager software. Usually used with disk mirroring or RAID technology. © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Additional blade server racks N 100GbE Eth Switch 100GbE 10GbE & 40GbE Eth Switch Eth Switch Eth Switch Eth Switch Eth Switch Eth Switch Eth Switch Figure 17.10 Example 100-Gbps Ethernet Configuration for Massive Blade Server Cloud Site © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + Clusters Compared to SMP Both provide a configuration with multiple processors to support high demand applications Both solutions are available commercially SMP Easier to manage and configure Much closer to the original single processor model for which nearly all applications are written Less physical space and lower power consumption Well established and stable © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Clustering Far superior in terms of incremental and absolute scalability Superior in terms of availability All components of the system can readily be made highly redundant Essential Characteristics Broad Network Access Rapid Elasticity Measured Service On-Demand Self-Service Resource Pooling Software as a Service (SaaS) Deployment Models Service Models Platform as a Service (PaaS) Infrastructure as a Service (IaaS) Public Private Hybrid Community Figure 17.12 Cloud Computing Elements © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Cloud Application Software (provided by cloud, visible to subscriber) Cloud Application Software (developed by subscriber) Cloud Platform (visible only to provider) Cloud Platform (visible to subscriber) Cloud Infrastructure (visible only to provider) Cloud Infrastructure (visible only to provider) Software as a service (a) SaaS (b) PaaS Platform as a service (PaaS): Cloud Application Software (developed by subscriber) Cloud Platform (visible to subscriber) Cloud Infrastructure (visible to subscriber) (c) IaaS Infrastructure as a service (IaaS): Figure 17.13 Cloud Service Models © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + Deployment Models Public cloud The cloud infrastructure is made available to the general public or a large industry group and is owned by an organization selling cloud services Major advantage is cost Private cloud A cloud infrastructure implemented within the internal IT environment of the organization A key motivation for opting for a private cloud is security © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Community cloud Like a private cloud it is not open to any subscriber Like a public cloud the resources are shared among a number of independent orgaizations Hybrid cloud The cloud infrastructure is a composition of two or more clouds that remain unique entities but are bound together by standardized or proprietary technology that enables data and application portability Sensitive information can be placed in a private area of the cloud and less sensitive data can take advantage of the cost benefits of the public cloud An enterprise maintains workstations within an enterprise LAN or set of LANs, which are connected by a router through a network or the Internet to the cloud service provider. The cloud service provider maintains a massive collection of servers, which it manages with a variety of network management, redundancy, and security tools. Enterprise Cloud User LAN switch Router Network or Internet Router LAN switch Servers Figure 17.14 Cloud Computing Context © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Cloud service provider + Cloud Computing Reference Architecture NIST SP 500-292 establishes a reference architecture, described as: “The NIST cloud computing reference architecture focuses on the requirements of “what” cloud services provide, not a “how to” design solution and implementation. The reference architecture is intended to facilitate the understanding of the operational intricacies in cloud computing. It does not represent the system architecture of a specific cloud computing system; instead it is a tool for describing, discussing, and developing a system-specific architecture using a common framework of reference.” © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Cloud Provider Service Layer SaaS Cloud Auditor Security Audit PaaS Business Support IaaS Resource Abstraction and Control Layer Privacy Impact Audit Physical Resource Layer Performance Audit Facility Cloud Broker Cloud Service Management Provisioning/ Configuration Service Intermediation Privacy Service Orchestration Security Cloud Consumer Service Aggregation Service Arbitrage Portability/ Interoperability Hardware Cloud Carrier Figure 17.15 NIST Cloud Computing Reference Architecture © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Summary + Parallel Processing Chapter 17 Multithreading and chip multiprocessors Multiple processor organizations Types of parallel processor systems Parallel organizations Organization Multiprocessor operating system design considerations Software solutions