Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
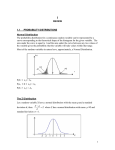
ENGG2450 Probability and Statistics for Engineers 1 Introduction 3 Probabilityy 4 Probability distributions 5 Probability Densities 2 Organization and description of data 6 Sampling distributions 7 Inferences concerning a mean 8 C Comparing two treatments 9 Inferences concerning variances A Random Processes 6 Sampling distributions 6.2 The sample distribution of the mean (σ known) 6 3 Th 6.3 The sample l distribution di t ib ti off the mean (σ unknown) 6.4 The sampling distribution of the variance 1 Introduction 3 Probability 4 Probability distributions 5 Probability densities 2 Organization & description 6 Sampling distributions 7 Inferences .. mean 8 Comparing 2 treatments 9 Inferences .. variances A Random processes (revision: 2.1 Populations and samples) (3) Random Samples (finite population) A set of observations X1, X2, …, Xn constitutes a random sample of size n from a finite population of size N, if its values are chosen so that each subset of n of the N elements of the population has the same probability of being selected. e.g. N= 100, n= 4 X1 , X2 , X3 , X4 , X5 ,X6 , X7 , X8 , X9 , X10 , X11 ,X X12, X13 , X14 , X15 , X16 , …. X99, X100 The upper case represents the random variables before they are observed. (revision: 2.1 Populations and samples) (4) Random Samples (finite population) A set of observations X1, X2, …, Xn constitutes a random sample of size n from a finite population of size N, if its values are chosen so that each subset of n of the N elements of the population has the same probability of being selected. e.g. N= 100, n= 4 x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 , x16 , …… x99, x100 We may also apply the term random sample to x1, x2, …, xn which is the set of observed values of the random variables X1, X2, …, Xn . (revision: 2.1 Populations and samples) (5) Random Samples (infinite population) A set of observations X1, size X2, …, Xn constitutes a random sample of n from the infinite population f(x) if Xi is a random variable whose distribution is ggiven byy f( f(x). ) 2. These n random variables are independent. 1. Each X1 , X2 , X3 , X4 , X5 ,X6 , X7 , X8 , X9 , X10 , X11 ,X X12, X13 , X14 , X15 , X16 , …. X99, X100, … … , X1001, X1002, X1003, X1004, … … … … … … … The upper case represents the random variables before they are observed. We may also apply the term random sample to the set of observed values x1, x2, …, xn of the random variables. x x1 , x2 , x3 , x4 , x5 , x6 , x x , x ,x , x 7 8 9 10 , x11 , x12 , x13 , x14 , x15 x x16 , x17 , x18 , x19 , x20 , x21 , x22, x23, x24. e.g. (a) How many different samples of size n=2 can be chosen from a finite population of size N=7? (b) Repeat (a) with N N=24 24. (c) What is the probability of each sample in part (a) if the samples are to be random? (d) Repeat (c) with N=24. A set of observations X1, X2, …, Xn constitutes a random sample of size n from a finite p population p of size N, if its values are chosen so that each subset of n of the N elements of the population has the same probability of being selected. sln. l (a) The number of possible samples = C7,2 = 7x6 / 2 = 21 (b) The n number mber of possible samples = C24,2 = 24x23 / 2 = 276 (c) The probability of each sample in part (a) is 1/21. (d) The probability of each sample in part (b) is 1/276. 