Hardware solutions The MESI protocol Motivation Organization NUMA Pros and cons Cloud computing © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Cluster configurations Operating system design issues Cluster computer architecture Blade servers Clusters compared to SMP Nonuniform memory access Cache coherence and the MESI protocol Clusters Symmetric multiprocessors Implicit and explicit multithreading Approaches to explicit multithreading Cloud computing elements Cloud computing reference architecture + Chapter 18 Multicore Computers © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Issue logic Program counter Single-thread register file Instruction fetch unit Execution units and queues Hardware performance issues L1 instruction cache L2 cache (a) Superscalar Registers n Regoster 1 PC 1 PC n Issue logic Instruction fetch unit Execution units and queues L1 instruction cache L1 data cache L2 cache Core 3 (superscalar or SMT) L1-I L1-D Core n (superscalar or SMT) Core 2 (superscalar or SMT) L1-I L1-D L1-I L1-D Core 1 (superscalar or SMT) (b) Simultaneous multithreading L1-I L1-D Increase in clock frequency Increase in transistor density Increase in parallelism and complexity Pipelining: more stages Superscalar (Multiple pipelines) Simultaneous multithreading (SMT): Register banks are replicated so that multiple threads can share the use of pipeline resources. Multicore L1 data cache L2 cache (c) Multicore Figure 18.1 Alternative Chip Organizations © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Power requirements have grown exponentially as chip density and Power density (watts/cm2) clock frequency have risen 100 Performance increase is roughly logic proportional to square root of increase in complexity, if you 10 double the logic in a processor core, then it delivers only 40% memory more performance In principle, the use of multiple 1 cores has the potential to provide 0.25 0.18 0.13 0.10 Feature size (µm) near-linear performance + improvement with the increase in the number of cores Figure 18.2 Power and Memory Considerations © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. 0% 8 Software performance issues relative speedup 2% 6 5% 10% 4 2 0 1 2 3 4 5 6 7 8 number of processors (a) Speedup with 0%, 2%, 5%, and 10% sequential portions 2.5 5% 10% 15% 20% 2.0 relative speedup If only 10% of the code is inherently serial (f = 0.9), running the program on a multi- core system with 8 processors yields a performance gain of only a factor of 4.7. 1.5 1.0 0.5 0 1 2 3 4 5 6 7 8 number of processors (b) Speedup with overheads Figure 18.3 Performance Effect of Multiple Cores © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. 64 Oracle DSS 4-way join TMC data mining DB2 DSS scan & aggs Oracle ad hoc insurance OLTP rf ec ts ca l in g 48 pe scaling Database is one area in which multicore systems can be used effectively. Servers can also effectively use the parallel multicore organization, because servers typically handle numerous relatively independent transactions in parallel. 32 16 0 0 16 32 number of CPUs 48 64 Figure 18.4 Scaling of Database Workloads on Multiple-Processor Hardware © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + Effective Applications for Multicore Processors Multi-threaded native applications Multi-process applications Process-level parallelism Characterized by the presence of many single-threaded processes Java applications Thread-level parallelism Characterized by having a small number of highly threaded processes Embrace threading in a fundamental way Java Virtual Machine is a multi-threaded process that provides scheduling and memory management for Java applications Multi-instance applications If multiple application instances require some degree of isolation, virtualization technology can be used to provide each of them with its own separate and secure environment © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Multicore organization Num of cores Num of levels of cache How cache shared? SMT employed? Type of cores CPU Core 1 CPU Core n CPU Core 1 CPU Core n L1-D L1-I L1-D L1-I L1-D L1-I L1-D L1-I L2 cache L2 cache main memory I/O L2 cache I/O main memory (a) Dedicated L1 cache No on-chip cache sharing Embedded chip, ARM11 MPCore CPU Core 1 CPU Core n L1-D L1-I L1-D L1-I L2 cache main memory No on-chip cache sharing , AMD Opteron, from 2005 CPU Core 1 CPU Core n L1-D L1-I L1-D L1-I L2 cache L2 cache L3 cache I/O (c) Shared L2 cache Shared L2 Intel core duo (b) Dedicated L2 cache main memory I/O (d ) Shared L3 cache Shared L3 Intel core i7 Figure 18.6 Multicore Organization Alternatives © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Heterogeneous Multicore Organization Refers to a processor chip that includes more than one kind of core The most prominent trend is the use of both CPUs and graphics processing units (GPUs) on the same chip GPUs are characterized by the ability to support thousands of parallel execution trends