6.2 The sample distribution of the mean ( known) (7) A set of observations X1, X2, …, Xn constitutes a random sample of size n from the infinite population f(x) if each Xi is a random variable whose distribution is given by f(x) and these n random variables are independent. A random sample of n (say 10) observations is taken from some population. The mean of the sample is computed to estimate the mean of the population. population x x1 , x2 , x3 , x4 , x x , x , x ,x ,x , x 5 6 7 8 9 10 , x11 , x12 , x13 , x14 x , x 15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , …… Suppose pp 50 random samples p of size n=10 are taken from a p population p having the discrete uniform distribution f(x) = 0.1 for x=0,1,2,…, 9 and f(x) = 0 for other values of x. Sampling is with replacement and we are sampling from an infinite population. go to slide 2 (continued) Suppose 50 random samples of size n=10 are taken from a population having the discrete uniform distribution f(x) = 0.1 for x=0,1,2,…, 9 and f(x) = 0 for other values of x. x x1 , x2 , x3 , x4 , x x , x , x ,x ,x , x 5 6 8 7 9 10 , x11 , x12 , x13 , x14 x , x 15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. Proceeding in this way, we get 50 samples whose means are 4.44 4 3.1 3.0 53 5.3 3.6 3.2 32 5.3 3.0 5.5 55 2.7 55.00 3.8 4.6 44.88 4.0 33.55 4.3 5.8 66.44 5.0 44.1 1 3.3 4.6 44.9 9 2.6 44.4 4 5.0 4.0 66.5 5 4.2 33.6 6 4.9 3.7 33.5 5 4.4 66.5 5 4.8 5.2 44.5 5 5.6 55.3 3 3.1 3.7 44.9 9 4.7 44.4 4 5.3 3.8 55.3 3 4.3 The population Th l ti has h the th di discrete t uniform distribution but the means of the 50 random samples has a bell-shaped distribution. Why? means Frequency [ 2.0 , 3.0 ) [[ 3.0 , 4.0 ) , ) [ 4.0 , 5.0 ) [ 5.0 , 6.0 ) [ 6.0 , 7.0 ) Total 2 14 19 12 3 50 (continued) The population has the discrete uniform distribution but the means of the 50 random samples has a bell-shaped distribution. Why? x x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. To answer this kind of question, we need to investigate the theoretical sampling distribution of the sample mean X F Formulas l for f X and d X2 X 1 .. X n . n Theorem 1: If a random sample of size n is taken from a population ha ing the mean and the variance having ariance 2, then (a) X is a random variable whose distribution has the mean , (b) for samples from infinite populations populations, 2 , the variance of this distribution is n (c) for samples from finite populations, finite population 2 N n correction factor . . the variance of this distribution is n N 1 x x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. Theorem 1(a): Iff a random sample off size n is taken from f a population having the mean and the variance 2, then note: x is an outcome of random variable X X 1 .. X n n representing ti the th sample mean. X is a random variable which has the mean X . Pf: The mean of the sample mean is n xi X ... f ( x1 ,x2 ,..., xn ) dx1 dx2 ...dxn n i 1 n 1 ... xi f ( x1 ) f (x2 ))... f ( xn ) dx1 dx2 ...dxn n i 1 1 ... x1 x2 ... xn f ( x1 )... f ( xn ) dx1 dx2 ...dxn n note: random variables X1, .., Xn have joint pdf f(x1,..,xn). note: x1,.., xn are dummy variables representing outcomes of X1, X2, …, Xn . (continue) Pf : The mean of the sample mean is X n i 1 ... xi f ( x1 ,x2 ,..., xn ) dx1 dx2 ...dxn n 1 X ... x1 x2 ... xn f ( x1 )... f ( xn ) dx1 dx2 ...dxn n 1 1 ... x1 f (x1) f (x2 )...f (xn ) dx1 dx2...dxn ... x2 f (x1) f (x2 )...f (xn ) dx1 dx2...dxn ... n n 1 x1 f ( x1 )dx1 f ( x2 )dx2 ... f ( xn ) dxn n 1 f ( x1 ) dx1 x2 f ( x2 )dx2 f ( x3 ) dx3 ... f ( xn ) dxn n ... 1 f ( x1 ) dx1 f ( x2 )dx2 ... f ( xn1 ) dxn1 xn f ( xn ) dxn n n n ... n = the population mean. x e.g. n=10 x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. Theorem 1(b): Th 1(b) If a random d sample l off size i n is i ttaken k ffrom a population l ti 2, then X is a random having the mean and the variance 2 . variable of the variance n Pf: Without loss of generality, we assume =0 and so X2 2 ... x f ( x1 , x2 ,..., xn ) dx1 dx2 ...dxn xi where x i 1 n n 2 2 1 X2 2 n n i 1 1 n2 n 2 x xi x j i 1 i ( x1 ... x n ) ( x1 ... x n ) i j 2 2 n n 2 ... x i f ( x1 , x2 ,..., xn ) dx1 dx2 ...dxn ... x x i j i j f ( x1 , x2 ,..., xn ) dx1 dx2 ...dxn