Thus, GPUs are well matched to applications that process large amounts of vector and matrix data © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. CPU CPU GPU GPU Cache Cache Cache Cache On-Chip Interconnection Network DRAM Controller LastLevel Cache LastLevel Cache Figure 18.7 Heterogenous Multicore Chip Elements © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. DRAM Controller Table 18.1 Operating Parameters of AMD 5100K Heterogeneous Multicore Processor Clock frequency (GHz) Cores FLOPS/core GFLOPS CPU 3.8 4 8 121.6 FLOPS = floating point operations per second FLOPS/core = number of parallel floating point operations that can be performed © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. GPU 0.8 384 2 614.4 + Heterogeneous System Architecture (HSA) Key features of the HSA approach include: The entire virtual memory space is visible to both CPU and GPU The virtual memory system brings in pages to physical main memory as needed A coherent memory policy ensures that CPU and GPU caches both see an up-to-date view of data A unified programming interface that enables users to exploit the parallel capabilities of the GPUs within programs that rely on CPU execution as well The overall objective is to allow programmers to write applications that exploit the serial power of CPUs and the parallel-processing power of GPUs seamlessly with efficient coordination at the OS and hardware level © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. GIC-400 Global Interrupt Controller Interrupts Cortex-A15 Cortex-A15 Core Core Interrupts Cortex-A7 Core L2 Cortex-A7 Core I/O Coherent Master L2 CCI-400 (Cache Coherent Interconnect) Memory Controller Ports System Port The A7 cores handle less computation-intense tasks, such as background processing, playing music, sending texts, and making phone calls. The A15 cores are invoked for high intensity tasks, such as for video, gaming, and navigation. Typically, only one "side" or the other will be active at once Figure 18.9 Big.Litte Chip Components © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Core 0 Core 1 Core 2 Core 3 Core 4 Core 5 32 kB 32 kB L1-I L1-D 32 kB 32 kB L1-I L1-D 32 kB 32 kB L1-I L1-D 32 kB 32 kB L1-I L1-D 32 kB 32 kB L1-I L1-D 32 kB 32 kB L1-I L1-D 256 kB L2 Cache 256 kB L2 Cache 256 kB L2 Cache 256 kB L2 Cache 256 kB L2 Cache 256 kB L2 Cache 12 MB L3 Cache DDR3 Memory Controllers 3 8B @ 1.33 GT/s 24B*1.33=32GB/s QuickPath Interconnect 4 20b @ 6.4 GT/s One transfer 16 bits; 2B*6.4Gtransfer/s=12.8 GB/s Bidirection: 2*12.8 = 25.6 GB/s Figure 18.13 Intel Core i7-990X Block Diagram © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Summary + Multicore Computers Chapter 18 Multicore organization Levels of cache Simultaneous multithreading Heterogeneous multicore organization Hardware performance issues Increase in parallelism and complexity Power consumption Software performance issues Software on multicore Valve game software example Intel Core i7-990X IBM zEnterprise EC12 mainframe Different instruction set architectures Equivalent instruction set architectures Cache coherence and the MOESI model ARM Cortex-A15 MPCore Organization Cache structure © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Interrupt handling Cache coherency L2 cache coherency + Chapter 19 General-Purpose Graphic Processing Units © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. + Compute Unified Device Architecture (CUDA) A parallel computing platform and programming model created by NVIDIA and implemented by the graphics processing units (GPUs) that they produce CUDA C is a C/C++ based language Program can be divided into three general sections The data-parallel code to be run on the GPU is called a kernel Code to be run on the host (CPU) Code to be run on the device (GPU) The code related to the transfer of data between the host and the device Typically will have few to no branching statements Branching statements in the kernel result in serial execution of the threads in the GPU hardware A thread is a single instance of the kernel function The programmer defines the number of threads launched when the kernel function is called The total number of threads defined is typically in the thousands to maximize the utilization of the GPU processor cores, as well as maximize the available speedup The programmer specifies how these threads are to be bundled © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Grid Block(0, 0) Block(1, 0) Block(2, 0) Block(0, 1) Block(1, 1) Block(2, 1) Block (1,1) Thread (0, 0) Thread (1, 0) Thread (2, 0) Thread (3, 0) Thread (0, 1) Thread (1, 1) Thread (2, 1) Thread (3, 1) Thread (0, 2) Thread (1, 2) Thread (2, 2) Thread (3, 2) Figure 19.1 Relationship Among Threads, Blocks, and a Grid © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Control ALU ALU ALU ALU Cache DRAM DRAM CPU GPU control logic and cache memory make up the A massively parallel SIMD (single instruction majority of the CPU’s real