x e.g. n=10 x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. (continue) Pf : 1 n X2 2 i 1 ... xi2 f ( x1 , x2 ,..., xn ) dx1 dx2 ...dxn n 1 ... xi x j f ( x1 , x2 ,..., xn ) dx d 1 dx d 2 ...dx d n 2 n i j Variance 2 E[( X ) 2 ] 1 n 2 2 i 1 ... xi f ( x1 ) f ( x2 ) f ( xn ) dx1 dx2 ...dxn 2 n ( x ) f ( x) dx 1 ... xi x j f ( x1 ) f ( x2 ) f ( xn ) dx d 1 dx d 2 ...dx d n 2 n i j 1 2 n 1 2 n n i 1 n 2 x i f ( xi ) dxi 2 i 1 2 n 1 n2 x i j i f ( xi ) dxi x j f ( x j )dx j e.g. n=10 x x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. Theorem 1: If a random sample of size n is taken from a population having the mean and the variance 2, then (a) X is a random variable whose distribution has the mean , (b) for samples from infinite populations, 2 , the variance of this distribution is n f(x) Chebyshev’s Theorem: 1 k P| X | 2. n k k 1 P| X | 1 2 . n k X X1 .. Xn n k /n k /n e.g. n=10 x x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. Theorem 1: If a random sample of size n is taken from a population having the mean and the variance 2, then (a) X is a random variable whose distribution has the mean , (b) for samples from infinite populations, 2 , the variance of this distribution is n f(x) Chebyshev’s Theorem: 1 k PP|X | | X | 11 2 .2 n nk 2 . X X1 .. Xn n For any given >0, the probability P| X | can be made arbitrarily close to 1 by choosing n sufficiently large. k /n = k /n = e.g. n=10 x x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. Law of large numbers Theorem 2: Let X1 , X2 , …, Xn be independent random variables each having the same mean and variance 2. Then P(| X - | ) 0 as n As the sample size increases, unboundedly, the probability that the sample mean differs from the population mean , by more than arbitrary amount , converges to zero. Chebyshev’s Theorem: 2 P| X | 1 2 . n X X1 .. Xn n For any y given g >0,, the probability p y P| X | can be made arbitrarily close to 1 by choosing n sufficiently large. f(x) k /n = k /n = e.g. n=10 x x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. X1, X2, …, Xn are random variables. X = ( X1 + .. + Xn )/n , called the sample mean, is a random variable. e g Consider an experiment where a specified event A has probability e.g. p of occurring. Suppose that, when the experiment is repeated n times, outcomes from different trials are independent. Show that number of times A occurs in n trials A = n becomes arbitrary close to p, with arbitrarily high probability, as the relative frequency of number of times the experiment is repeated grows unboundedly. Sln. We can define n random variables X1 , X2 , …, Xn where Xi =1 if A occurs on the i th trial and Xi =0 otherwise. X1 + X2 +.. + Xn is the number of times that event Random variable A occurs in n trials. X =( X1 + X2 +.. + Xn )/n is the relative frequency of A. e.g. Consider an experiment where a specified event A has probability p of occurring. Suppose that, when the experiment is repeated n times, outcomes from different trials are independent. Show that number of times A occurs in n trials relative frequency of A = n becomes arbitrary close to p, which arbitrarily high probability, as the number of times the experiment i iis repeated d grows unboundedly. b d dl (continued) Sln. We can define n random variables X1 , X2 , …, Xn where Xi =11 if A occurs on the i th trial and Xi =00 otherwise. otherwise Then X1 + X2 + …+ Xn is the number of times that event A occurs in n trials of the experiment and X , the sample mean, is the relative frequency of A. E[Xi ] = = 1 p + 0 (1- p) = p E[[Xi2 ] = 12 p + 02 ((1- p) = p k' x f ( x) k all x The Xi are independent and identically distributed with mean = p and variance 2 = E[Xi2 ] – p(1- p). e.g. Consider an experiment where a specified event A has probability p of occurring. Suppose that, when the experiment is repeated n times, outcomes from different trials are independent. Show that number of times A occurs in n trials relative frequency of A = n becomes arbitrary close to p, which arbitrarily high probability, as the number of times the i iis repeated d grows unboundedly. b d dl experiment (continued) Sln. X1 + X2 + …+ Xn is the number of times that event A occurs in n trials of the experiment. X , the sample mean, is the relative frequency of A in n trials. Theorem 2 (Law of large number): Let X1 , X2 , …, Xn be independent random variables each having the same mean and variance 2. Then as the sample size n increases, unboundedly, the probability that the sample mean differs from the population mean which is equal to p), ) by more than arbitrary amount , converges to zero, i.e. P(| X - | ) 0 as n . (sample size n increases) sample l mean = relative frequency of A in n trials population l ti mean =p x e.g. n=10 x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. Theorem 1(b): If a random sample of size n is taken from a population having the mean and the variance 2, then the sample mean of the variance 2 n X is a random variable . The reliability of the sample mean as an estimate of the population mean i often is ft measured db by th the standard t d d deviation d i ti off the th mean which is also called standard error of the mean. X n e.g. Suppose 50 random samples of size n=10 are taken from a population having the di discrete t uniform if di distribution t ib ti f( ) = 0.1 f(x) 0 1 for f x=0,1,2,…, 9 and f(x) = 0 for other values of x. xx n x i 1 i 50 4.428 s x2 n 2 x x ( ) i x i 1 50 0.9298 50 samples whose means are 4.4 31 3.1 3.0 5.3 3.6 3.2 55.3 3 3.0 5.5 2.7 5.0 3.8 38 4.6 4.8 4.0 3.5 44.3 3 5.8 6.4 5.0 4.1 3.3 33 4.6 4.9 2.6 4.4 5.0 50 4.0 6.5 4.2 3.6 4.9 49 3.7 3.5 4.4 6.5 4.8 48 5.2 4.5 5.6 5.3 3.1 31 3.7 4.9 4.7 4.4 5.3 53 3.8 5.3 4.3 x e.g. n=10 x x x1 , x2 , x3 , x4 , x5 , x6 , x7 , x8 , x9 , x10 , x11 , x12 , x13 , x14 , x15 x16 , x17 , x18 , x19 , x20 , x21 , …, x99, x100 , x101, x102 , x103, x104, x105 , .. Suppose S ppose 50 random samples of si size e n=10 10 are taken from a population having the discrete uniform distribution f(x) = 0.1 for x=0,1,2,…, 9 and f(x) = 0 for other values of x. 9 x x 0 1 4.5 10 1 2 ( x )2 f ( x) ( x )2 8.25 10 x 0 x 0 9 9 By Theorem 1, the mean and variance of the sample mean X are respectively Theorem 1: If a random sample of size n is taken from an infinite population having the mean and the variance 2, then the sample mean X has mean , and variance 2/n. 50 samples whose means are 4.4 3.1 30 3.0 5.3 3.6 X = 4.5 45 X2 n = 0.825 2 xx 3.2 5.3 33.0 0 5.5 2.7 5.0 3.8 44.6 6 4.8 4.0 x i 1 i 50 4.1 3.3 44.6 6 4.9 2.6 4.4 5.0 44.0 0 6.5 4.2 3.6 4.9 33.7 7 3.5 4.4 6.5 4.8 55.2 2 4.5 5.6 5.3 3.1 33.7 7 4.9 4.7 4.4 5.3 33.8 8 5.3 4.3 4.428 2 ( x x ) x sx2 i 1 i 0.9298 50 49 n These theoretical values are close to those computed from the 50 samples. n 3.5 4.3 55.8 8 6.4 5.0 Central Limit Theorem Theorem3: If X is the mean of a random sample of size n is taken from a population having the mean and the variance 2, then Z X - n is a random variable whose distribution approaches that of the standard normal distributions as n. X1, X2 , …, Xn are independent random variables with p.d.f. px1, px2 , … , pxn respectively For Y = X1 + X2 + … + Xn , the p.d.f. respectively. p d f of Y is py(y) = px1 px2 … pxn where is convolution. Central Limit Theorem Theorm: If n is very large, then for all pxi the p.d.f. of Y equals 1 e lim p y ( y ) n σ 2π where ( y )2 2σ 2 1 2 ... n 2 12 22 ... n2





























![1 STAT 370: Probability and Statistics for y Engineers [Section 002]](http://s1.studyres.com/store/data/004155539_1-650e86b03c31606d282c23de5ae2b689-150x150.png)