estate. process multiple data) architecture to perform mainly sequential code mathematical operations. Less complex control and cache. Figure 19.2 CPU vs. GPU Silicon Area/Transistor Dedication © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Theoretical GFLOPS 5500 5000 4500 NVIDIA GPU Single Precision NVIDIA GPU Double Precision Intel CPU Single Precision Intel CPU Double Precision 4000 3500 3000 2500 2000 1500 1000 500 Sep-02 Jan-04 May-05 Oct-06 Feb-08 Jul-09 Nov-10 Apr-12 Aug-13 Figure 19.3 Floating-Point Operations per Second for CPU and GPU © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. GPU Architecture Overview The historical evolution can be divided up into three major phases: The first phase would cover early 1980s to late 1990s, where the GPU was composed of fixed, nonprogrammable, specialized processing stages The second phase would cover the iterative modification of the resulting Phase I GPU architecture from a fixed, specialized, hardware pipeline to a fully programmable processor (early to mid-2000s) The third phase covers how the GPU/GPGPU architecture makes an excellent and affordable highly parallelized SIMD coprocessor for accelerating the run times of some nongraphics-related programs, along with how a GPGPU language maps to this architecture © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. DRAM: 6*64bit =384-bit interface to the GPU’s GDDR5 (graphic double data rate, a DDR memory designed specifically for graphic processing) DRAM host interface allows for PCIe connectivity between the GPU and the CPU the GigaThread global scheduler unit on the GPU chip distributes the thread blocks to the SMs. DRAM Host Interface DRAM DRAM DRAM GigaThread L2 Cache DRAM DRAM © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Figure 19.4 NVIDIA Fermi Architecture Instruction Cache Warp Scheduler Warp Scheduler Dispatch Unit Dispatch Unit ■ GPU processor cores (total of 32 CUDA cores) Core ■ Warp scheduler and dispatch port CUDA Core ■ Sixteen load/store units ■ Four SFUs Dispatch Port Operand Collector FP Unit Register File (32k x 32-bit) Int Unit Result Queue ■ 32k * 32-bit registers © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core Core ■ Shared memory and L1 cache (64 kB in total) Core Core Core Core Ld/St Ld/St Ld/St Ld/St Ld/St Ld/St Ld/St Ld/St Ld/St Ld/St SFU Ld/St Ld/St Ld/St Ld/St Ld/St 64-kB Shared Memory/L1 Cache Figure 19.5 Single SM Architecture SFU Ld/St Interconnect Network Uniform Cache SFU SFU The dual warp scheduler will then break up each thread block it is processing into warps A warp is a bundle of 32 threads that start at the same starting address and their thread IDs are consecutive. Once a warp is issued, each thread will have its own instruction address counter and register set. This allows for independent branching and execution of each thread in the SM. WARP Scheduler Instruction Dispatch Unit Instruction Dispatch Unit Warp 8 instruction 11 Warp 9 instruction 11 Warp 2 instruction 42 Warp 3 instruction 33 Warp 14 instruction 95 Warp 15 instruction 95 Warp 8 instruction 12 Warp 9 instruction 12 Warp 14 instruction 96 Warp 3 instruction 34 Warp 2 instruction 43 Warp 15 instruction 96 Time WARP Scheduler © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Figure 19.6 Dual Warp Schedulers and Instruction Dispatch Units Run Example + CUDA Cores The NVIDIA GPU processor cores are also known as CUDA cores There are a total of 32 CUDA cores dedicated to each SM in the Fermi architecture Each CUDA core has two separate pipelines or data paths An integer (INT) unit pipeline Is capable of 32-bit, 64-bit, and extended precision for integer and logic/bitwise operations Floating-point (FP) unit pipeline Can perform a single-precision FP operation, while a double-precision FP operation requires two CUDA cores © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Table 19.2 GPU’s Memory Hierarchy Attributes Memory Type Registers Shared Relative Access Times Fastest. On-chip Fast. On-chip Local 100´ to 150´ slower than shared & register. Off-chip 100´ to 150´ slower than shared & register. Off-chip. 100´ to 150´ slower than shared & register. Off-chip 100´ to 150´ slower than shared & register. Off-chip Global Constant Texture © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. Access Scope Type R/W Single thread R/W All threads in a block R/W Single thread Data Lifetime Thread Block R/W All threads & host Application R All threads & host Application R All threads & host Application Thread Summary + Chapter 19 CUDA basics GPU versus CPU Basic differences between CPU and GPU architectures Performance and performance per watt comparison Intel’s Gen8 GPU © 2016 Pearson Education, Inc., Hoboken, NJ. All rights reserved. General-Purpose Graphic Processing Units GPU architecture overview Baseline GPU architecture Full chip layout Streaming multiprocessor architecture details Importance of knowing and programming to your memory types